Conjugate Priors
Contents
Conjugate Priors#
Today we’ll introduce a simple but powerful method for performing Bayesian analysis.
It’s useful in certain commonly occurring situations involving a single parameter: the use of a conjugate prior.
To motivate the use of conjugate priors, let’s take a look at how we’ve been performing Bayesian updates so far.
In all the cases we’ve studied, we have formed a table that captures the distribution of interest. It could be a 1D table for a distribution over a single parameter, or a 2D table for a distribution over two parameters, etc.
That is, we are breaking the distribution up into little pieces and separately computing each little piece. A Bayesian update consists of multiplying the prior by the likelihood separately in each piece of the distribution.
This called a grid approach to working with distributions.
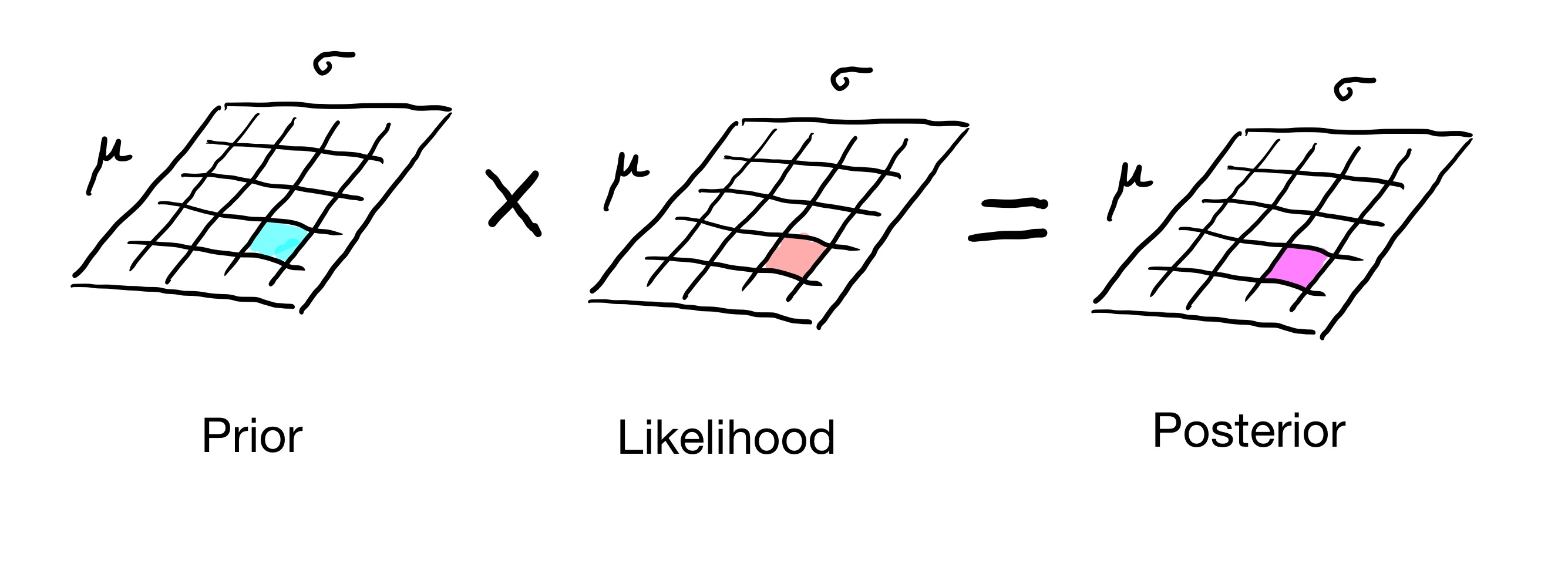
Now, there is nothing wrong with the grid approach, but in some cases we can proceed more quickly to an answer by working with distributions as formulas – that is, entirely mathematically.
Doing a Bayesian Update Analytically#
Let’s say we want to do a Bayesian update, but using distributions as formulas (rather than grids).
Assume the formula for our prior is some function:
and the formula for our likelihood (based on seeing data \(x\)) is some other function:
then the (unnormalized) posterior is
Now, in general, this may not get us anywhere useful. If we cannot simplify \(f(\theta) g_x(\theta),\) then to evaluate the posterior, we would just wind up doing the multiplications numerically – ie, via the grid method.
But in some cases, that is for certain combinations of prior and likelihood functions \(f\) and \(g\), the product does simplify, and as a result we can make progress without needing to do a grid computation.
Remember that the likelihood \(g_x(\theta)\) has the same formula as its associated probability distribution \(p_\theta(x)\).
It’s just that to get the likelihood, we use the formula differently: we hold \(x\) fixed (the data) and vary \(\theta\) (the parameter of the distribution).
So when we have a particular distribution \(p_\theta(x)\) that has likelihood \(g_x(\theta)\), if there is a prior distribution \(f(\theta)\) such that the product of \(f\) and \(g\) simplifies, we call \(f(\theta)\) a conjugate prior for the distribution \(p_\theta(x)\).
(“Conjugate” means connected, or coupled.)
The Binomial and The Beta#
OK, this will all become clearer with an example.
Let’s think back to the Euro Problem. The goal there was to estimate the parameter \(p\) of the Belgian Euro landing heads.
We saw that if we have a dataset of \(n\) coin flips showing \(k\) heads, that the distribution of interest is the Binomial, ie
So, for this problem, \(p\) is the parameter of interest \(\theta\), and \(k\) is the data \(x\). We will consider \(n\) fixed. Let’s rewrite the formula using those notations:
What is the likelihood of a particular dataset \(x\)? Well it is the same formula, just varying \(\theta\) intead of \(x\):
Now, the Binomial distribution has a conjugate prior. It is called the Beta distribution and it has two parameters \(\alpha\) and \(\beta\).
It is defined as:
This is a distribution for \(\theta\) in \([0, 1]\).
Let’s examine this formula more closely. It has two parts:
You can think of the \(\Gamma\) function in the normalizing constant as similar to a factorial (but for complex numbers).
For any given \(\alpha\) and \(\beta\), the normalizer is a constant. Its role is just to make sure the entire distribution sums to 1.
Since the normalizing constant doesn’t vary with \(\theta\), and \(\theta\) is what we care about, let’s set the normalizing constant aside for now.
We’ll bring the normalizing constant back in at the end.
So for now we’ll work with the unnormalized Beta:
Let’s say we choose a particular Beta distribution by setting some values of \(\alpha\) and \(\beta\).
What happens if we use this distribution as our prior?
Again, we’ll set aside the normalizing constant of the Binomial, so the likelihood becomes:
Let’s do a Bayesian update with this prior and likelihood:
Now, here is where the magic happens!
Notice that we can combine terms:
But this is just another unnormalized Beta distribution!
It has new values for its parameters: \(\alpha+x\) and \(\beta+n-x\).
And to normalize this distribution, we just use the formula for the Beta normalizing constant using these new parameters.
Insights#
What happened here?
We used a particular formula for a prior, and when we did a Bayesian update, we got the same formula back for the posterior (with new values for its parameters).
No grids involved!
Now, you may ask: OK, but does the Beta distribution actually make a good prior for real problems?
In fact, yes it does. In particular, when \(\alpha = \beta = 1\), the Beta is the Uniform distribution on (0, 1).
So using the Beta for problems like the Euro Problem is particularly easy:
Start with the uniform prior:
Now, recall that we observed 140 heads and 110 tails.
So the posterior is
In Practice#
Let’s see how easy this is to use.
import scipy.stats
prior = scipy.stats.beta(1, 1)
posterior = scipy.stats.beta(141, 111)
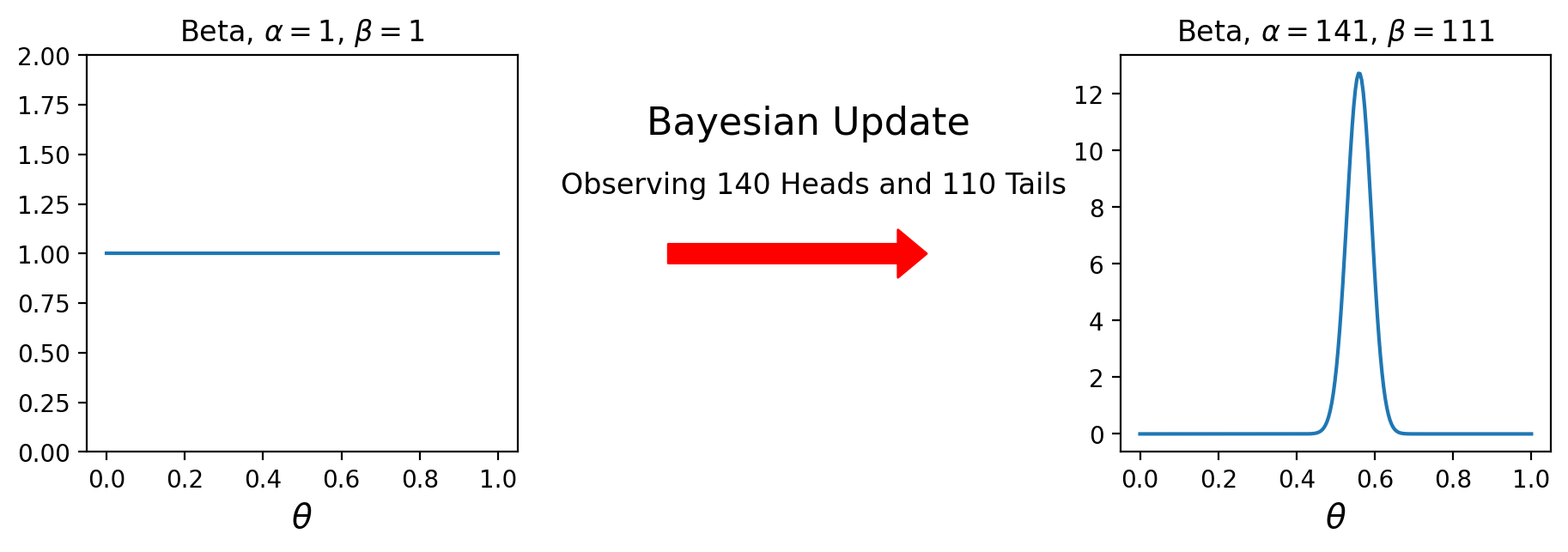
That’s it – just one function call to scipy to get our answer.
Now, previously we computed the prior using the grid method. In that case, we started with a uniform prior, and did standard Bayes updates, so we should get the same result using the conjugate prior.
And indeed we do:
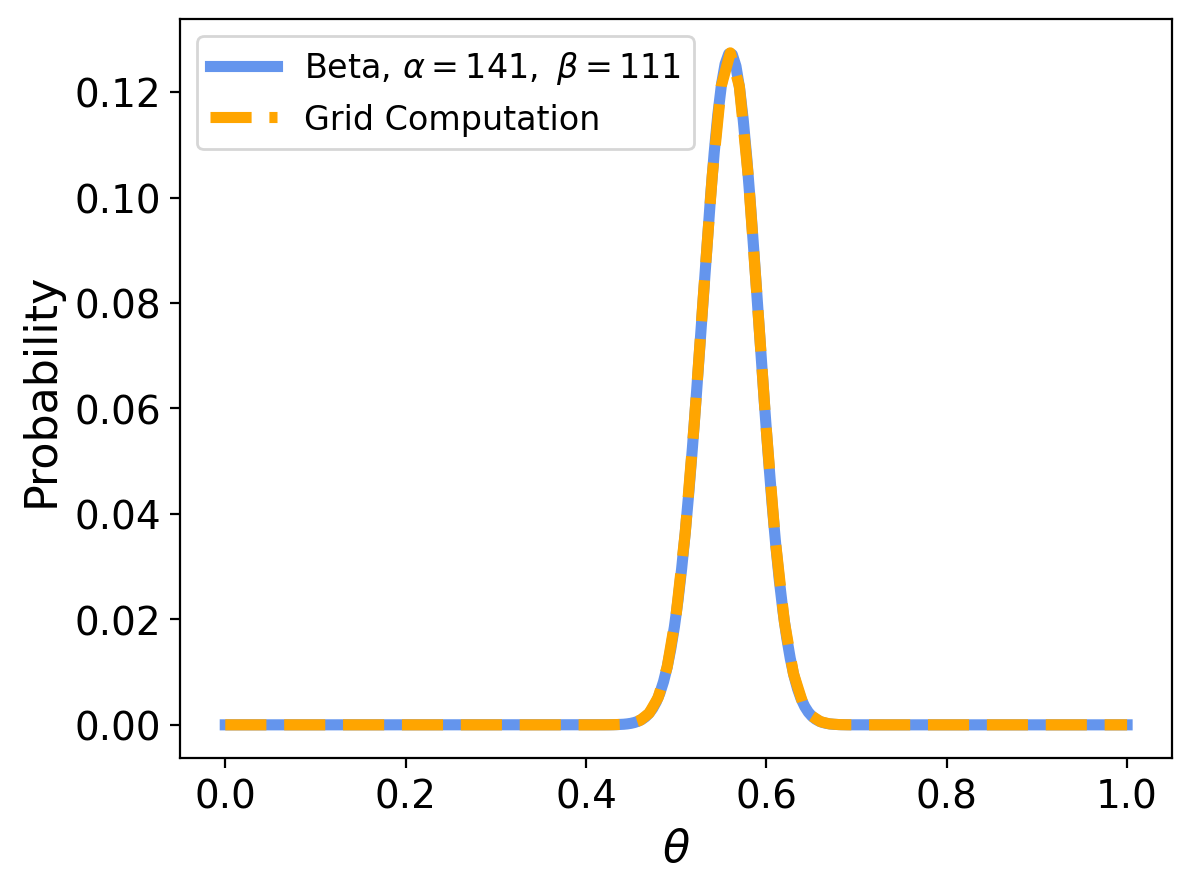
Many Things are Now Easy#
Note that since we have an analytic formula for the posterior, many things are simple.
For example, the MAP estimate of \(\theta\) is just the mode of the Beta distribution. This can be calculated analytically, and turns out to be:
when \(\alpha\) and \(\beta\) are both larger than 1.
So for the Euro problem, \(\operatorname{MAP}(\theta) = 140/250 = 0.56\)
The same result would be obtained using the (frequentist) MLE if the dataset is large enough.
Likewise, the MMSE estimate of \(\theta\) is the mean of the Beta, which is \(\frac{\alpha}{\alpha+\beta}\) (for any \(\alpha, \beta\)).
Notice that the difference between the MAP and the MMSE is only significant when \(\alpha\) and \(\beta\) are small – ie, when one has relatively little data.
Further, we can easily calculate a credible interval for \(\theta\):
# Calculate a 90% credible interval for this posterior:
low_bound = scipy.stats.beta(141, 111).ppf(0.05)
high_bound = scipy.stats.beta(141, 111).ppf(0.95)
print(fr'The 90% credible interval for theta is ({low_bound:0.3f}, {high_bound:0.3f})')
The 90% credible interval for theta is (0.508, 0.611)
Return to World Cup#
Ok, we’ll do a couple more examples to show the power of conjugate priors.
Let’s return to the World Cup problem.
You recall that we were interested in \(\lambda\), the goal scoring rate of each team (France and Croatia).
We assumed that goal scoring for a given team occurred as a Poisson process, so the number of goals in a game was given by the Poisson distribution.
For a prior, we chose the Gamma distribution, which is a distribution over \(\lambda \geq 0\) with parameters \(\alpha\) and \(\beta\).
Here is the unnormalized Gamma distribution (leaving off the normalizing constant):
And here is the (unnormalized) Poisson distribution:
So the unnormalized posterior is:
The posterior has the functional form of the Gamma distribution, with new parameters \(\alpha+k\) and \(\beta+t\).
So now you see … the Gamma is the conjugate prior of the Poisson distribution.
This derivation provides insight into what the parameters of the posterior distribution mean: \(\alpha\) reflects the number of events that have been observed, and \(\beta\) reflects the elapsed time.
To perform a Bayesian update on the prior, we simply add the number of observed events to \(\alpha\) and the duration of the observation to \(\beta\).
In our previous analysis, we used the fact that the average number of goals per game is 1.4, so our prior was a Gamma distribution with \(\alpha = 1.4\) and \(\beta = 1\).
And
for France, who scored 4 goals, the posterior is a Gamma with \(\alpha = 5.4\) and \(\beta = 2\)
for Croatia, who scored 2 goals, the posterior is a Gamma with \(\alpha = 3.4\) and \(\beta = 2\).
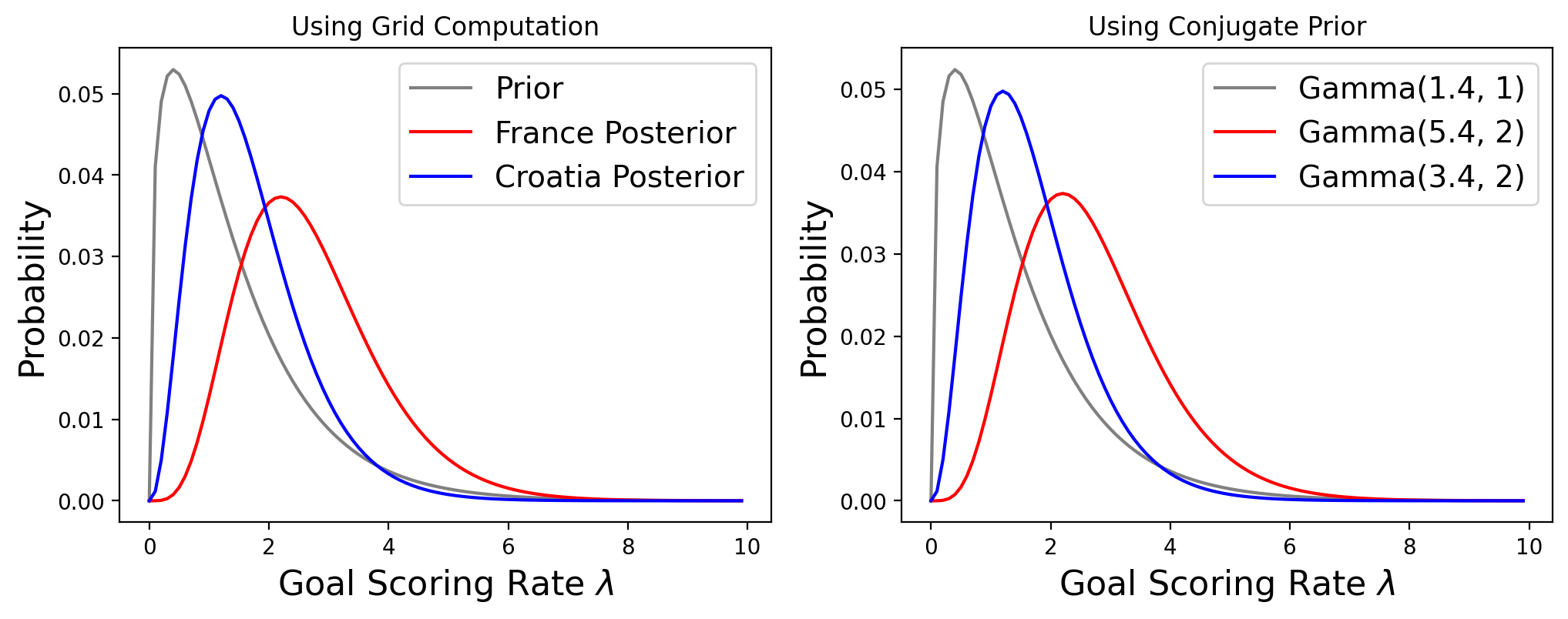
Now, let’s see how quickly we can compute the probability that France would win a rematch by using conjugate priors.
Recall that for this, we compare samples from the posterior predictive distribution – that is the distribution of what we can actually observe (goals).
Rather than doing this via a grid search, we will use a method that is much easier to implement (and understand).
We will take advantage of the fact that we have a scipy function that can sample Gamma and Poisson distributions.
We will simply sample each posterior predictive distribution, and compare samples. We will then count up how many times the sample from France’s distribution exceeds the sample from Croatia’s distribution.
In other words, our strategy will be:
For some number of simulated “matches”:
For each team:
Use the team’s Gamma to sample its posterior on \(\lambda\)
Use the Poisson with the \(\lambda\) obtained in (a.) to sample the number of goals scored
Compare the samples to determine the winner of this “match”
Compute the fraction of matches won by France
Notice how clear this logic is – very easy to follow.
n_trials = 10000
n_france_wins = 0
for i in range(n_trials):
france_lambda = gamma.rvs(a = 5.4, scale = 1/2)
france_goals = poisson.rvs(france_lambda)
croatia_lambda = gamma.rvs(a = 3.4, scale = 1/2)
croatia_goals = poisson.rvs(croatia_lambda)
if france_goals > croatia_goals: n_france_wins += 1
estimated_p = n_france_wins/n_trials
std_err = np.sqrt(estimated_p * (1-estimated_p) / n_trials)
print(rf'The probability France would win a rematch is {n_france_wins/n_trials:0.4f} +/- {(1.96 * std_err):0.4f}')
The probability France would win a rematch is 0.5693 +/- 0.0097
As we would expected, what we got when we computed the exact solution lies within our confidence interval here.
The strategy we used here is called a Monte Carlo evaluation. It is attractive because it is so easy to program, and so clear what is going on.
In a Monte Carlo evaluation, we are concerned with quantities that are functions of distributions. Instead of trying to compute the expected value of the quantity exactly, we sample the distribution, compute the quantity for that sample, and average.
Bonus material:
Lions and Tigers and Bears#
As a final example, we’ll explore the Multinomial and its conjugate prior the Dirichlet distribution.
To understand this case, think of the multinomial as the extension of the binomial to more than two outcomes. So the multinomial can describe the probabilities of rolling “weighted” dice, such that different sides land with different probabilities.
Then the Dirichlet’s relationship to the multinomial is just like the Beta’s relationship to the Binomial.
Here’s an example to make things concrete.
Suppose we visit a wild animal preserve where we know that the only animals are lions and tigers and bears, but we don’t know how many of each there are. During the tour, we see 3 lions, 2 tigers, and one bear. Assuming that every animal had an equal chance to appear in our sample, what is the probability that the next animal we see is a bear?
To answer this question, we’ll use the data to estimate the prevalence of each species, that is, what fraction of the animals belong to each species. If we know the prevalences, we can use the multinomial distribution to compute the probability of the data. For example, suppose we know that the fraction of lions, tigers, and bears is 0.4, 0.3, and 0.3, respectively.
In that case the probability of the data is:
from scipy.stats import multinomial
data = 3, 2, 1
n = np.sum(data)
ps = 0.4, 0.3, 0.3
multinomial.pmf(data, n, ps)
0.10368
The Dirichlet#
The conjugate prior for the multinomial distribution is the Dirichlet distribution.
In a Dirichlet distribution, the quantities are vectors of probabilities, \(\mathbf{x}\), and the parameter of the distribution is a vector \(\alpha\).
For example:
from scipy.stats import dirichlet
alpha = 1, 2, 3
dist = dirichlet(alpha)
Since we provided three parameters, the result is a distribution of three variables. If we draw a random value from this distribution, we get a probability vector – that is, a vector that sums to 1.
print(dist.rvs())
print(dist.rvs().sum())
[[0.03381227 0.22982868 0.73635904]]
1.0
You can think of the probability vector as giving the parameters of a multinomial.
OK, let’s construct the posterior corresponding to 3 lions, 2 tigers, and 1 bear:
dist = dirichlet((4, 3, 2))
Here is a density plot of the posterior. Note that there are three parameters, so the density is in 3D.
However, only points that sum to 1 are allowed as distributions. Those points lie on a triangle in 3D space.
If we had seen more data, then the posterior would become more concentrated around its mode. This would reflect greater certainty about the multinomial distribution’s parameters.
For example, suppose we had seen 30 lions, 20 tigers, and 10 bears. Then the distribution would be:
dist = dirichlet((31, 21, 11))
If we are interested in the individual parameters of the multinomial, we can marginalize the posterior (sum over all but one parameter).
It turns out that each marginal is just a Beta distribution, so we can immediately construct it from the data.
Let’s go back to our original set of observations of 3 lions, 2 tigers, and 1 bear.
Then the marginal for lions would be a Beta with \(\alpha = 4\) and \(\beta = 4\), because we’ve seen 3 lions and 3 non-lions. Similarly for the others:
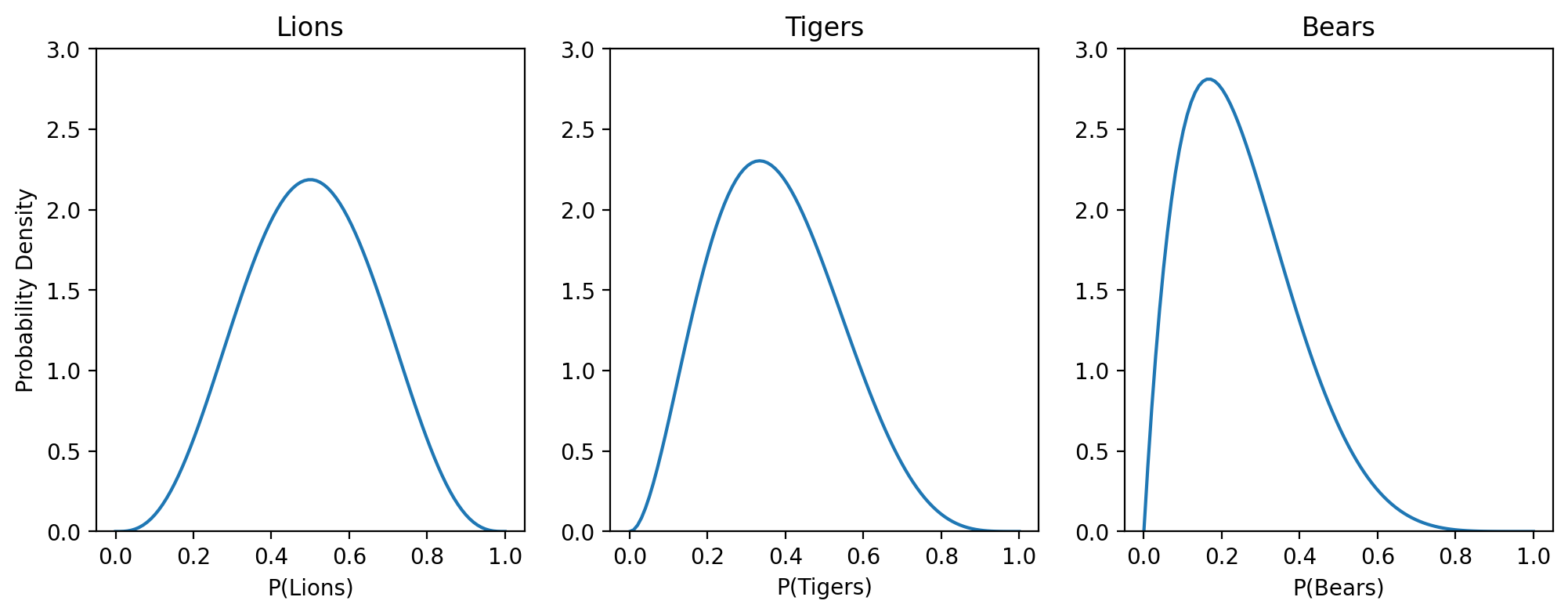
Summary#
At this point, if you feel like you’ve been tricked, that’s understandable. It turns out that many of the problems we’ve studied so far can be solved with just a few arithmetic operations. So why did we go to all the trouble of using grid algorithms?
Sadly, there are only a few problems we can solve with conjugate priors; in fact, this lecture includes most of the ones that are useful in practice.
For the vast majority of problems, there is no conjugate prior and no shortcut to compute the posterior distribution. That’s why we need grid algorithms as our general strategy.
But when you have a problem that can use a conjugate prior – for example, a likelihood that comes from Binomial, or Poisson, or Multinomial – then a conjugate prior can save you a lot of work!