Introduction to Parameter Estimation
Contents
Introduction to Parameter Estimation#
The goal of statistical analysis is to extract useful information from data. Parameter estimation is an umbrella term for a set of tools for statistical analysis.
We will be discussing parameter estimation this and next week. In today’s lecture we will introduce point estimation, learn the techniques to analyze the quality of point estimators, and even derive theoretical guarantees on their performance.
Parameter Estimation#
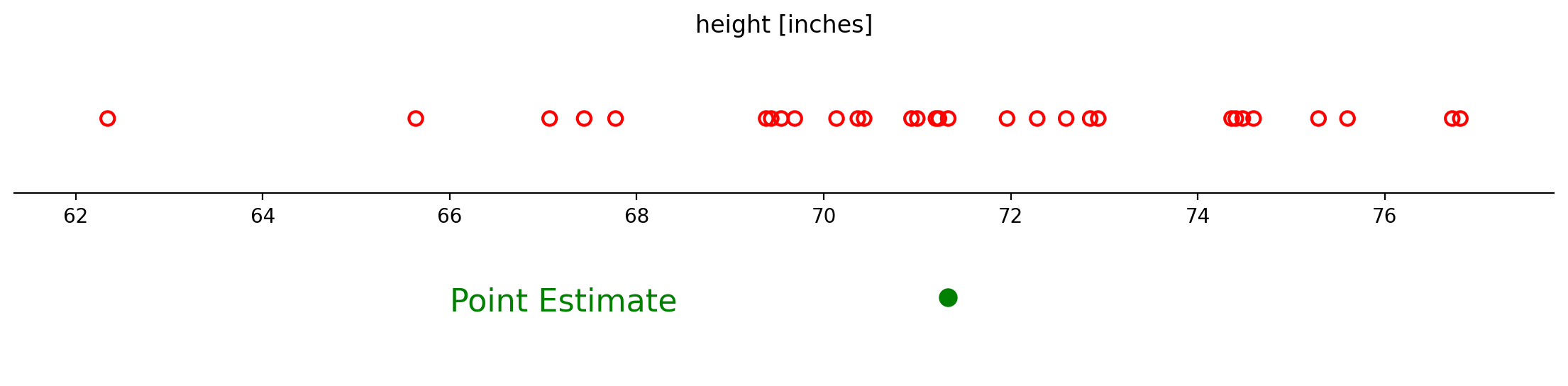
Example. We are studying the variance of height among male students at BU. Our sample of size 30 is shown below. We want to fit normal distribution \(\mathcal{N}(\mu, \sigma^2)\) to this data.
What values should we choose for \(\mu\) and \(\sigma\)?

Here, \(\mu\) and \(\sigma\) are the population parameters. They are fixed but unknown.
Parameter estimation is inference about an unknown population parameter (or set of population parameters) based on a sample statistic.
Parameter estimation is a commonly used statistical technique. For instance, traffic engineers estimate the rate \(\lambda\) of the Poisson distribution to model light traffic (individual cars move independently of each other). Their data constists of the counts of vehicles that pass a marker on a roadway during a unit of time.
In other words, we need parameter estimation when we are given some data and we want to treat it as an independent and identically distributed (or i.i.d.) sample from some population. The population has certain parameters, such as \(\lambda\) in the above example or \(\mu\) and \(\sigma\) in the example of height among male students at BU.
We will use \(\theta\) (which can be a scalar or a vector) to represent the parameter(s). For example, we could have \(\theta = (\mu, \sigma).\)
Point Estimation#
Example. The sample average of 71.3 inches is a point estimate of the average height of male students at BU.
A point estimator is a statistic that is used to estimate the unknown population parameter and whose realisation is a single point.
Definition. Let’s say our data is \(x_1, \dots, x_m\). A point estimator can be any function \(g\) of the data:
We’ll use the hat notation (\(\hat{\theta}\)) to indicate a point estimator of \(\theta\).
Note: The above definition does not require that \(g\) returns a value that is close to the parameter(s) \(\theta\). So any function qualifies as an estimator. However, a good estimator is a function whose output is close to \(\theta\).
In the frequentist perspective on statistics, \(\theta\) is fixed but unknown, while \(\hat{\theta}\) is a function of the data. Therefore, \(\hat{\theta}\) is a random variable which has a probability distribution referred to as its sampling distribution (we introduced sampling distributions in the lecture on sampling).
This is a very important perspective to keep in mind; it is really the defining feature of the frequentist approach to statistics!
Recall that the sampling distribution of a statistic is the probability distribution of that statistic when we draw many samples.
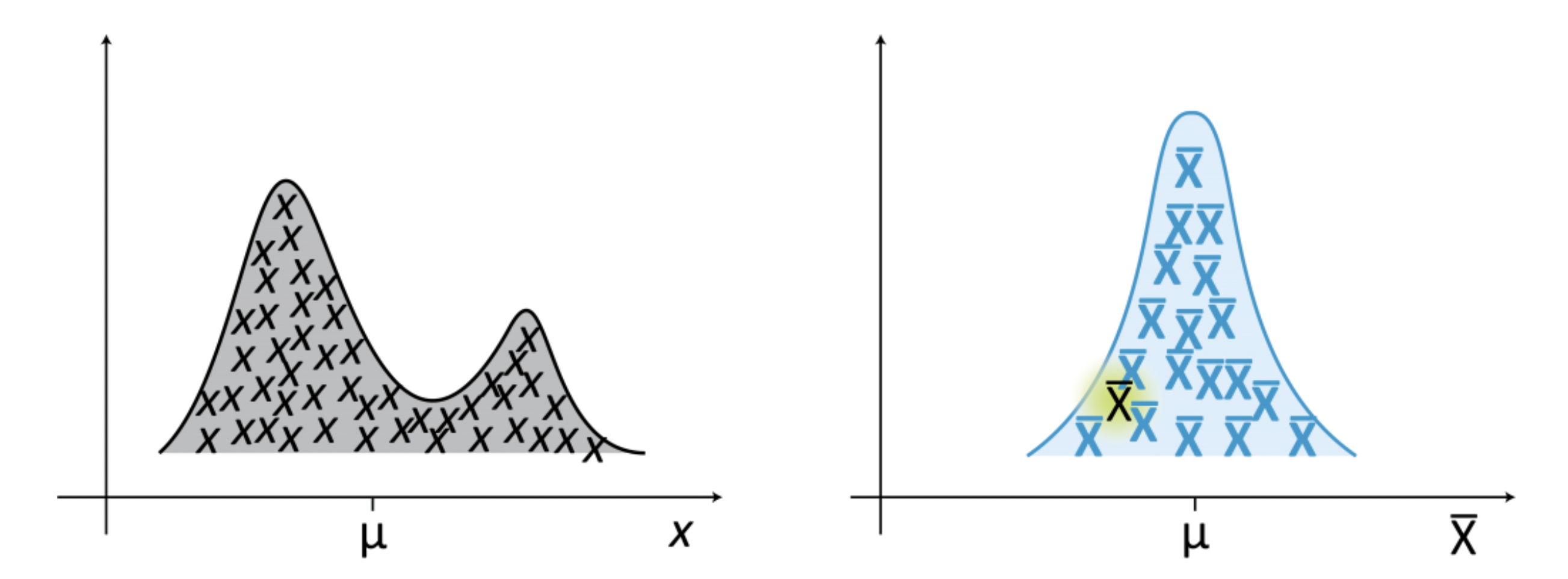
The figure shows a population distribution (left) and the corresponding sampling distribution (right) of a statistic, which in this case is the mean. The sampling distribution is obtained by drawing samples of size n from the population.
Recall that Bernoulli random variable has
only two outcomes: 0 and 1,
one parameter \(p\), which is the probability that the random variable is equal to 1,
mean equal to \(p\) and variance equal to \(p(1-p)\),
PMF: \(p^x(1-p)^{(1-x)}.\)

Example. Consider data sample \(x_1, \dots, x_m\) drawn independently and identically from a Bernoulli distribution with mean \(\theta\):
A common estimator for \(\theta\) is the mean of the realizations:
Bias and Variance#
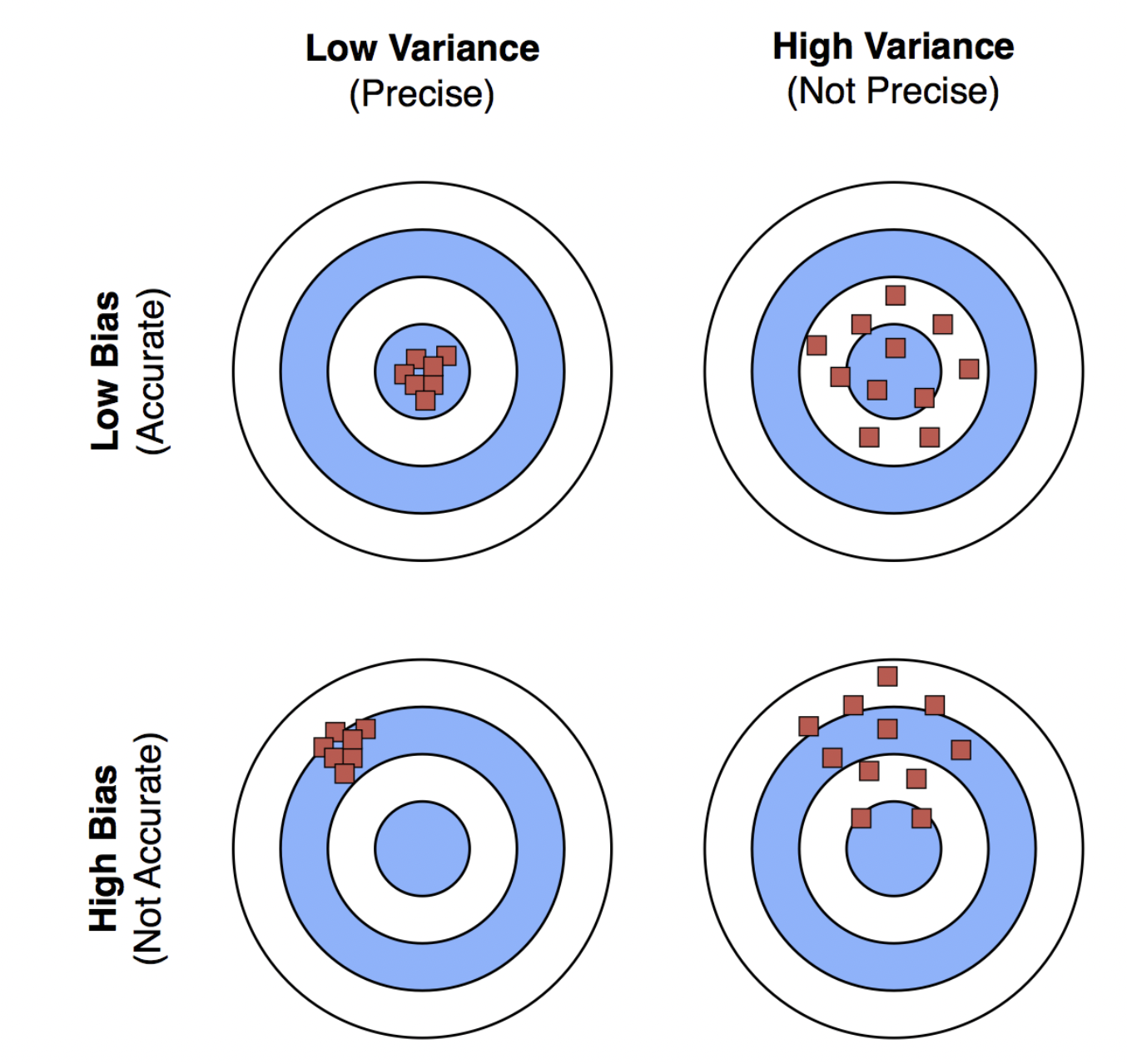
We use two criteria to describe an estimator: bias and variance.
Bias measures the difference between the expected value of the estimator and the true value of the parameter, while variance measures how much the estimator can vary as a function of the data sample.
Definition. The bias of an estimator is defined as:
where the expectation is over the data (seen as realizations of a random variable) and \(\theta\) is the true underlying value of \(\theta\) used to define the data-generating distribution.
An estimator is said to be unbiased if \( \operatorname{bias}\left(\hat{\theta}\right) = 0\), or in other words \(E\left[\hat{\theta}\right] = \theta\).
Continuing our example for the mean of the Bernoulli:
So we have proven that this estimator of \(\theta\) is unbiased.
Definition. The variance of an estimator is simply the variance
where \(g\left(x_1, \dots, x_m\right)\) is a function of the data set.
Remember that the data set is random; it is assumed to be an i.i.d. sample of some distribution.
Recall:
I. If \(\operatorname{Var}(X)\) exists and \(Y=aX+b\), then \(\operatorname{Var}(Y) = a^2\operatorname{Var}(X)\).
II. If \(X_1, X_2, \dots, X_m\) are i.i.d., then \(\operatorname{Var}\left(\sum_{i=1}^m X_i \right)= m\operatorname{Var}\left(X_1\right).\)
Let us return again to our example where the sample is drawn from the Bernoulli distribution and the estimator \(\hat{\theta}_m = \frac{1}{m}\sum_{i=1}^m x_i\) is simply the mean of \(m\) observations.
So we see that the variance of the mean is:
This has a desirable property: as the number of data points \(m\) increases, the variance of the estimate decreases.
Note: It can be shown that for a sample \(x_1, \dots, x_m\) drawn independently and identically from any population with mean \(\mu\) and variance \(\sigma^2\). The sample mean, \(\frac{1}{m}\sum_{i=1}^m x_i\), is an unbiased estimator of the population mean and has variance \(\frac{\sigma^2}{m}\).
What if we use \(\hat{\beta}_m = c\), where \(c\) is a constant, to estimate the population mean in our Bernoulli example?
The variance of this estimator is equal to
However, the bias in this case is equal to
The estimator \(\hat{\beta}_m = c \:\) is biased.
Mean Squared Error#
Consider two estimators, \(g\) and \(h\), each of which are used as estimates of a certain parameter \(\theta\).
Let us say that these estimators show the following distributions:
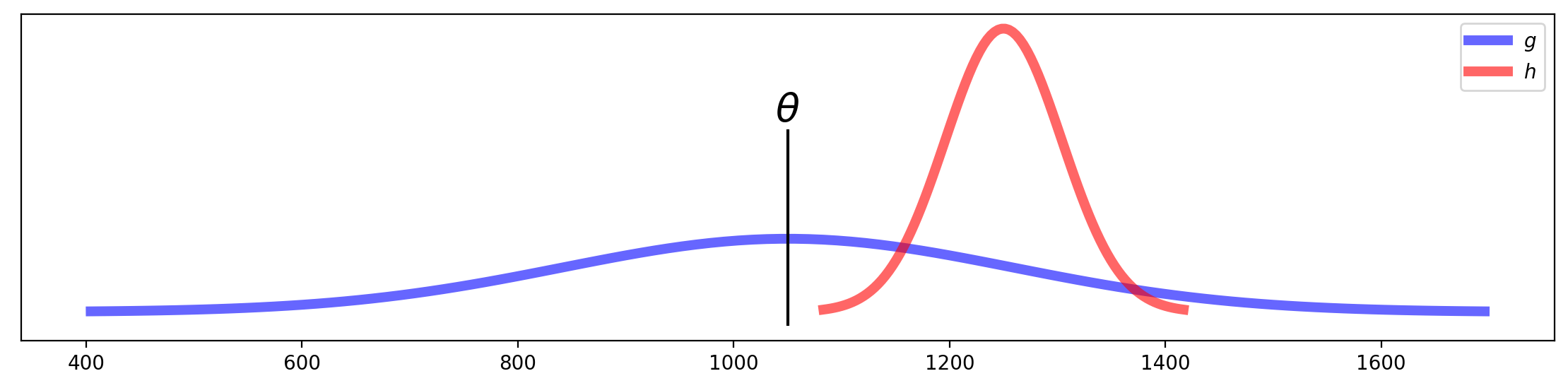
The figure shows that estimator \(h\) has low variance, but is biased. Meanwhile, estimator \(g\) is unbiased, but has high variance.
Which is better?
The answer of course depends, but there is a single criterion we can use to try to balance these two kinds of errors.
It is mean squared error (MSE).
This measures the “average distance squared” between the estimator and the true value.
It is a good single number for evaluating an estimator, because it turns out that:
We have already shown that for sample \(x_1, \dots, x_m\) that is drawn independently and identically from a Bernoulli distribution with mean \(\theta\), the estimator \(\hat{\theta}_m = \frac{1}{m}\sum_{i=1}^m x_i\) is unbiased and and has variance \(\frac{1}{m}\theta (1-\theta)\). Therefore,
Finally, we need to mention that the two estimators \(g\) and \(h\) in the plot above have approximately the same MSE. Therefore, the MSE does not always indicate which estimator should be used. In a couple of lectures we will learn a number of other properties of estimators that can be used to choose the best estimator. In particular, we will talk about consistency, efficiency, and sufficiency of estimators.
Sample Variance#
Consider the following i.i.d. data sample of size 35.
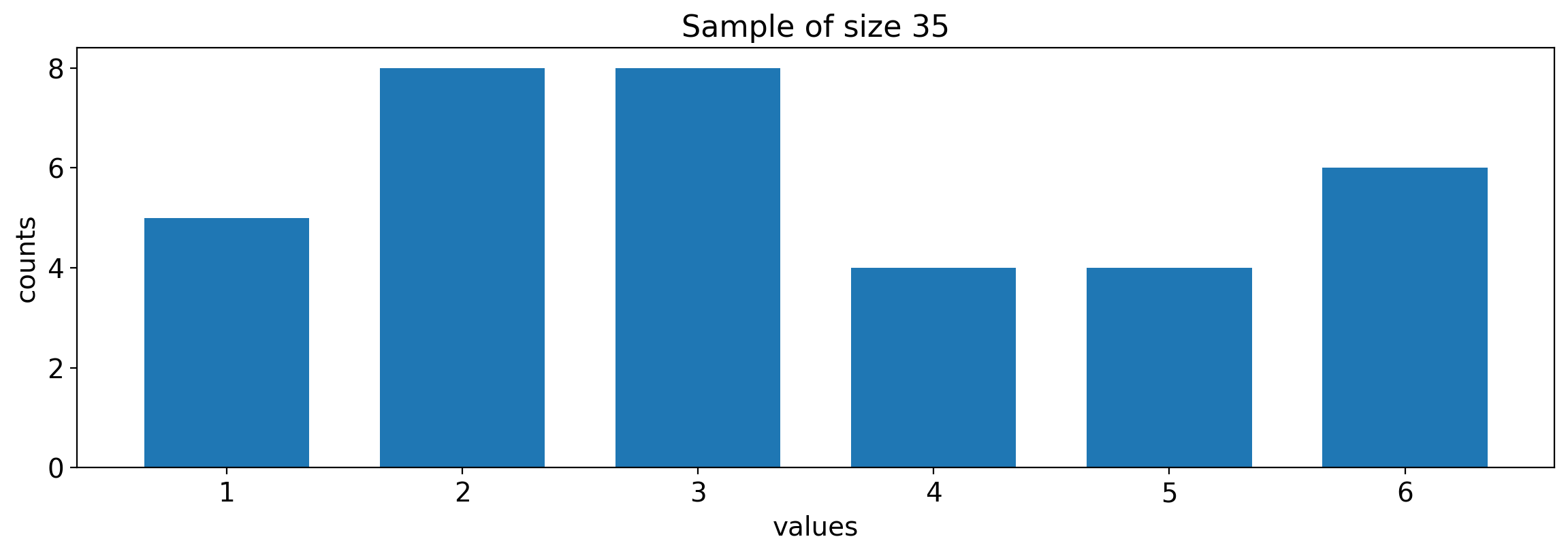
Is the sample from a discrete uniform distribution? Do the values range from 1 to 6?
Discrete uniform distribution:

\(n = b - a +1\)
parameters: \(a\) and \(b\)
mean: \(\frac{a+b}{2}\)
variance: \(\frac{n^2-1}{12} = \frac{(b - a +1)^2 -1}{12}\)
If the population distribution is \(U(1,6)\), the population mean should be equal to 3.5 and the population variance should be approximately 2.917.
We can use the provided sample to estimate the population mean and variance.
Note: We are not fitting \(U(1,6)\) to the sample. We are simply looking for point estimates for the population mean and variance.
We discussed earlier that regardless of the population distribution, the sample mean is an unbiased estimator of the population mean and its variance is inversely proportional to the size of the sample.
Thus we will use the sample average to estimate the population mean:
# compute the sample mean
mu_hat = np.mean(s)
print(f'The estimate of the population mean is equal to {mu_hat:.4}.')
The estimate of the population mean is equal to 3.343.
What about the population variance? Can it be estimated by
# compute the variance of the sample (without Bessel's correction)
sig2_hat_1 = np.var(s, axis = 0, ddof = 0)
print(f'The variance estimate is equal to {sig2_hat_1:0.4}.')
The variance estimate is equal to 2.797.
We will see later in this lecture that this estimator systematically underestimates the population variance. Bessel’s correction is required to obtain an unbiased estimator:
The above expression is known as sample variance.
# compute the sample variance (with Bessel's correction)
sig2_hat_2 = np.var(s, axis = 0, ddof = 1)
print(f'Sample variance is equal to {sig2_hat_2:0.4}.')
Sample variance is equal to 2.879.
Conclusion. Based on the provided sample, the population mean can be estimated by 3.343 and the population variance can be estimated by 2.879. These values are close to 3.5 and 2.917, respectively. Therefore, \(U(1,6)\) can be considered a “good guess” for the population distribution.
Effect of Bessel’s correction#
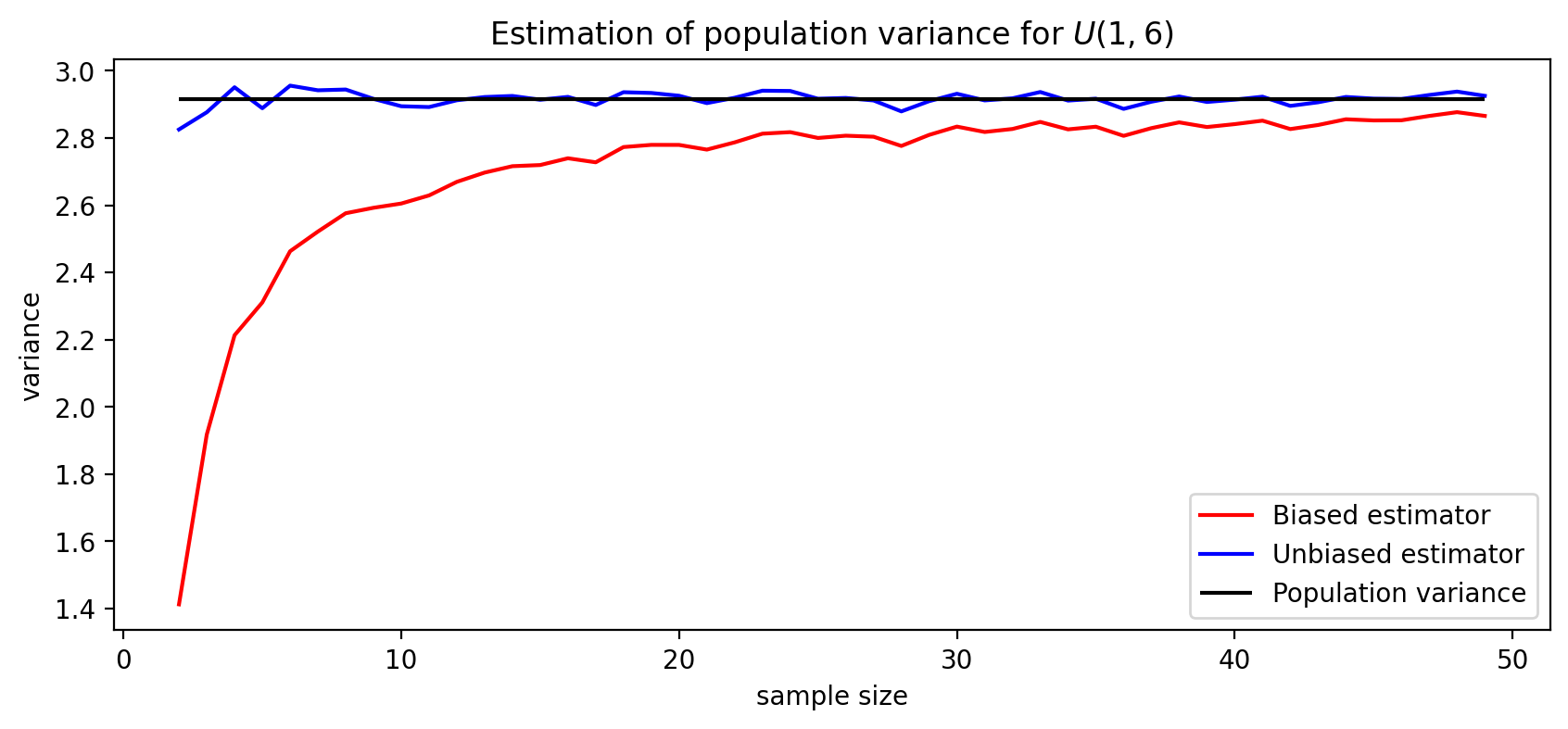
Note: The \(y\)-axis corresponds to the variance that is obtained by taking an average over 1000 samples for each sample size.
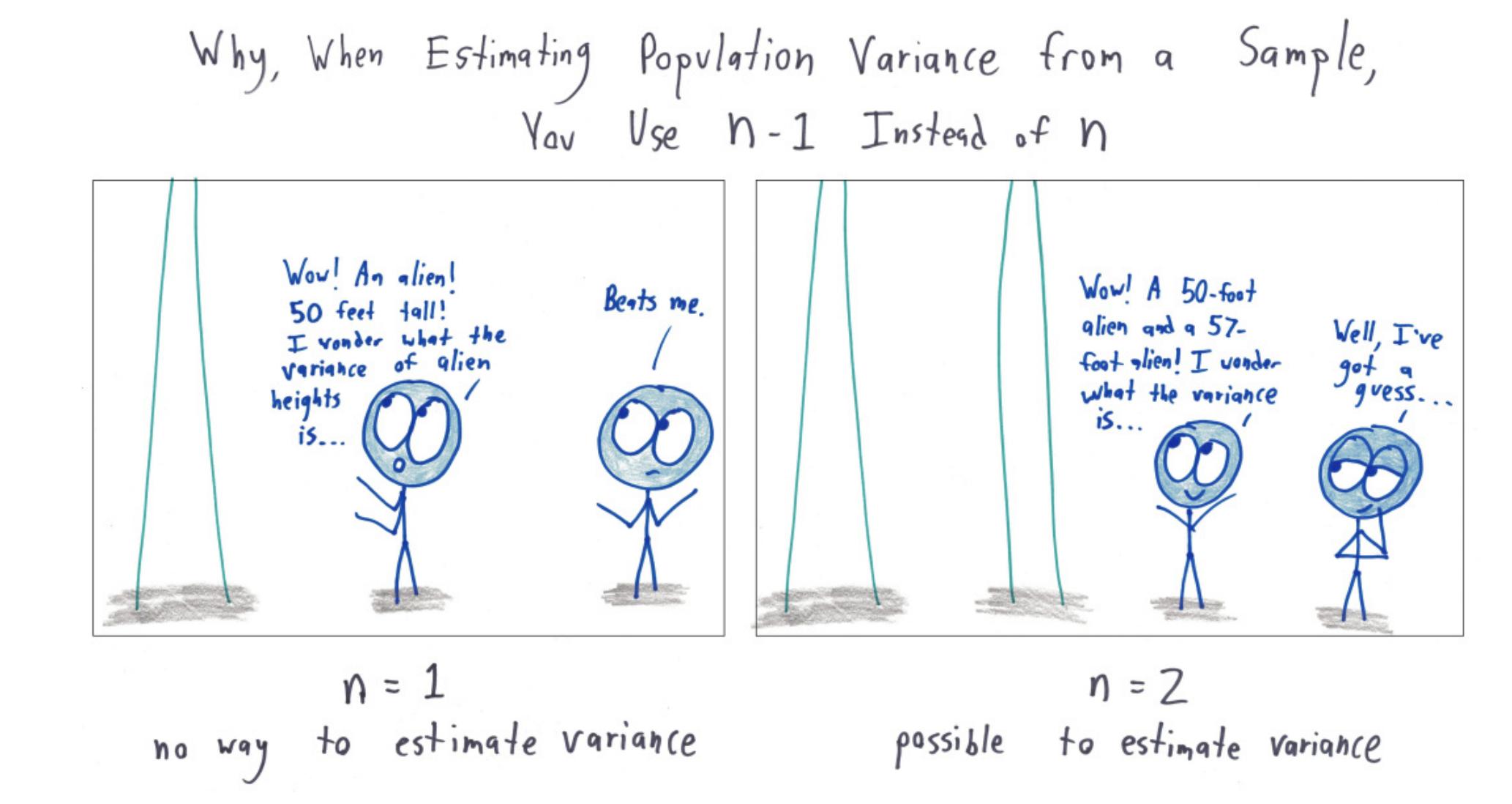
Intuition behind Bessel’s correction#