Confidence Intervals
Contents
Confidence Intervals#
In this lecture we will talk about confidence intervals. Confidence intervals provide an alternative to using a point estimator \(\hat{\theta}\) when we wish to estimate an unknown population parameter \(\theta\).
In particular, a confidence interval is a random interval, calculated from the sample, that contains \(\theta\) with some specified probability. For example, a 95% confidence interval for \(\theta\) is a random interval that contains \(\theta\) with probability 0.95.
What does this mean exactly?
The simple answer is that about 95% of the time, the computed confidence interval contains the true value of the population parameter.
In other words, imagine you performed the sampling process 100 times, and each time you computed a confidence interval. Then you’d expect about 95 of those confidence intervals to include the true value of the population parameter.
Here is an example of such process. Imagine that the populaiton is normally distributed with mean \(\mu\) and variance \(\sigma\). For instance, we can think of the example of SAT scores that we discussed in the lecture on sampling.
To estimate the true value of \(\mu\) we repeat the sampling process 20 times and compute the confidence interval for paramter \(\mu\) for each sample.
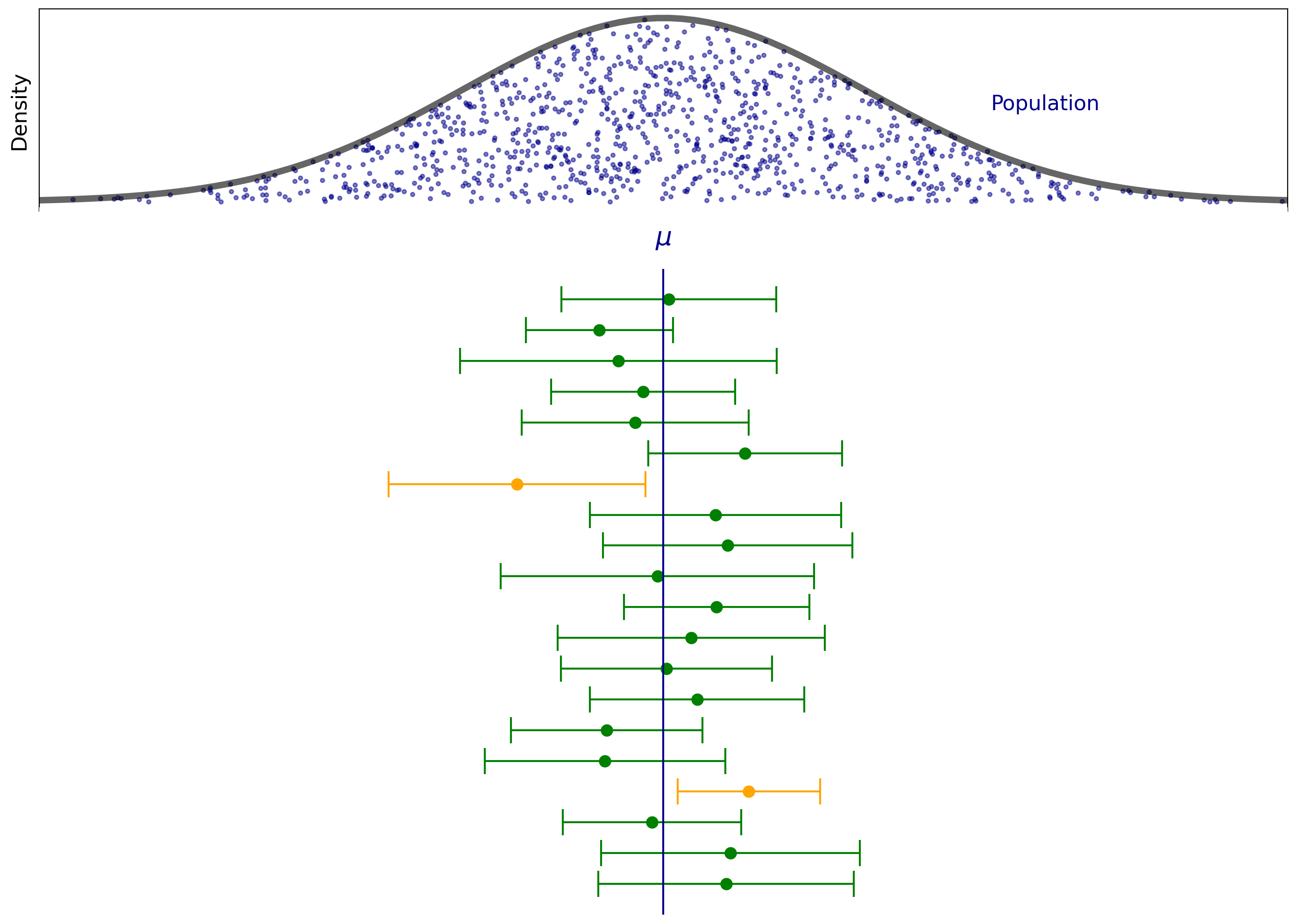
Note how the confidence intervals dance around, and how their sizes vary. Not every confidence interval contains the population mean \(\mu\) – the orange ones don’t. However, roughly 95% of the confidence intervals do contain the true mean.
Now that we understand how to interpret confidence intervals, the next question is how to compute them.
Confidence Intervals for the Mean of a Normal Distribution#
To start with, let’s assume that our population has a Gaussian (i.e., normal) distribution.
That is, let \(x_1, x_2, ..., x_n\) be a random sample from a population that has a normal distribution with unknown mean \(\mu\) and known variance \(\sigma^2\). Let
For \(0 \leq \alpha \leq 1\), let \(z(\alpha)\) be that number such that the area under the standard normal density function to the right of \(z(\alpha)\) is \(\alpha\). Note that the symmetry of the standard normal density function about zero implies that \(z(1-\alpha) = -z(\alpha)\).
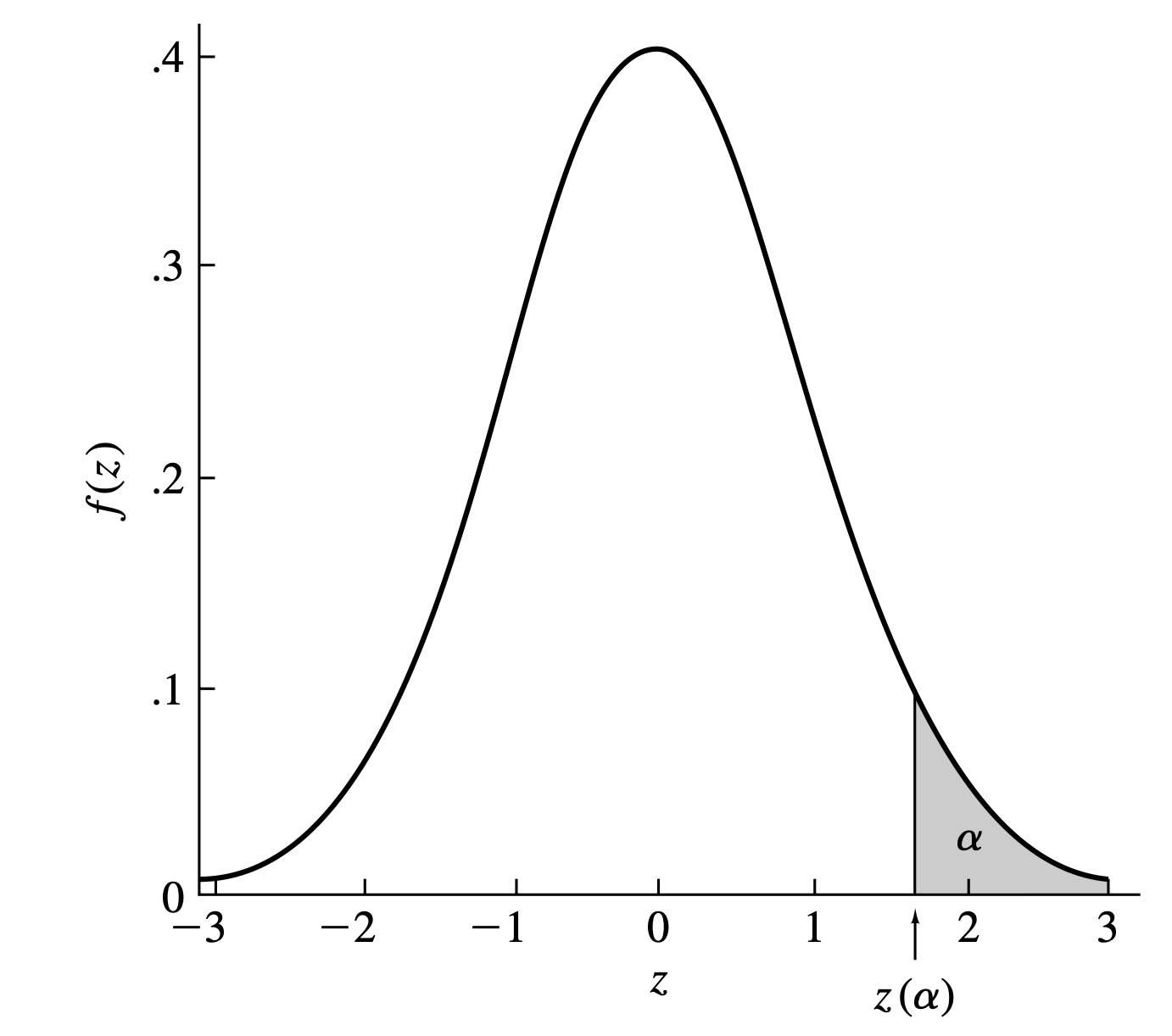
If random variable \(Z\) follows standard normal distribution, then, by definition of \(z(\alpha)\),
We know from the sampling lecture that \(\frac{M - \mu}{\sigma/\sqrt{n}}\) has a standard normal distribution, so
Elementary manipulation of the inequalities gives
This implies that the probability that \(\mu\) lies in the interval
is approximately \(1-\alpha.\) In other words, this is a \(100(1-\alpha)\%\) confidence interval for the population mean, \(\mu\).
A common setting of \(\alpha\) is 0.05 to find the 95% confidence interval. In that case we calculate:
If we repeatedly sampled from our population, this confidence interval would containt the true mean of the population 95% of the time. We can calculate the interval using the sample mean \(M\) and the known variance \(\sigma^2\).
Unknown Population Variance#
As we have seen so far, when the population is normally distributed and has a known variance \(\sigma^2\), finding confidence intervals for population mean is a relatively straightforward task. However, the population variance, \(\sigma^2\), is typically not known.
How can we replace it?
Of course, we can estimate \(\sigma\) from the data. Since \( \sqrt{\frac{1}{n}\sum_i (x_i - M)^2}\) is known to be a biased estimate of the true standard deviation, we typically apply Bessel’s correction to get an unbiased estimate:
This substitution has a far-reaching consequence. The distribution of \(\frac{M - \mu}{s/\sqrt{n}}\) is a
\(t\) distribution with \(n-1\) degrees of freedom.
The \(t\) Distribution#
The history of the “t-distrubution” is quite interesting. A man named William Gosset worked at the Guinness Brewery in Ireland. He needed a way to determine if changes in the brewing processes made a difference. Unfortunately, he generally only had small samples sizes.

William Gosset realized that he couldn’t use the normal distribution for his experiments and introduced the \(t\)-distribution. This distrubtion has ‘’fatter’’ tails compared to the normal distribution. The thickness of the tails depends on the size of the sample and accounts for a higher probability of observing extreme values in the sample.
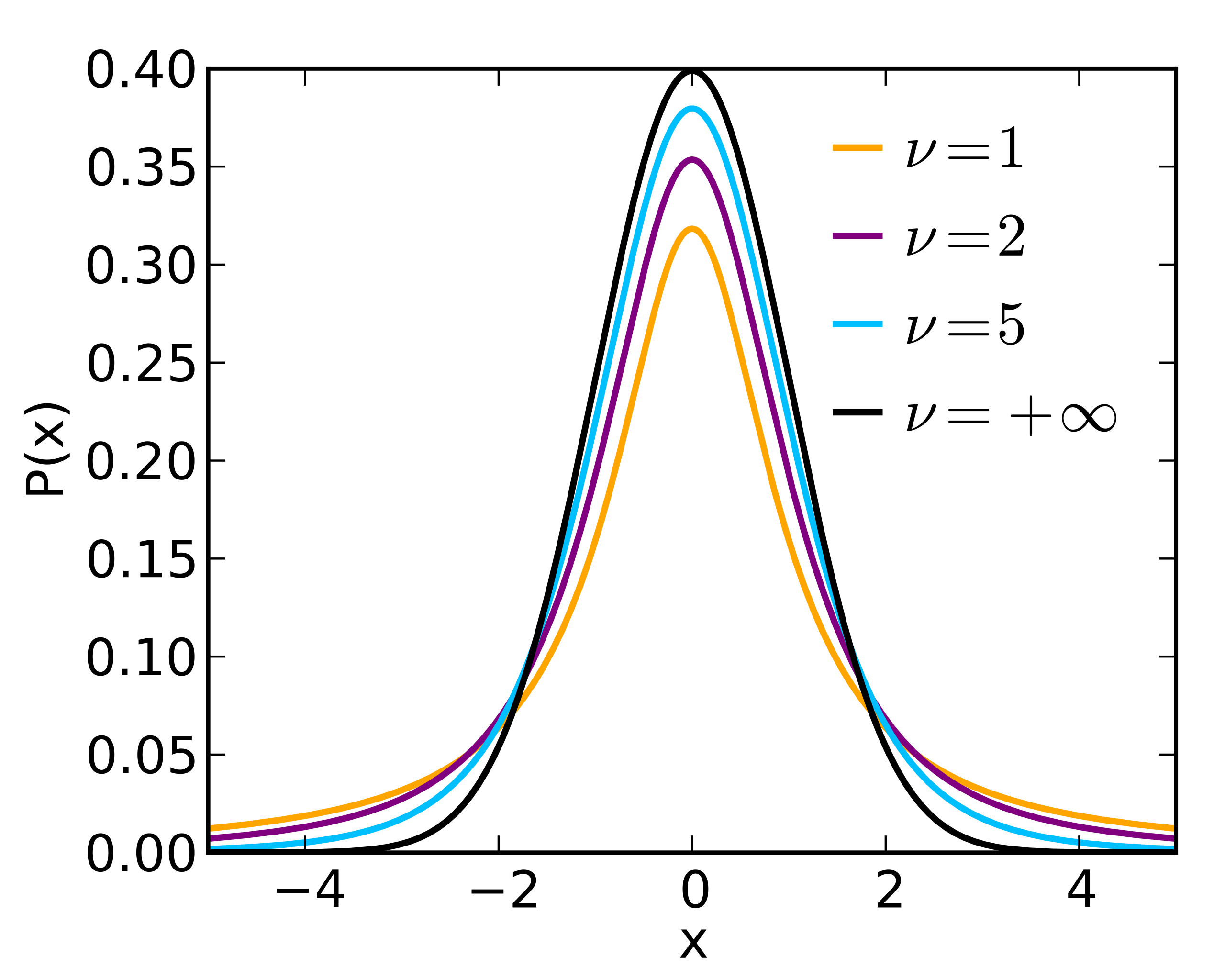
As \(\nu\) (the degres of freedom, \(\nu=n-1\)) goes to infinity, we get the normal distribution.
We shall continue to assume that \(x_1, x_2, ..., x_n\) be a random sample from a normal distribution having mean \(\mu\) and variance \(\sigma^2\). Let \(\tau_{n-1}(x)\) denote the PDF of the \(t\) distribution with \(n-1\) degrees of freedom and \(t\) be a constant such that
For every value of \(n\), the value of \(t\) can be found from the table of the \(t\) distribution. For example, if \(n = 12\) and \(T_{11}(x)\) denotes the CDF of the \(t\) distribution with 11 degrees of freedom, then
If \(\alpha = 0.05\), it follows that \(T_{11}(t) = 0.975\). It is found from the table that \(t = 2.201\), the 0.975 quantile of the \(t\) distribution with 11 degrees of freedom.
Thus, when the population standard deviation \(\sigma\) is not known the \(100(1-\alpha)\%\) confidence interval becomes
For every value of \(n\), the value of \(t\) can be found from the table of the \(t\) distribution.
For example, if \(n = 12\) and \(T_{11}(x)\) denotes the CDF of the \(t\) distribution with 11 degrees of freedom, then if \(\alpha = 0.05\), we need to find the value to \(t\) such that \(T_{11}(t) = 0.975\). We can look this up in a t-table and find that \(t = 2.201\) corresponds to the 0.975 quantile of the \(t\) distribution with 11 degrees of freedom.
Since people often prefer to use the normal distribution, and since the \(t\)-distribution becomes equivalent to the normal when the sample size \(n\) becomes large, common practice is to use normal distribution instead of the \(t\)-distribution for \(n \geq 30\).
For this course, we recommend using exclusively \(t\)-distribution when the population standard deviation is not known.
Confidence Intervals for the Mean of Any Distribution#
What happens if the type of the population distribution is not known?
Let \(x_1, x_2, ..., x_n\) be a random sample from a population that has an unknown distribution with unknown mean \(\mu\) and known variance \(\sigma^2\). Let
The central limit theorem tells us that the distribution of \(\frac{M - \mu}{\sigma/\sqrt{n}}\) can be approximated by a standard normal distribution, so
This is the same expression as we found before. Thus, the \(100(1-\alpha)\%\) confidence interval is simply
When the sample of size \(n\) is from a population that has an unknown distribution with unknown mean \(\mu\) and unknown variance \(\sigma^2\), the \(100(1-\alpha)\%\) confidence interval becomes
Here, \(s\) is again an unbiased estimate of the true standard deviation given by \( s = \sqrt{\frac{1}{n-1}\sum_i (x_i - M)^2}. \)
How large should \(n\) be for us to be able to rely on the central limit theorem?
The answer is that it depends on the population distribution. A highly skewed distribution, or one with a large ratio of standard deviation to mean, will require larger sample sizes.
Visualizing Confidence Intervals#
For the SAT example, the figure below shows the 95% confidence intervals for the population mean based on a sample of size 15 and a sample of size 50.
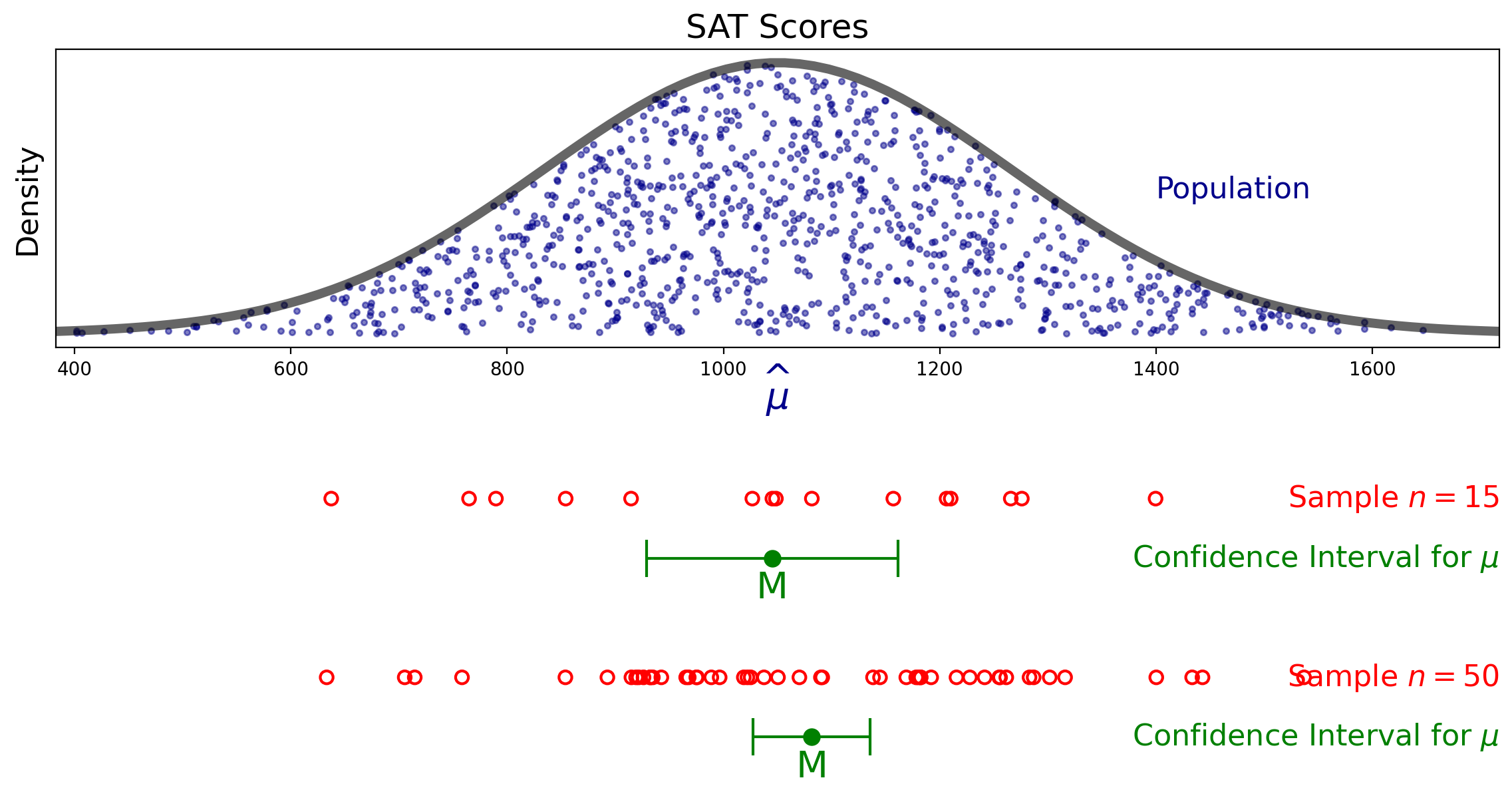
Confidence Intervals for the Mean of Any Distribution#
Now, we have so far been assuming that the population is normally distributed. This may seem like a very limiting assumption.
However, it turns out that in the majority of cases, the distribution of the population does not matter too much.
Here is why.
Recall that our sample statistic is
Now recall that the Central Limit Theorem tells us that for \(n\) large enough, the sum of \(n\) samples from any distribution is approximately normally distributed.
A technical limitation: the underlying distribution must have finite variance. Most distributions you encounter in practice will have this property.
How large should \(n\) be for us to be able to rely on the Central Limit Theorem?
The answer is that it depends on the population distribution. A highly skewed distribution, or one with a large ratio of standard deviation to mean, will require larger sample sizes.
Reporting and Using Confidence Intervals#
What is the role of confidence intervals in summarizing data?
The simple answer is confidence intervals are crucial.
You cannot communicate with clarity without reporting confidence intervals.
Any time you are reporting a statistic derived from a sample, such as the sample mean, you should report the associated confidence intervals.
Confidence intervals combine information on location and precision.
They tell you (or your reader) both how large is the quantity (location) and how much information the estimate provides.
There are standard ways for doing this.
In text, it is standard to write in this format:
\(M = 30.5 \text{cm, 95% CI } [18.0, 43.0]\)
In a table, you should use this format:
height |
95% CI |
|
|---|---|---|
men, n = 25 |
69.0 in |
[68.1, 69.9] |
women, n = 23 |
61.1 in |
[60.2, 62.0] |
In this lecture we’ve computed 95% confidence intervals. Some statisticians will suggest that you may want to use a different confidence level depending on the setting.
If your results will be used to make life-or-death decisions, perhaps a 99% or even a 99.9% confidence interval should be used.
On the other hand, if we are not so concerned about an occasional miss, perhaps a 90% or 80% confidence interval should be used.
These are reasonable considerations, but in general work it’s probably best to stick with 95% confidence intervals for consistency and ease of interpretation.