Bayes’ Theorem For Distributions
Contents
Bayes’ Theorem For Distributions#
So far we have been applying Bayes’ Theorem to random variables.
For example, we’ve looked at the cookie problem, where we studied:

Now, it’s useful to think about random variables in terms of their distributions.
Today we’ll shift our focus to applying Bayes’ Theorem to the distributions themselves.
Review of Distributions#
As you will recall, a distribution is a set of possible outcomes and their corresponding probabilities.
The probability mass function (or PMF) is the probability of each discrete outcome.
We looked at some examples of distributions before, for example, the Binomial Distribution and the Uniform Distribution:
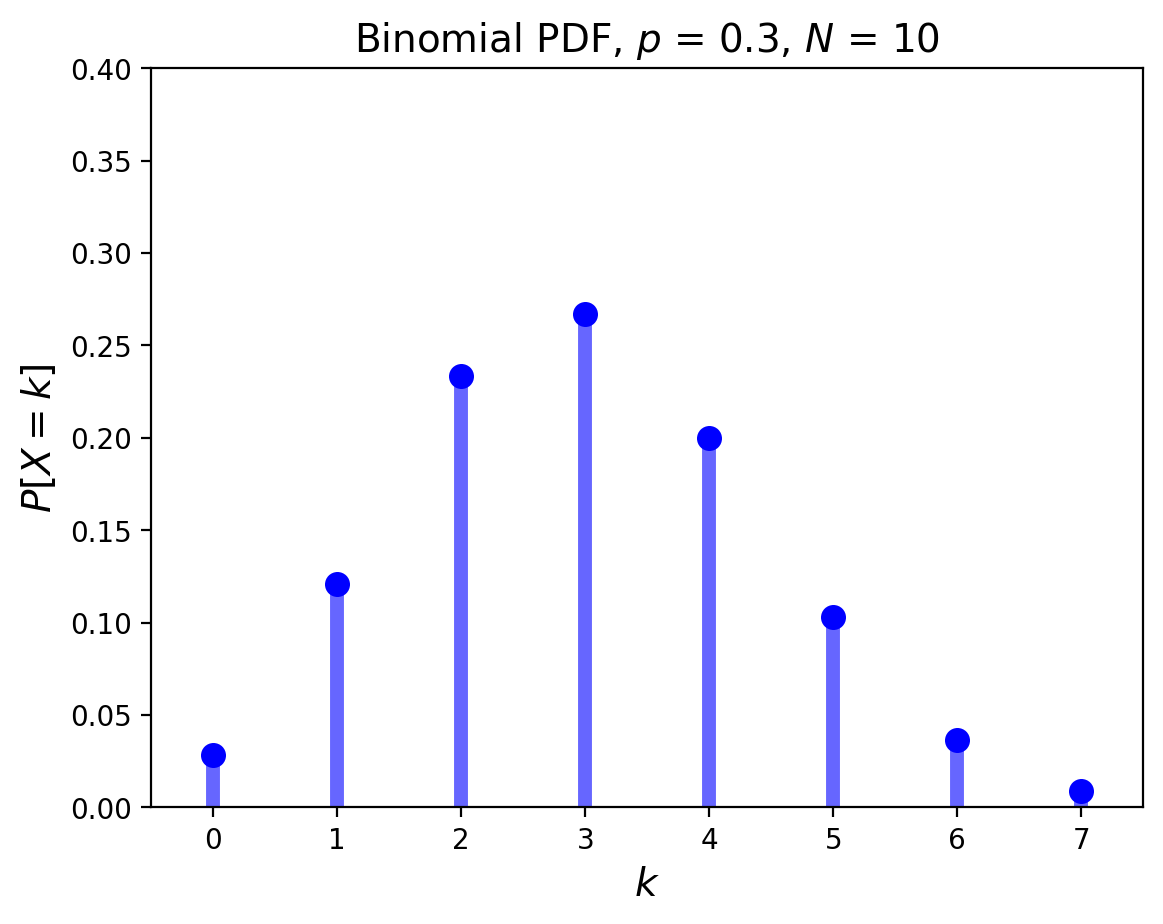
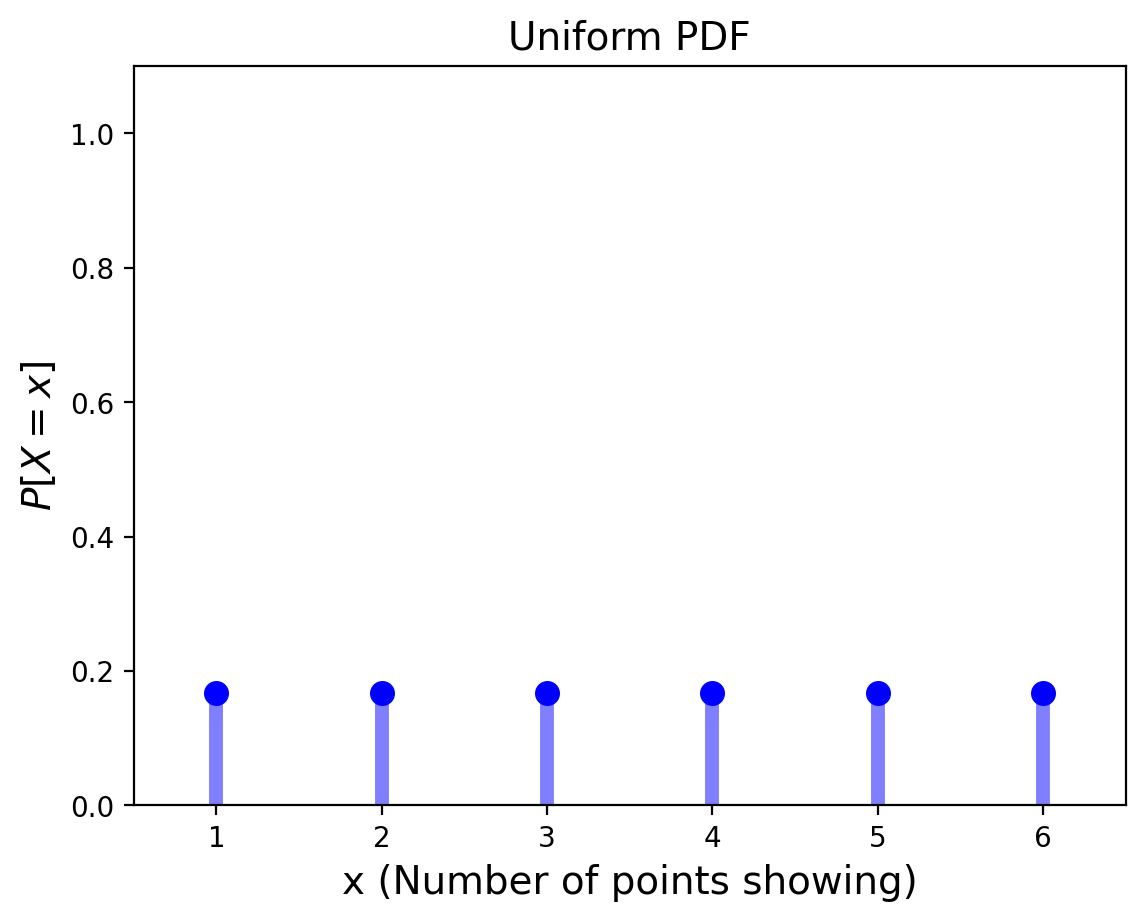
If you think back to the Bayes tables from the previous lectures, this may actually seem very familiar to you.
The priors in our table were a distribution!
Prior and Posterior Distributions#
The set of prior probabilities are in reality a prior distribution.
Likewise, the set of posterior probabilities are in reality a posterior distribution across hypotheses.
Let’s reformulate the cookie problem using distributions.
We’re going to use a uniform probability distribution as a prior (a “uniform prior”):
from scipy.stats import randint
distribution = pd.DataFrame(index=['first bowl', 'second bowl'])
#uniform prior distribution
distribution['probs'] = randint(1, 3).pmf(np.arange(1,3))
distribution
| probs | |
|---|---|
| first bowl | 0.5 |
| second bowl | 0.5 |
In other words:
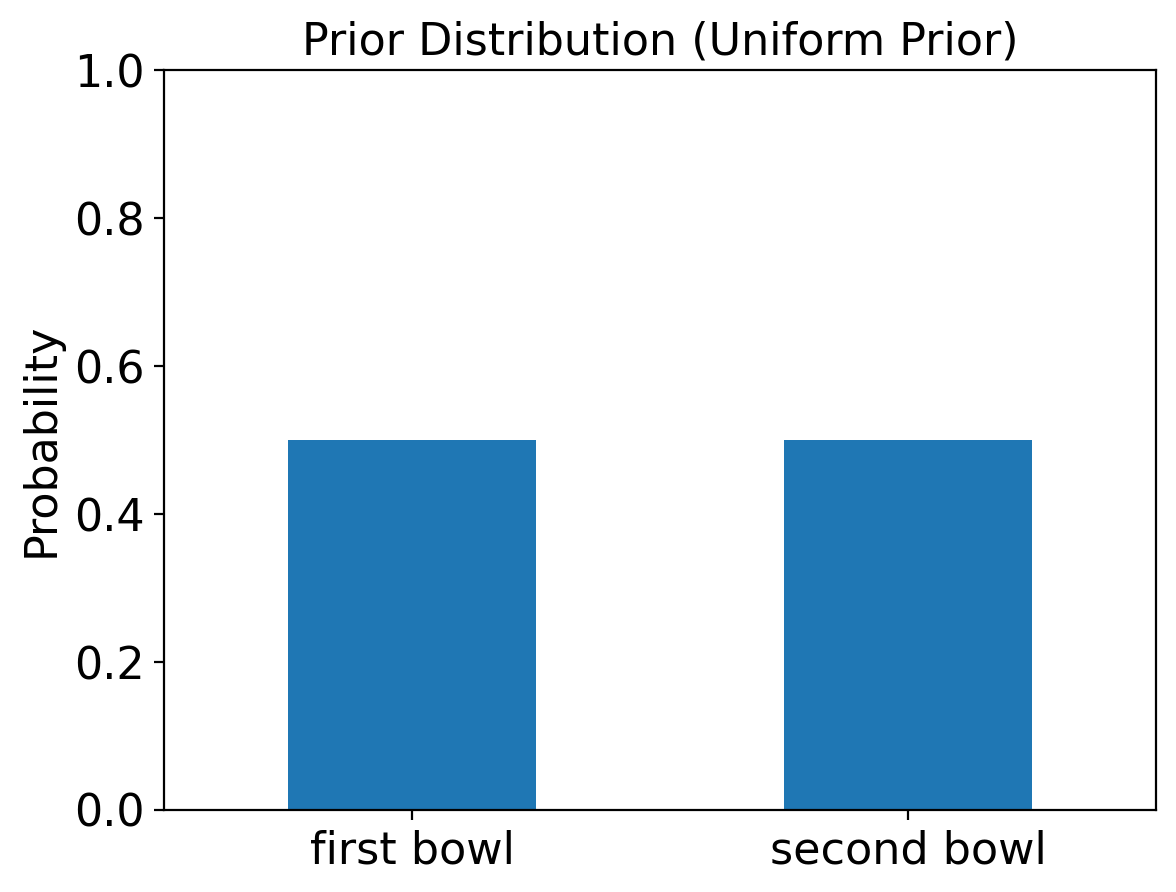
We see that this gives us the exact same prior probabilities as before.
Now let’s introduce an update function like before, but this time it updates our probability distribution based on likelihoods:
def update(distribution, likelihood):
'''perform a Bayesian update on distribution using likelihood'''
distribution['probs'] = distribution['probs'] * likelihood
prob_data = distribution['probs'].sum()
distribution['probs'] = distribution['probs'] / prob_data
return distribution
Let’s see what the posterior pobabilities of both bowls are if we draw a vanilla cookie.
We write the calculation like this:
This of this as updating the distribution from \(P(H)\) to \(P(H\,\vert\,D).\)
And we compute it like this:
likelihood_vanilla = [0.75, 0.5]
update(distribution, likelihood_vanilla)
| probs | |
|---|---|
| first bowl | 0.6 |
| second bowl | 0.4 |
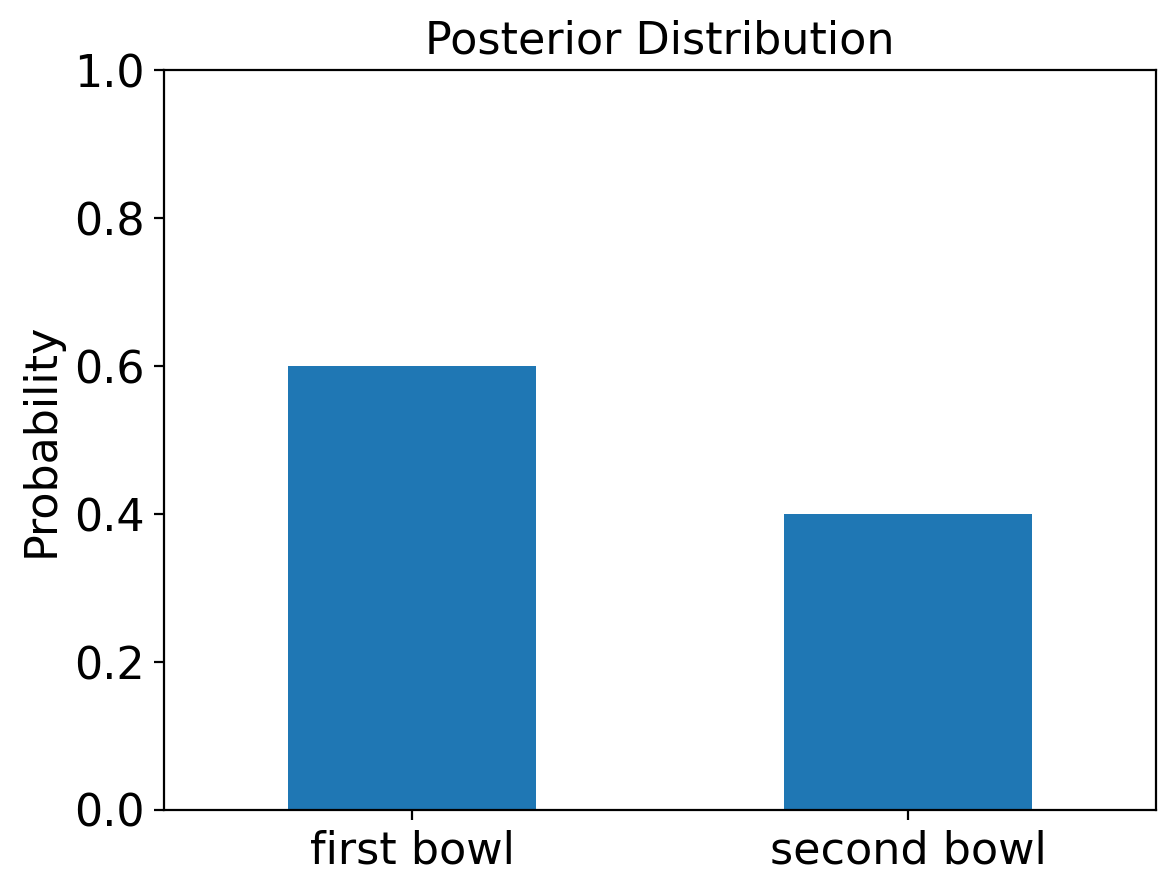
This is our posterior distribution! As you would expect, it’s the same as what we caculated using the Bayes table in our past lecture.
Gathering More Data#
One of the powerful ideas in Bayesian analysis is that if data is arriving over time, you can keep doing Bayesian updates.
Or in a different setting, you can decide to collect more data, and do another Bayesian update.

For example, imagine you are watching a basketball game. You want to estimate the probability of your favorite team winning.
Each time the score changes, you can do another Bayesian update!
Let’s see how this works for the cookie problem.
Let’s say we put the cookie back, and then pull another cookie from the same bowl.
Assume it turns out that it’s vanilla again.
We perform another Bayesian update. (Note that the old posteriors now become the new priors!)
update(distribution, likelihood_vanilla)
| probs | |
|---|---|
| first bowl | 0.692308 |
| second bowl | 0.307692 |
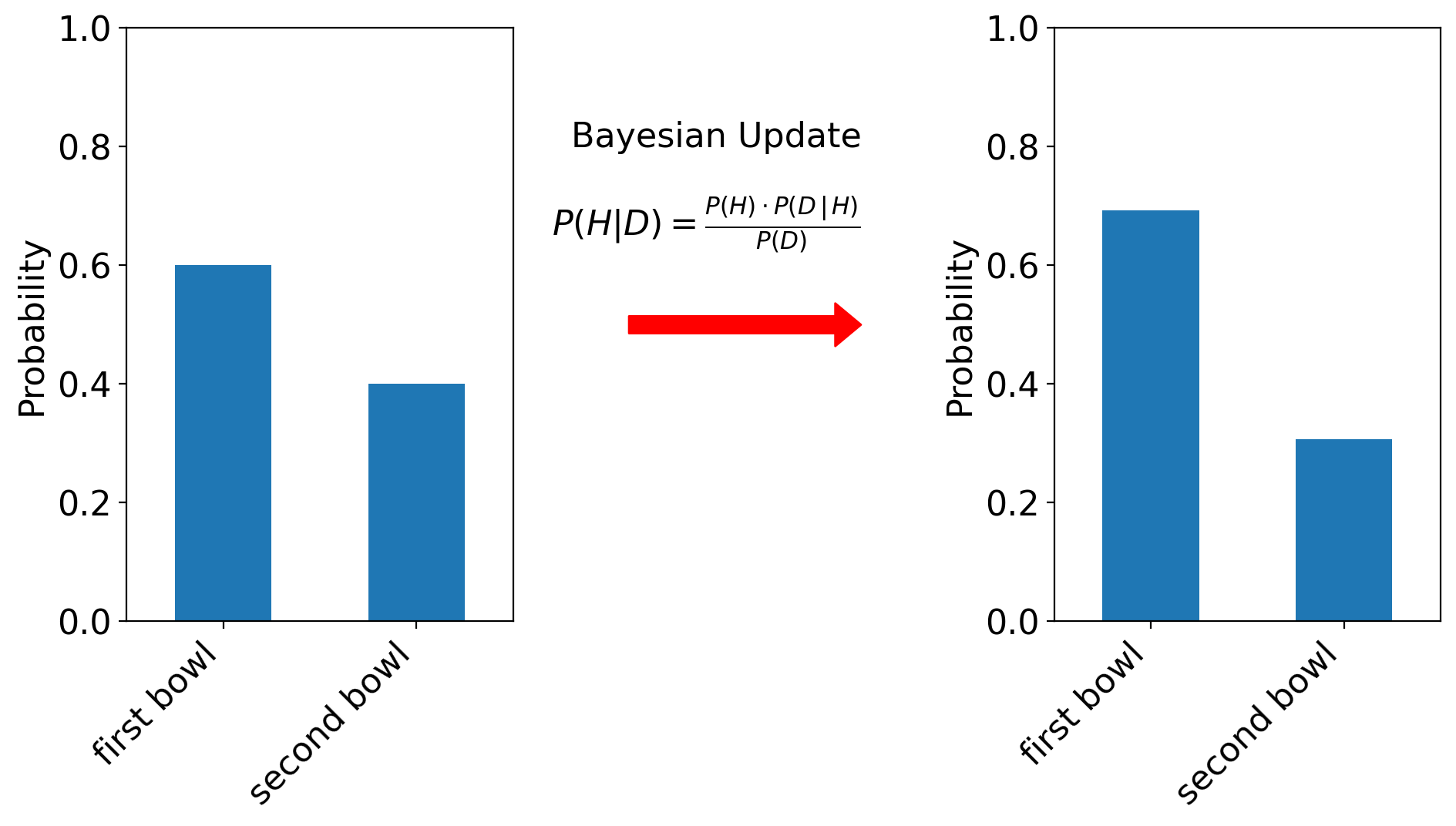
Now we’re even more confident that we are drawing cookies from the first bowl!
101 Bowls#
As we move to more complicated problems, the usefulness of reframing of the prior and posterior as distributions will become more clear.
Let’s suppose we were dealing with 101 bowls instead of just 2. Like before, we’ll say there’s an equal probability of picking each bowl.
This time let’s say that each bowl’s number is in fact the percent of its cookies that are vanilla.
So Bowl 0 is all chocolate, Bowl 1 is 1% vanilla cookies and 99% chocolate, Bowl 2 is 2% vanilla cookes and 98% chocolate, etc.
Getting started on this problem using a uniform prior distribution is no harder than it was for two bowls:
dist_101 = pd.DataFrame(index = np.arange(101))
# using a uniform prior distribution
dist_101['probs'] = randint(0, 101).pmf(np.arange(101))
dist_101
| probs | |
|---|---|
| 0 | 0.009901 |
| 1 | 0.009901 |
| 2 | 0.009901 |
| 3 | 0.009901 |
| 4 | 0.009901 |
| ... | ... |
| 96 | 0.009901 |
| 97 | 0.009901 |
| 98 | 0.009901 |
| 99 | 0.009901 |
| 100 | 0.009901 |
101 rows × 1 columns
The likelihood of drawing a vanilla cookie from each bowl is given by the bowl number:
likelihood_vanilla = np.arange(101)/100
And just as before, we perform a Bayesian update by multiplying the priors by the likelihoods, then normalizing:
That is:
priors = dist_101.copy()
update(dist_101, likelihood_vanilla)
| probs | |
|---|---|
| 0 | 0.000000 |
| 1 | 0.000198 |
| 2 | 0.000396 |
| 3 | 0.000594 |
| 4 | 0.000792 |
| ... | ... |
| 96 | 0.019010 |
| 97 | 0.019208 |
| 98 | 0.019406 |
| 99 | 0.019604 |
| 100 | 0.019802 |
101 rows × 1 columns
This gives us the posterior distribution of probabilities across bowls.
That’s a lot of probabilites to look at though, so lets plot the prior (in gray) and posterior (in blue) distributions:
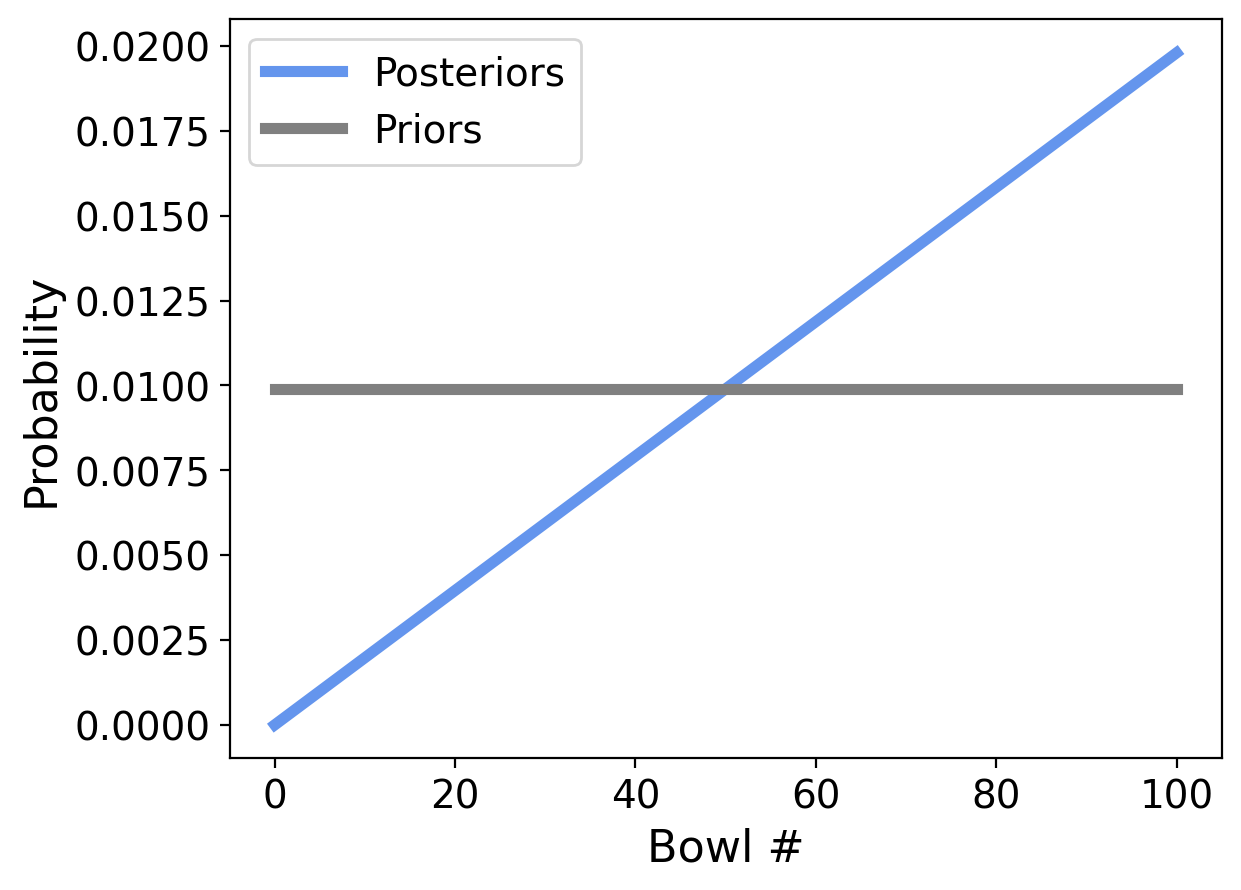
This gives us a good way to understand the prior and posterior distributions.
The prior was uniform, and as we can see, each bowl has an equal probability of being our chosen bowl.
The posterior probability increases with bowl number, which is what we would expect since each higher bowl number has a higher percentage of vanilla cookies.
We can see that the probability we drew our cookie from Bowl 1 is very small – almost zero.
And the most likely Bowl is Bowl 100, which makes sense since that bowl is 100% Vanilla cookies.
What happens if we draw another vanilla cookie out of the same bowl?
The answer is obtained by simply performing another Bayesian update.
Let’s update the probabilities and plot the new posterior:
update(dist_101, likelihood_vanilla);
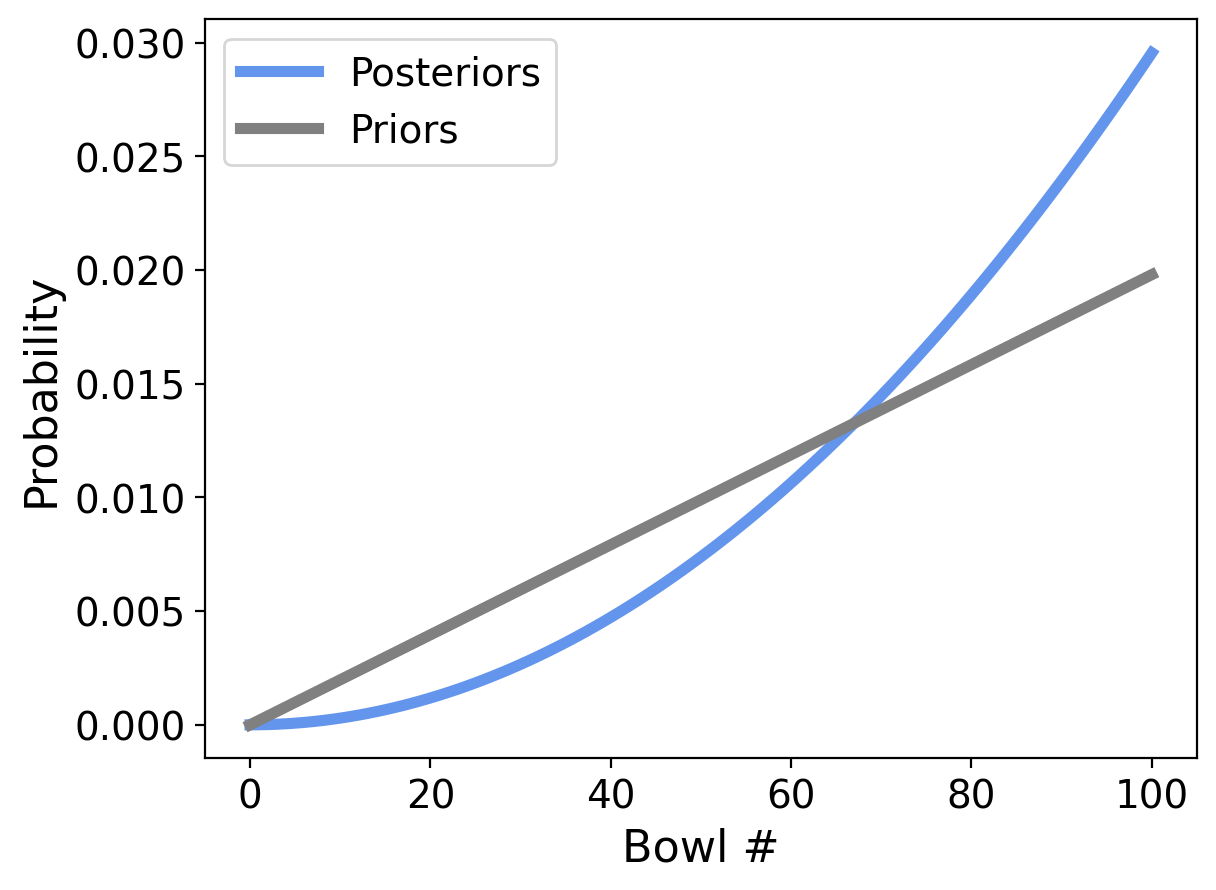
Now the small numbered bowls are even less likely, and the high numbered bowls are even more likely.
OK. Now let’s make things more interesting. What if our next draw from that same bowl were a chocolate cookie?
likelihood_chocolate = 1 - likelihood_vanilla
update(dist_101, likelihood_chocolate);
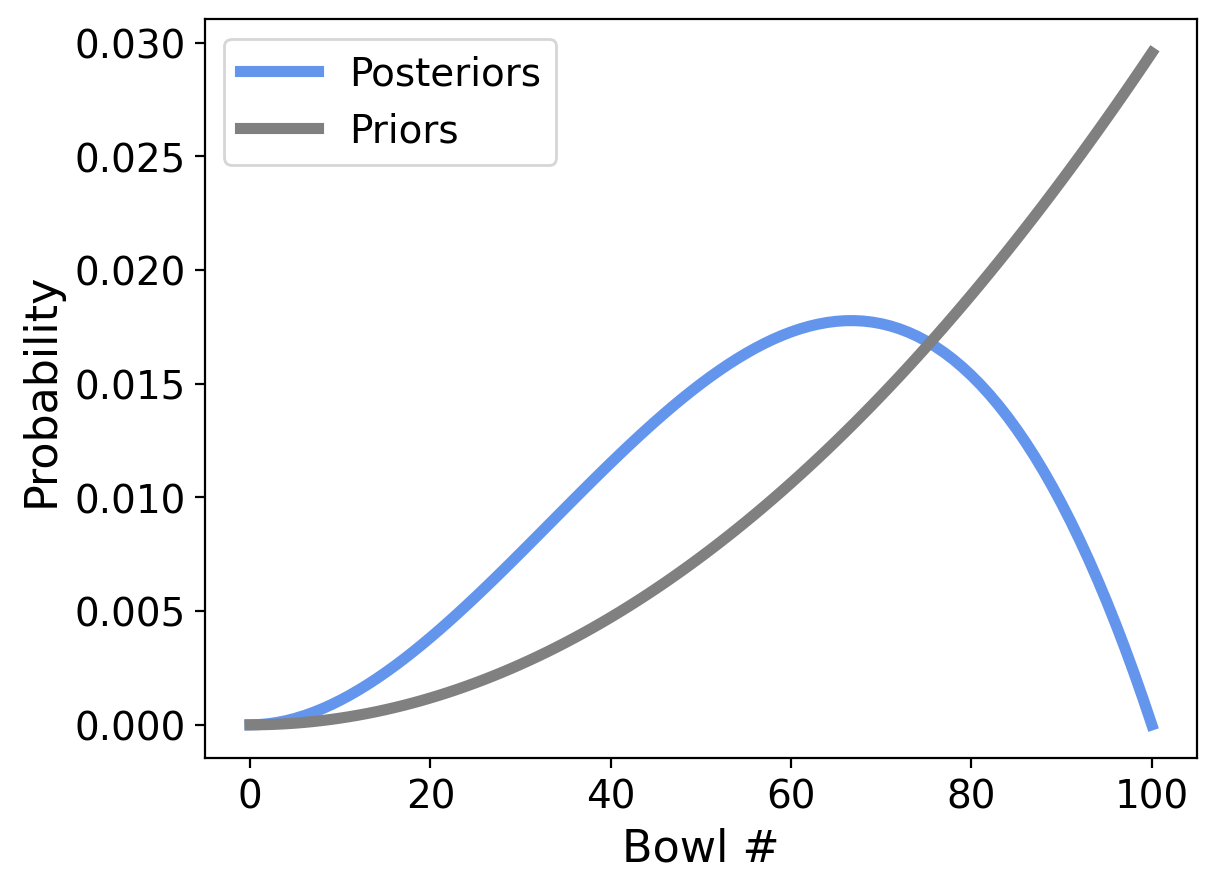
Now things look quite different!
Our bowl can’t be bowl number 100 anymore because that one had no chocolate cookies at all. So we have zero probability for Bowl 100.
But it’s still more likely to be a higher-numbered bowl, because we have drawn more vanilla cookies (two) than chocolate cookies (one).
The highest point in the posterior distribution is the most likely bowl. Which bowl is most likely?
dist_101['probs'].idxmax()
67
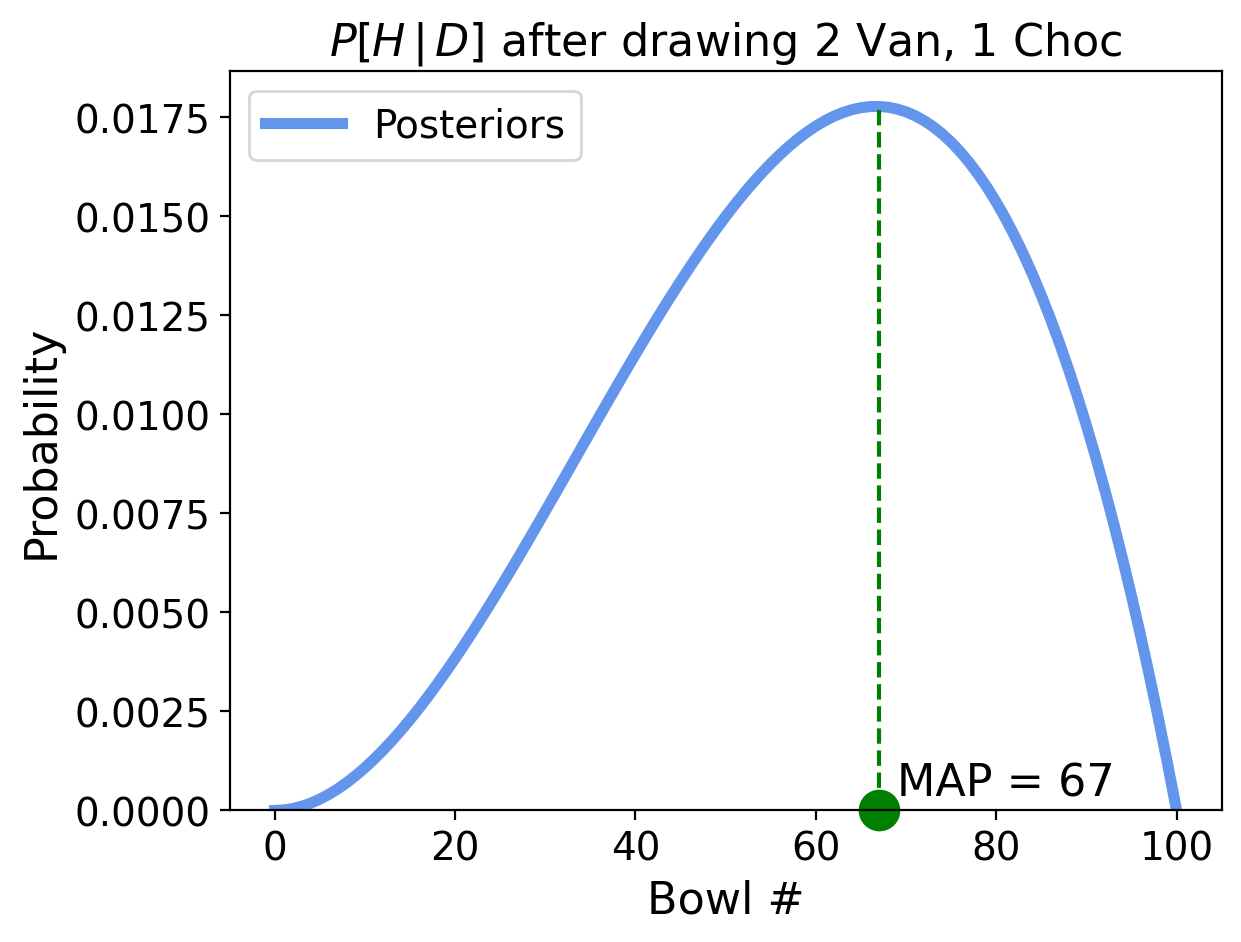
Bowl 67 is the most likely bowl.
This bowl has the “maximum a posteriori probability” which is the name we give to the event with the highest posterior probability.
The term maximum a posteriori is usually appreviated as MAP.
Choosing a Bowl, or Choosing a Distribution?#
Now, notice that the maximum a posteriori bowl is the one that is closest to 2/3 vanilla and 1/3 chocolate.
This is not a coincidence!
When we start from a uniform prior, the most likely bowl is the one whose cookie proportions most closely match our data.
That is, by choosing a bowl, we have also chosen a distribution.
This brings us closer to how Bayesian reasoning is used in statistics.
Consider: the example with 101 different bowls might seem a bit strange, but it’s actually exactly equivalent to a more typical question:
Imagine that you have one bowl of cookies. You don’t know what fraction of cookies are vanilla, but you think it is equally likely to be any fraction from 0 to 1. If you draw three cookies and two are vanilla, what proportion of cookies in the bowl do you think are vanilla?
The posterior distribution we calculated for 101 bowls is the answer for this question as well.
Why is that? Think about your state of knowledge in the two cases
100 bowls, each has a different distribution of cookies
single bowl with a an unknown distribution of cookies
Can you see that your knowledge is the same in each case?
We call this type of question “estimating proportions” which will be the subject of our next lecture.