Improving Gradient Descent
Contents
Improving Gradient Descent#
Today we’ll talk more about gradient descent.
To recall the setting we are working in: we have a loss function \(\mathcal{L}(\mathbf{w})\) that we’d like to minimize.
The components of \(\mathbf{w}\in\mathbb{R}^n\) are the parameters we want to optimize.
As discussed last lecture, if our problem is linear regression, the loss function could be:
where \(X\) is our matrix of independent observations and \(\mathbf{y}\) is our vector of dependent observations.
For a problem of maximizing a likelihood, we use negative log likelihood (aka cross entropy) loss.
For example, in logistic regression our loss function was:
where the \(x_i\) are the independent observations and the \(y_i\) are the binary-valued dependent observations.
Now, even though these loss functions are very different, we can use the same algorithm – gradient descent – to optimize them.
The same is true of any differentiable loss function. In other words, gradient descent is remarkably versatile.
However, this incredible flexibility comes at a cost. There are various ways in which “vanilla” gradient descent can fail to work well.
We will start by looking at some of the problems that can arise when using gradient descent, and then we’ll look at ways to reduce those problems.
Challenges in Using Gradient Descent#
Let’s start by reminding ourselves of the basic gradient descent algorithm:
Start with an initial parameter estimate \(\mathbf{w}^0\), and a learning rate \(\eta > 0\).
Update: \(\mathbf{w}^{n+1} = \mathbf{w}^n - \eta \nabla_\mathbf{w}\mathcal{L}(\mathbf{w}^n)\)
If not converged, go to step 2.
Unfortunately, Gradient Descent (GD) can suffer from a number of problems:
GD has slow convergence in deep narrow valleys
GD can get stuck in local minima
It can be expensive (slow) to compute the gradient
We’ll now look at each of these issues in turn.
Slow Convergence#
Let’s look at a simple example that illustrates when GD can have slow convergence.
We’ll look at gradient descent on quadratic forms.
We’ll compare two quadratic forms:
\(\mathbf{x}^TA\mathbf{x}\) where
and \(\mathbf{x}^TB\mathbf{x}\) where
The difference between these two loss surfaces is that \(\mathbf{x}^TB\mathbf{x}\) is “deep and narrow”. In other words, it is much more curved in one direction than in the other direction.
Clearly, GD has a much more difficult time on the deep and narrow surface.
Surfaces like this are often described as valleys, trenches, canals or ravines.
How can we recognize when a loss surface has this bad “deep and narrow” property?
The amount of curvature in each direction of the loss surface is determined by the eigenvalues of the associated matrix.
The eigenvalues of \(A\) are 1 and 1, while the eigenvalues of \(B\) are 20 and 1.
So the loss surface becomes challenging for gradient descent when the ratio of the largest and smallest eigenvalues grows.
This quantity is important enough that it has a name.
The ratio of the largest eigenvalue to the smallest eigenvalue of a matrix is called its condition number.
That is, for a matrix \(A\) with eigenvalues \(\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_n\), we define
as the condition number of \(A\).
So the condition number of our \(A\) is one (the best possible), while the condition number of \(B\) is 20 (not great).
Because \(B\) has a (relatively) large condition number, we say \(B\) is “ill conditioned,”
and also that the loss surface of \(\mathbf{x}^TB\mathbf{x}\) is “ill-conditioned.”
It is not uncommon in practice to encounter matrices with condition numbers in the hundreds or thousands, so the problem we are looking at here can get much worse than these visualizations suggest.
So the problem is that ill-conditioned loss surfaces pose challenges for gradient descent: on those surfaces, it can be slow to converge.
Let’s look at the convergence of GD on these two surfaces:
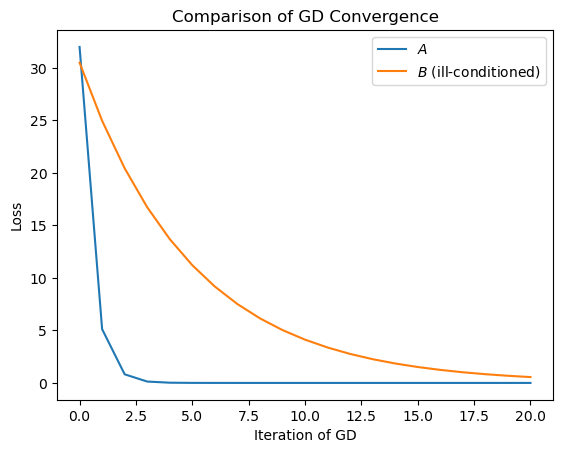
So indeed, the back-and-forth behavior of GD on the \(B\) surface is leading to slow convergence.
What Can be Done?#
Let’s recall the basic idea of gradient descent:

If you were performing gradient descent in the mountains, you would:
Look around you 360 degrees.
Observe in which direction the ground is sloping downward most steeply.
Take a few steps in that direction.
Repeat the process
… until the ground seems to be level.
Notice that what you are doing after each step is stopping and starting off in a new direction.
Consider, instead, what would happen if a heavy ball were rolling down the hill instead.
Although the ball would tend to follow the downhill direction, it would also have momentum that would factor in to the direction that it takes.
The momentum of the ball at a given moment is a reflection of the past gradients (really forces) that the ball has experienced.
So on an ill-conditioned surface, the conflicting gradients on either side of the “valley” can get averaged out by the ball, and before long the ball will be rolling down the “center” of the valley.
This thought experiment suggests that, rather than using just the gradient direction at each step, we should use a running average of gradients in the recent past.
A simple way to do this is called “exponentially weighted moving average” (EWMA).
This method is called, not surprisingly, Gradient Descent with Momentum.
It is actually very simple to implement. Instead of using the gradient at each step, we use its exponentially weighted moving average.
We’ll use the variable \(\mathbf{b}\) to hold the EWMA of the gradient.
Start with
an initial parameter estimate \(\mathbf{w}^0\),
a learning rate \(\eta > 0\),
\(\mathbf{b}^0=\mathbf{0}\),
and a momentum factor \(0 < \mu < 1\).
Compute EWMA of gradient:
\(\mathbf{b}^{n+1} = \mu \cdot \mathbf{b}^{n} + \nabla_\mathbf{w}\mathcal{L}(\mathbf{w}^{n})\)Update:
\(\mathbf{w}^{n+1} = \mathbf{w}^n - \eta \cdot \mathbf{b}^{n+1}\)If not converged, go to step 2.
And we can see that the implementation isn’t too different from regular gradient descent:
def gradient_descent(A, beta_hat, eta, nsteps = 1000):
losses = [qf(A, beta_hat)]
betas = [beta_hat]
#
for step in range(nsteps):
#
# the gradient step
new_beta_hat = beta_hat - eta * gradient(A, beta_hat)
beta_hat = new_beta_hat
#
# accumulate statistics
losses.append(qf(A, new_beta_hat))
betas.append(new_beta_hat)
return np.array(betas), np.array(losses)
def gradient_descent_mom(A, beta_hat, eta, mu, nsteps = 1000):
losses = [qf(A, beta_hat)]
betas = [beta_hat]
b = 0
#
for step in range(nsteps):
#
# the momentum gradient step
b = (mu * b) + gradient(A, beta_hat)
new_beta_hat = beta_hat - eta * b
beta_hat = new_beta_hat
#
# accumulate statistics
losses.append(qf(A, new_beta_hat))
betas.append(new_beta_hat)
return np.array(betas), np.array(losses)
Notice that to use momentum, we need a new hyperparameter, \(\mu\).
The value of \(\mu\) should be between 0 and 1; a value of zero results in regular gradient descent, and larger values incorporate more momentum. For some problems, values of \(\mu\) as large as 0.99 or 0.999 may be needed.
Like any hyperparameter, \(\mu\) is best set by cross-validation.
OK, so let’s look at how GD with Momentum does on our ill-conditioned surface:
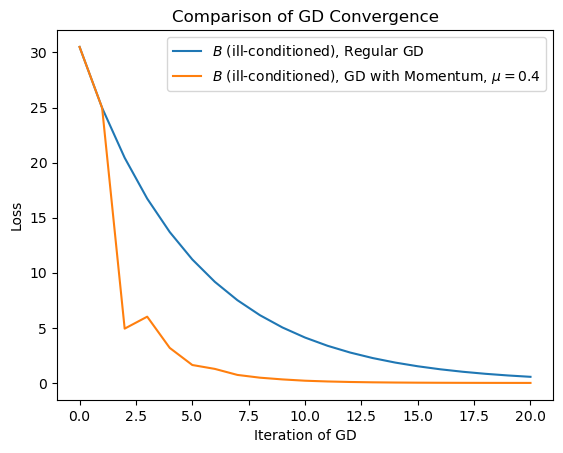
Clearly, momentum makes a huge difference!
You can see that the very first step taken by the momentum version is the same as regular GD.
However, after that, the influence of previous gradients helps guide the process toward the minimum very quickly.
To visualize the benefit of momentum, let’s compare GD with and without momentum on the ill-conditioned loss surface:
Looking at the case with momentum, one can see how the “ball rolling downhill” gradually settles in to the valley, and soon starts to follow the valley down directly.
What momentum has done is reduce oscillations that occur on a poorly conditioned surface.
Local Minima#
The second problem associated with regular Gradient Descent has to do with local minima.
Recall that unlike a convex function, a non-convex loss function can have multiple local minima.
This mean that the first local minimum found is not guaranteed to be the global minimum.
At the local minimum, the gradient of the cost function will be very small or zero. Because of this, gradient descent will get stuck and fail to find the global optimal solution.
To see the effect of local minima, let’s look at an example in 1D.
Let’s use this as a loss function of a single variable \(x\):
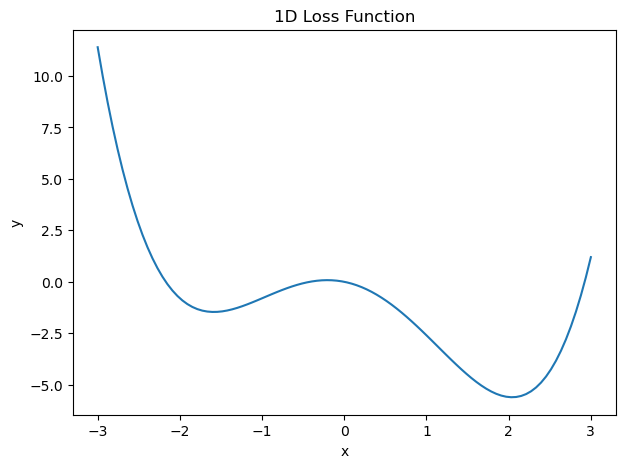
Let’s look at how regular GD behaves on this “surface”:
This is what we expect from regular GD: it moves downward into the first local minimum that it finds.
However, this isn’t good: we are in a local minimum, and we have not found the better solution at the global minimum.
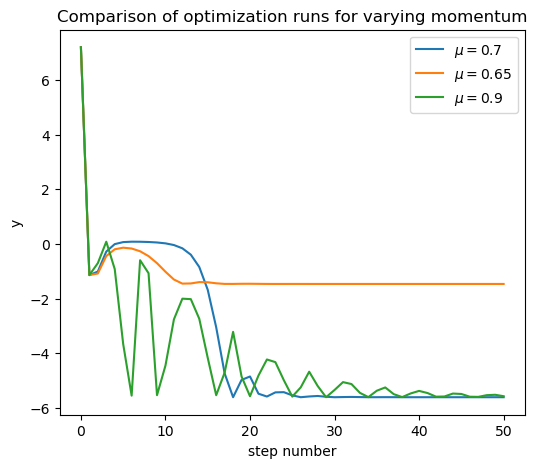
Now let’s try adding momentum. We’ll use a momentum parameter of \(\mu = 0.7\).
This is much better!
Notice how adding momentum causes the solver to move past the local minimum and find the global minimum.
This, momentum has a second beneficial effect on gradient descent: it can allow GD to escape local minima.
While this behavior is desirable, there is unfortunately no simple relationship between the value of the momentum parameter \(\mu\) and the quality of the final solution.
For example, if we use \(\mu = 0.65\) (a little less momentum), we observe:
In this case, the solver does not benefit from enough momentum to escape the local minimum. No improvement over regular GD.
On the other hand, if we use a larger amount of momentum (\(\mu = 0.9\)) we observe:
In this case, the solver finds the global minimum, but “rolls” back and forth in the valley, thus taking a long time to converge to the true minimum
In Practice#
Remember that in practice, you cannot “see” the actual loss surface.
Instead, the best you can do is plot the value of the loss function as a function of the number of steps the algorithm has taken.
For example, in the case we’ve been studying the best you could do would be to generate a plot like this:
Notice how these curves seem to get worse, then better, repeatedly. It can be tricky to decide when to “stop” the optimization, and how exactly the \(\mu\) parameter relates to the quality of the solution.
Slow Gradient Computation#
The third problem we’ll look at is the cost of computing gradients.
Why is the gradient expensive to compute?
Consider a machine learning setting where we are trying to optimize a loss function.
We have a set of data points \(\mathbf{x}_i\) and their labels. We are trying to learn a model \(f_\theta(\mathbf{x})\) such that for each \(\mathbf{x}_i\), \(f_\theta(\mathbf{x}_i)\) is a good approximation to \(y_i\).
Then we can write our loss function as:
where \(d()\) is some dissimilarity (error) measure.
The gradient of this loss funcion is
Now, if we have a lot of data, the number of data points is large and the sum in the above expression has many terms.
For a large dataset, that means that computing the gradient can take a lot of time.
Now by the rules of differentiation, the desrivative of a sum is the sum of the derivatives, so:
This shows that the gradient of a loss function is made up of one term for each data point.
The term for each data point is simply the gradient that would exist if that were the only data point.
As we discussed last time, this suggests the use of stochastic gradient descent.
The idea of stochastic gradient descent is:
Instead of computing the gradient based on all the data, compute it based on a single data point.
Take a step in the direction of that gradient.
Then repeat the above, iterating over every data point.
In the last lecture, we ran stochastic gradient descent on a least-squares problem:
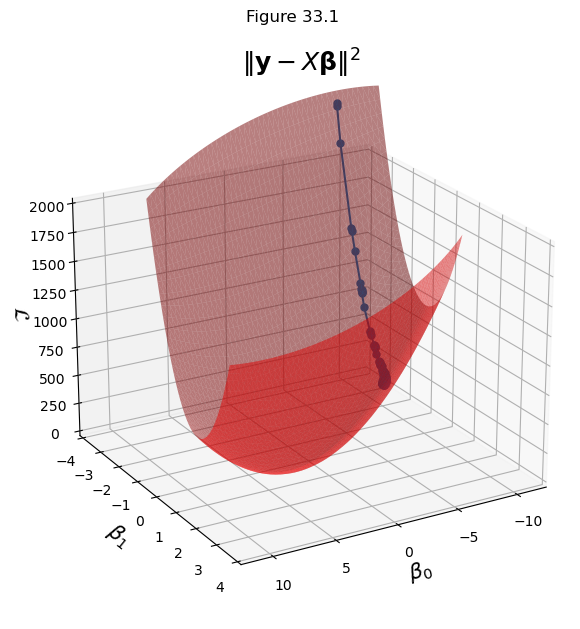
This strategy goes a long way to reducing the cost of computing gradients.
However, it’s not perfect.
Notice that, because the gradient at each step is based only on a single data point, the solver’s progress is erratic, and it tends to wander away from the true gradient. It is not as efficient as it could be.
We can see this by looking at estimates of the parameters over time:
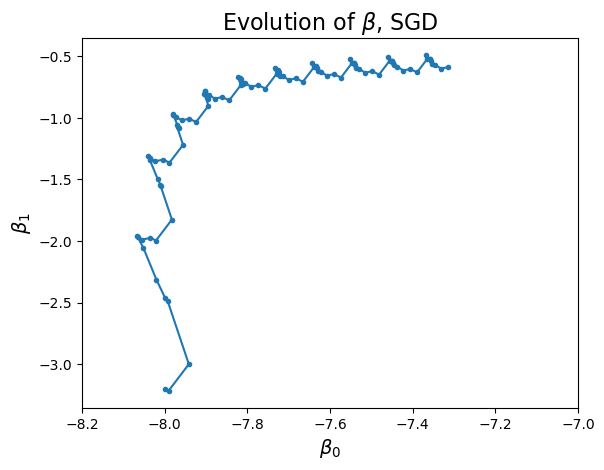
However, this erratic behavior can be reduced by …
… you guessed it, momentum.
Let’s apply stochastic gradient descent with momentum:
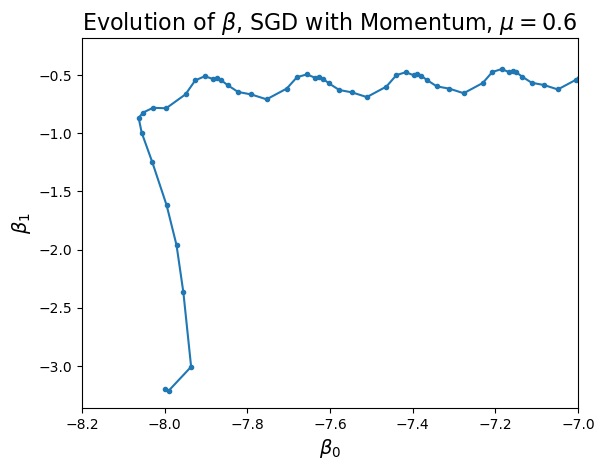
Turns out momentum is just what we need to “smooth out” the erratic behavior of stochastic GD, and as a result stochastic GD converges faster with momentum:
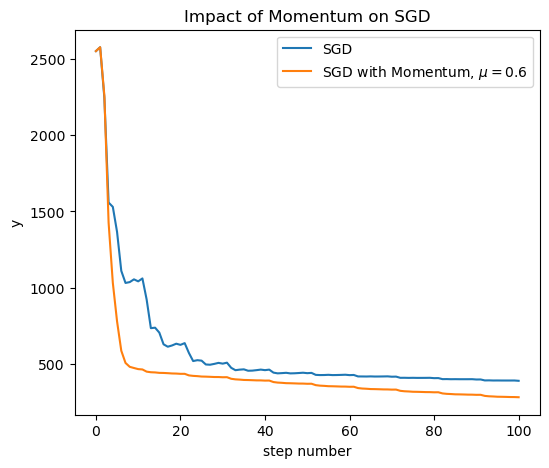
Conclusion#
We conclude that momentum is a powerful addition to gradient descent (regular or stochastic).
It is quite easy to implement, and it helps with three major problems that regular gradient descent encounters:
Slow convergence on ill-conditioned loss functions
Avoidance of local minima
Erratic behavior of stochastic gradient descent
And of course, people have thought about gradient descent methods a lot!
There are many possible other ways to improve on the general algorithm, which I am sure all of you will encounter in real world applications. For example, you could dynamically change the learning rate (“annealing”) or use per-parameter learning rates.
But the fundemental principles and code are virtually the same!