Gradient Descent
Contents
Gradient Descent#
In linear regression, our goal was to find a parameter vector \(\beta\) so that sum of squared error \(\Vert \mathbf{y} - \hat{\mathbf{y}}\Vert ^2\) was minimized.
In many cases of interest, we would like to find a maximum likelihood solution but do not have a closed form that we can solve.
It’s time now to talk about how, in general, one can find “good values” for the parameters in problems like these.
To do this, first we define an error function, generally called a loss function, to describe how well our method is doing.
Crucially, we choose loss functions that are differentiable with respect to the parameters.
Using differentiable loss functions we can think of the parameter tuning problem using surfaces like these:
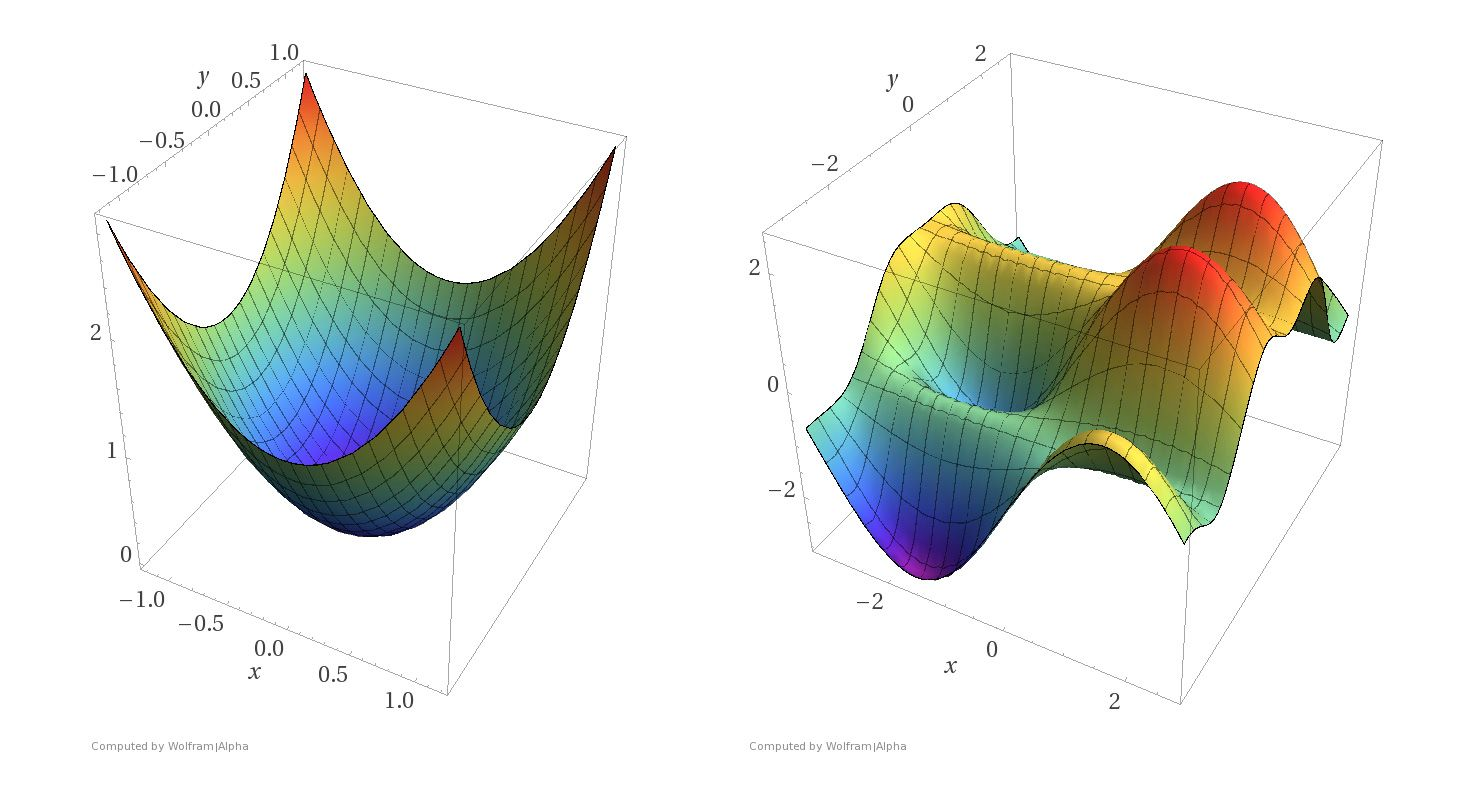
Imagine that the \(x\) and \(y\) axes in these pictures represent parameter settings. That is, we have two parameters to set, corresponding to the values of \(x\) and \(y\).
For each \((x, y)\) setting, the \(z\)-axis shows the value of the loss function.
What we want to do is find the minimum of a surface, corresponding to the parameter settings that minimize loss.
Notice the difference between the two kinds of surfaces.
The surface on the left corresponds to a strictly convex loss function. If we find a local minimum of this function, it is a global minimum.
The surface on the right corresponds to a non-convex loss function. There are local minima that are not globally minimal.
Both kinds of loss functions arise in machine learning.
For example, convex loss functions arise in
Linear regression
Logistic regression
While non-convex loss functions arise in
\(k\)-means
Gaussian Mixture Modeling
and many other settings
We will try to minimize our loss functions using various forms of gradient descent.
Gradient Descent Intuitively#
Imagine you are lost in the mountains, and it is foggy out. You want to find a valley. But since it is foggy, you can only see the local area around you.

The natural thing to do is:
Look around you 360 degrees.
Observe in which direction the ground is sloping downward most steeply.
Take a few steps in that direction.
Repeat the process
… until the ground seems to be level.
Formalizing Gradient Descent#
The key to this intuitive idea is formalizing the idea of “direction of steepest descent.”
This is where the differentiability of the loss function comes into play: as long as the loss function is differentiable, we can define the direction of steepest descent.
And as we showed in the last lecture, the direction of steepest descent is the gradient.
Let’s say we have a loss function \(\mathcal{L}(\mathbf{w})\) that we’d like to minimize.
The components of \(\mathbf{w}\in\mathbb{R}^n\) are the parameters we want to optimize.
For example, if our problem is linear regression, the loss function could be:
where \(\hat{\mathbf{y}}\) is our estimate, ie, \(\hat{\mathbf{y}} = X\mathbf{w}\) so that
To find the gradient, we take the partial derivative of our loss function with respect to each parameter:
and collect all the partial derivatives into a vector of the same shape as \(\mathbf{w}\):
As a reminder, when you see the notation \(\nabla_\mathbf{w}\mathcal{L},\) think of it as \( \frac{d\mathcal{L}}{d\mathbf{w}} \), keeping in mind that \(\mathbf{w}\) is a vector.
As discussed in the last lecture, if we are going to take a small step of unit length, then the gradient is the direction that maximizes the change in the loss function.
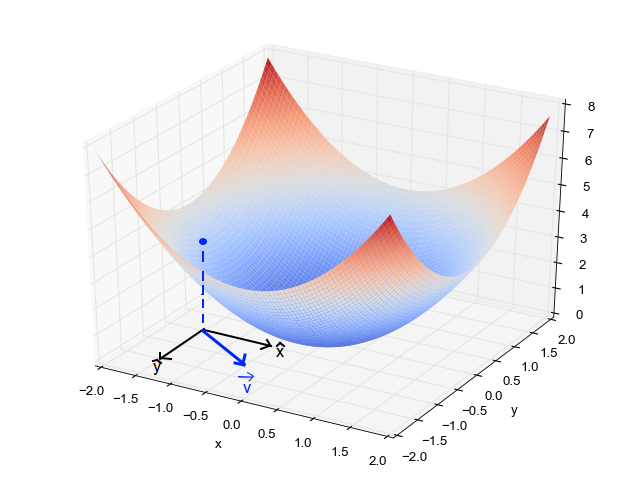
As you can see from the above figure, in general the gradient varies depending on where you are in the parameter space.
So we write:
Each time we seek to improve our parameter estimates \(\mathbf{w}\), we will take a step in the negative direction of the gradient.
… “negative direction” because the gradient specifies the direction of maximum increase – and we want to decrease the loss function.
How big a step should we take?
For step size, will use a scalar value \(\eta\) called the learning rate.
The learning rate is a hyperparameter that needs to be tuned for a given problem, or even can be modified adaptively as the algorithm progresses.
Now we can write the gradient descent algorithm formally:
Start with an initial parameter estimate \(\mathbf{w}^0\).
Update: \(\mathbf{w}^{n+1} = \mathbf{w}^n - \eta \nabla_\mathbf{w}\mathcal{L}(\mathbf{w}^n)\)
If not converged, go to step 2.
How do we know if we are “converged”?
Typically we stop the iteration if the loss has not improved by a fixed amount for a pre-decided number, say 10 or 20, iterations.
Example: Linear Regression#
Let’s say we have this dataset.
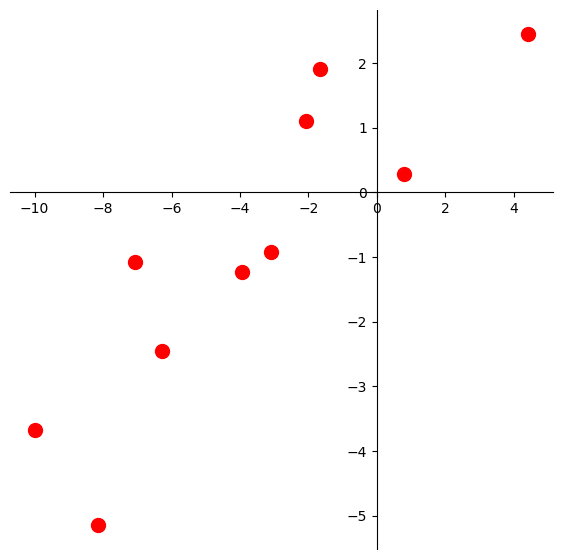
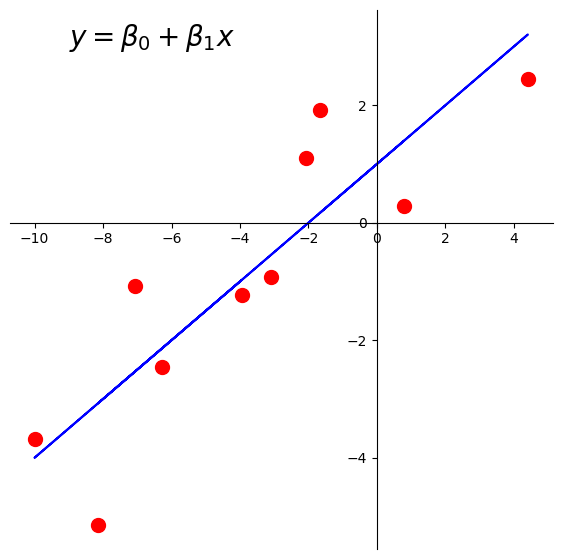
Let’s fit a least-squares line to this data.
The loss function for this problem is the least-squares error:
Of course, we know how to solve this problem using the normal equations, but let’s do it using gradient descent instead.
Here is the line we’d like to find:
There are \(n = 10\) data points, whose \(x\) and \(y\) values are stored in xlin and y.
First, let’s create our \(X\) (design) matrix, and include a column of ones to model the intercept:
X = np.column_stack([np.ones((n, 1)), xlin])
Now, let’s visualize the loss function \(\mathcal{L}(\mathbf{\beta}) = \Vert \mathbf{y}-X\mathbf{\beta}\Vert^2.\)
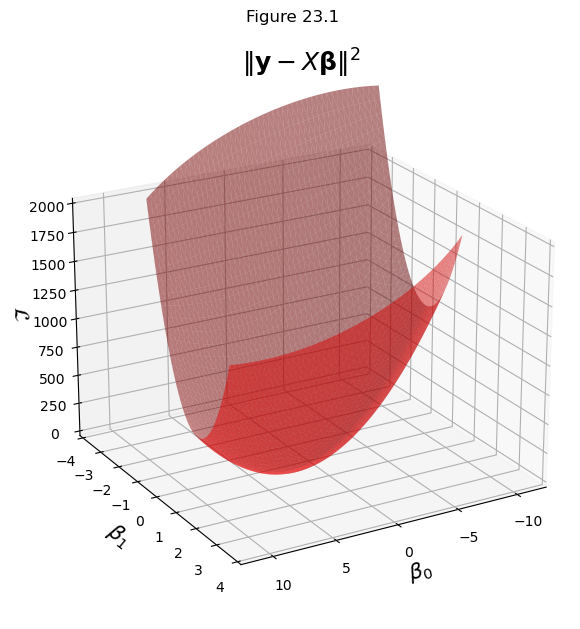
We actually computed the gradient for this problem in the previous lecture.
So, as a reminder, the gradient for a least squares problem is:
So here is our code for gradient descent:
def loss(X, y, beta):
return np.linalg.norm(y - X @ beta) ** 2
def gradient(X, y, beta):
return X.T @ X @ beta - X.T @ y
def gradient_descent(X, y, beta_hat, eta, nsteps = 1000):
losses = [loss(X, y, beta_hat)]
betas = [beta_hat]
#
for step in range(nsteps):
#
# the gradient step
new_beta_hat = beta_hat - eta * gradient(X, y, beta_hat)
beta_hat = new_beta_hat
#
# accumulate statistics
losses.append(loss(X, y, new_beta_hat))
betas.append(new_beta_hat)
return np.array(betas), np.array(losses)
We’ll start at an arbitrary point, say, \((-8, -3.2)\).
That is, \(\beta_0 = -8\), and \(\beta_1 = -3.2\).
beta_start = np.array([-8, -3.2])
eta = 0.002
betas, losses = gradient_descent(X, y, beta_start, eta)
What happens to our loss function per step of gradient descent?
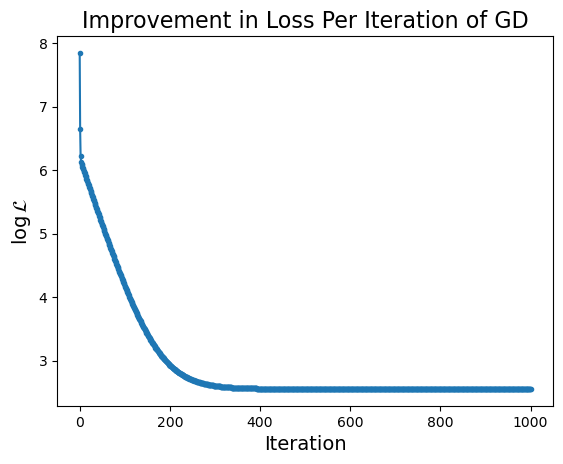
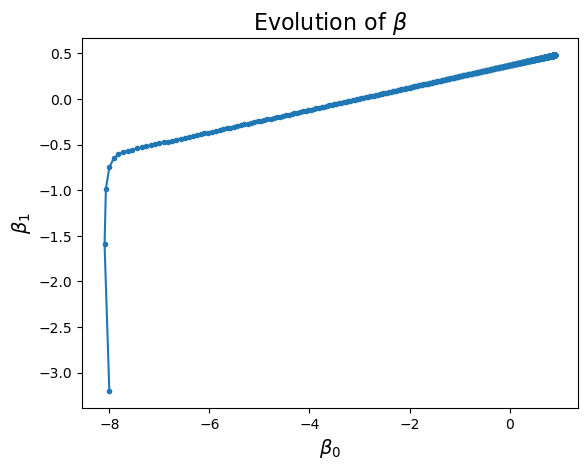
Notice that the improvement in loss decreases over time. Initially the gradient is steep and loss improves fast, while later on the gradient is shallow and loss doesn’t improve much per step.
Now remember that in reality we are like the person who is trying to find their way down the mountain, in the fog.
In general we cannot “see” the entire loss function surface.
Nonetheless, since we know what the loss surface looks like in this case, we can visualize the algorithm “moving” on that surface.
This visualization combines the last two plots into a single view.
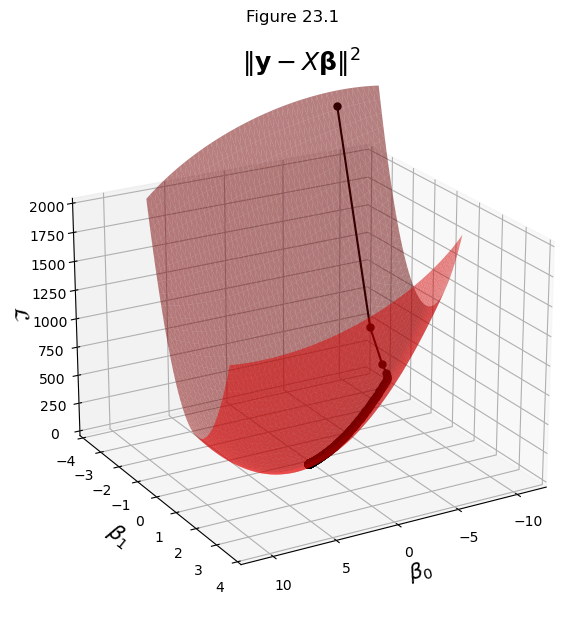
Next we can visualize how the algorithm progresses, both in parameter space and in data space: