Confidence#
In this lecture we’ll use what we’ve learned so far to start to build reliable, defensible conclusions about data.
When working with data that is a sample of some population, it is always possible to compute statistics like the sample mean.
However, as data scientists, the crucial question to ask is: “How confident should I be that the sample mean represents the population?”
In other words, just because I can compute a sample mean, does it really tell me anything?
Let’s make this question more precise.
Today we will exclusively focus on estimating the true mean of a population, given a sample.
So, to start, let’s say we have obtained a sample \(x_i, i = 1,\dots, n\).
And we can compute the sample mean
So a more precise question would be: “How close is \(M\) to the population mean \(\mu\)?”
Now, even this question is not really precise enough. Remember that \(M\) is a random variable.
So the question “How close is \(M\) to the population mean \(\mu\)?” does not have a definite answer.
We can only answer this question probabilistically.
The way we phrase this is as follows.
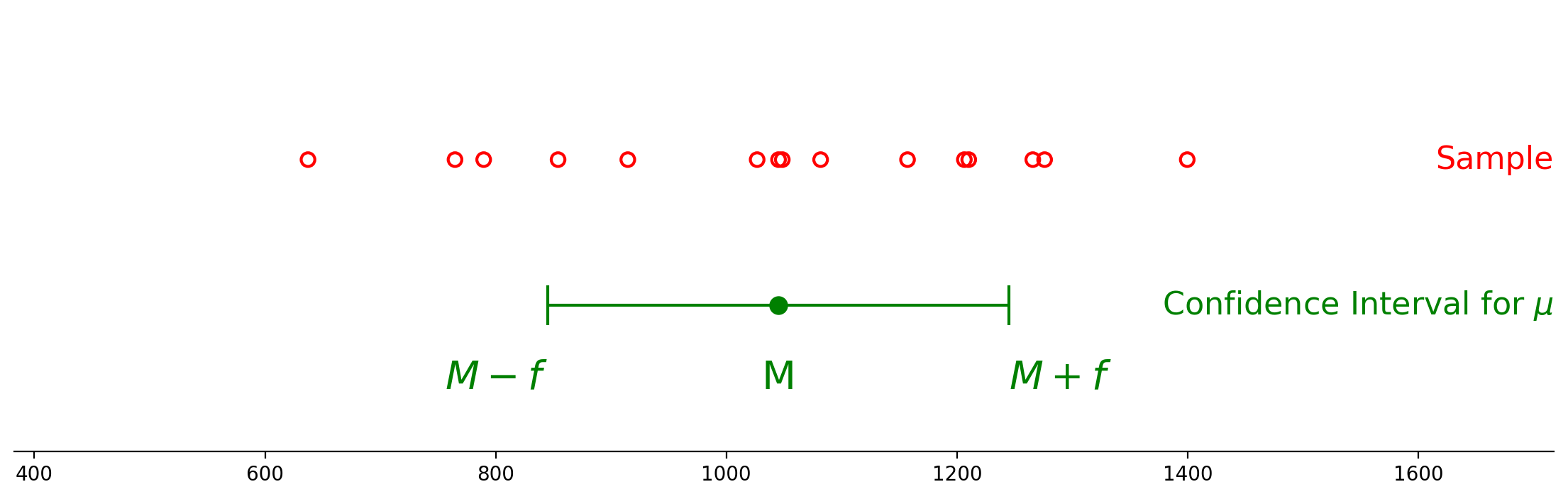
We fix an interval around \(M\), say \([M - f, M + f]\). Then we ask:
What is the probability that \(\mu\) lies within the interval \([M - f, M + f]\)?
In other words, we are asking:
What is \(P(M - f \leq \mu \leq M + f)\)?
Before we reason more about how to calculate this probabilty , let’s just quickly write down what it’s going to tell us:
Let’s assume that we can compute this probability for any given \(f\). (We will soon see how to do that.) Then we want to choose an \(f\) so that this probability is high enough that we are “confident” that the interval contains the population mean.
A good level of confidence is 95%. So our final question is:
What is \(f\), so that \(P(M - f \leq \mu \leq M + f) = 0.95\)?
When we find that \(f\) – let’s call it \(f_{95}\) – we can then construct the interval \([M - f_{95}, M + f_{95}]\).
This can also be written as \(M \pm f_{95}.\)
This will be the 95% confidence interval for \(\mu\).
The Insight#
OK, we have turned the abstract question of
“How confident are we that \(M\) is close to \(\mu\)?”
into the concrete question
“What is \(P(M - f \leq \mu \leq M + f)\)?”
At first glance, this seems like a hard probability to compute. Keep in mind that \(\mu\) is some unknown, but fixed value. On the other hand, \(M\) is a random variable that depends on the sample that we took.
However, there is a clever insight that will get us on the right path.
Notice that when we ask the question:
“What is \(P(M - f \leq \mu \leq M + f)\)?”,
another way of saying this is
“What is the probability that the distance between \(\mu\) and \(M\) is less than \(f\)?”
In other words, “What is \(P(|M - \mu| \leq f)\)?”.
Now notice that this is the same thing as \(P(\mu - f \leq M \leq \mu + f)\).
In other words: if the distance between \(M\) and \(\mu\) is less than \(f\), then \(M\) lies between \(\mu - f\) and \(\mu + f\).
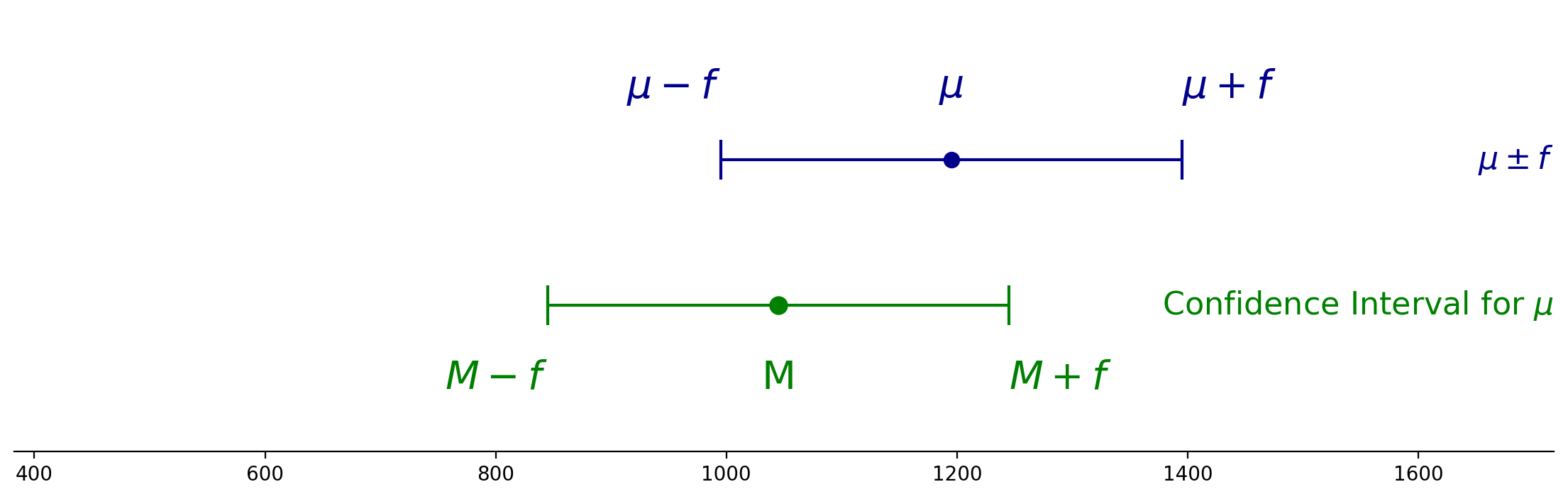
And putting the chain of reasoning together:
Now, here is the key observation: the last probability above is a question about a sampling distribution.
It is asking, “what is the probability that the mean of a sample lies within a distance \(f\) of the population mean?”
We studied this question in the last lecture.
So let’s see how to use what we know about sampling distributions to construct a confidence interval for \(\mu.\)
The Gaussian Case#
To start with, let’s assume that our population has a Gaussian (ie, normal) distribution.
And let’s continue to use the example of SAT scores that we discussed in the last lecture:
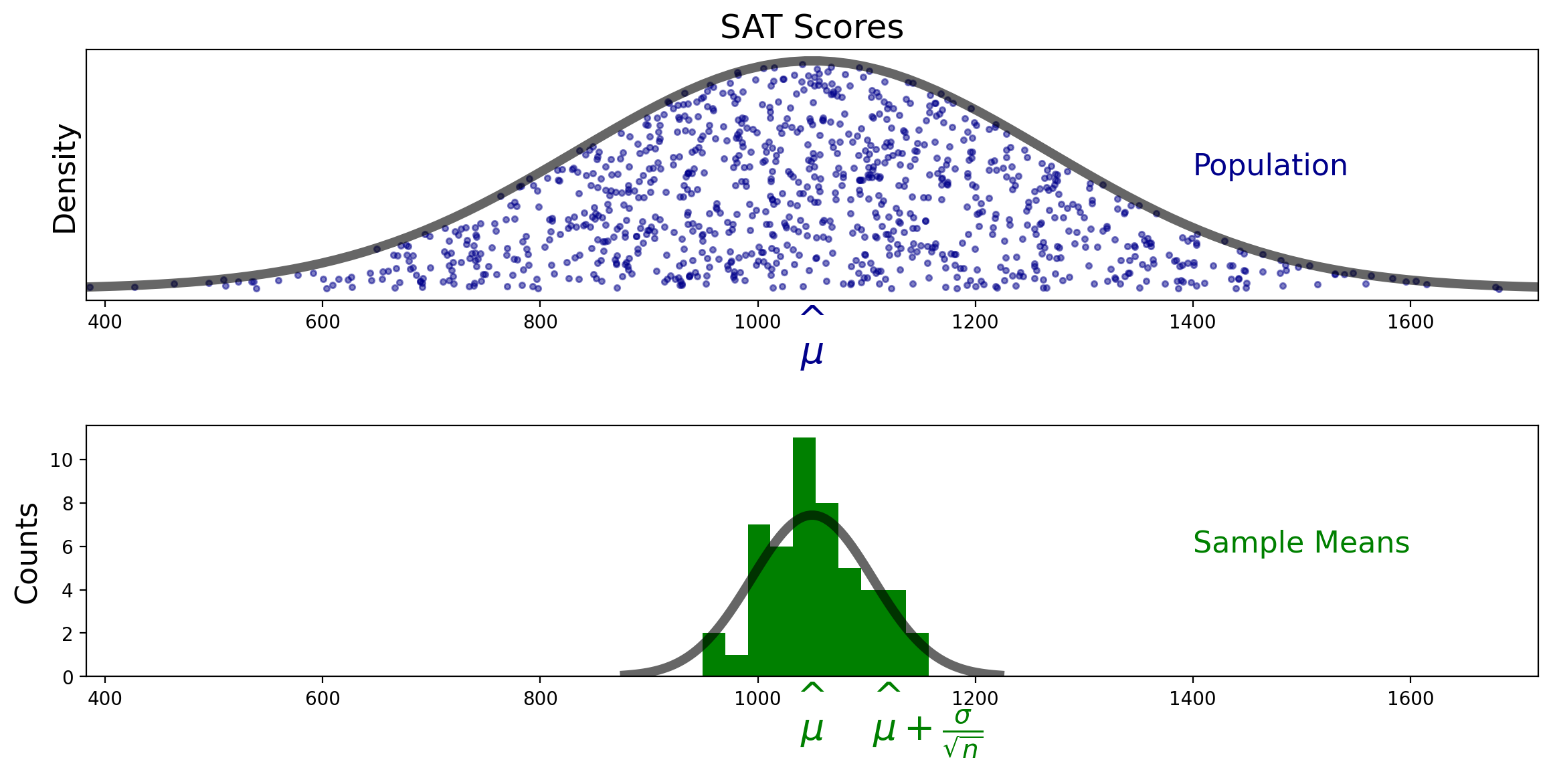
We know the distribution of sample means:
For now, let’s assume we know the population standard deviation \(\sigma\).
To find our \(f\) value, we want to know:
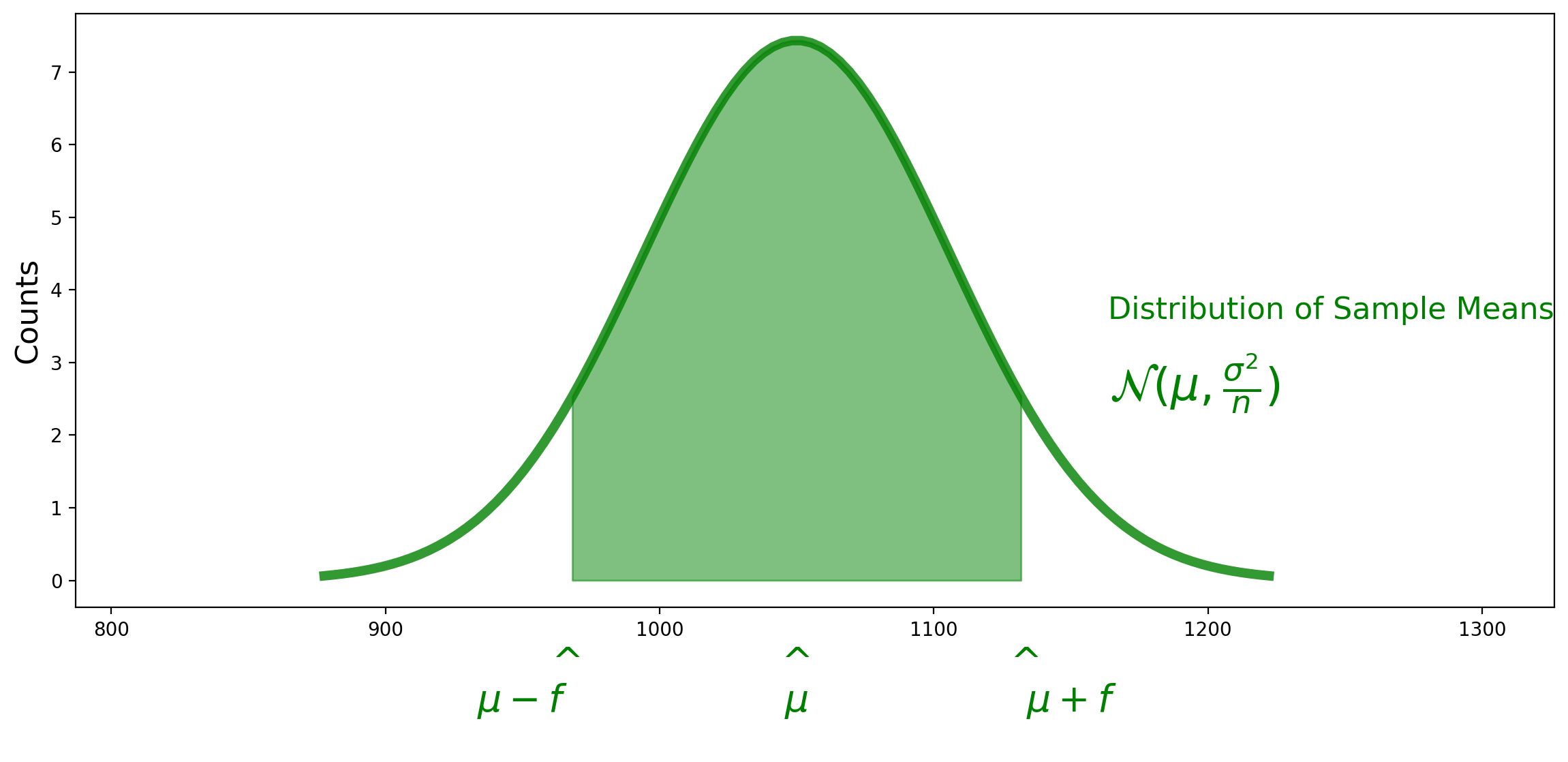
Importantly, this probability does not depend on \(\mu\)!
Because this probability only depends on the distance from \(\mu\), in the end all that matters is the standard deviation of \(M\).
Recall that the standard deviation of \(M\) is called the standard error and it is equal to \(\sigma/\sqrt{n}\).
So, still assuming we know \(\sigma\), we can calculate the 95% confidence interval for \(\mu\).
We are looking for the value \(f\) such that
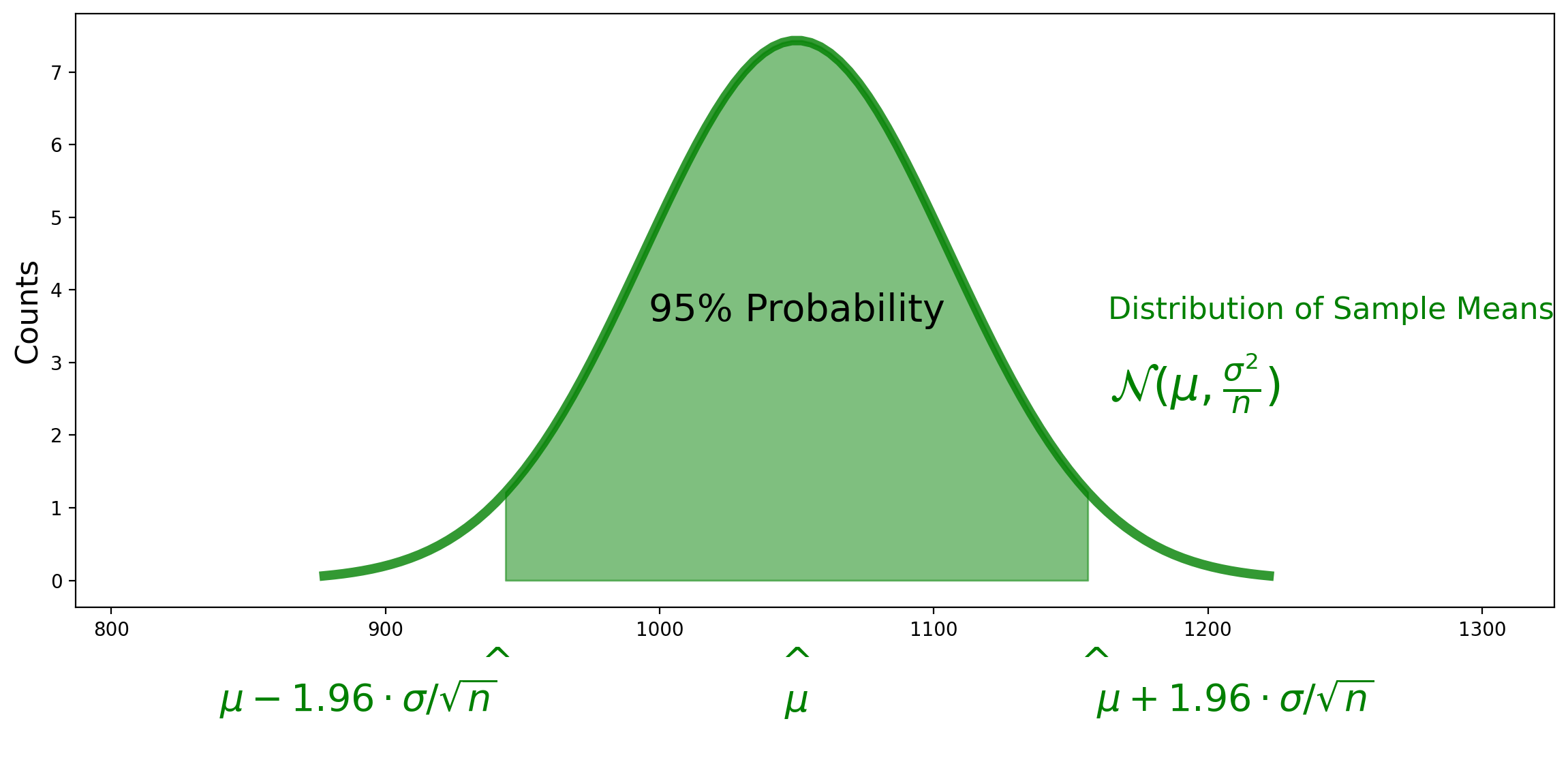
We can compute this from the formula for the normal distribution, and the answer is that \(f = 1.96 \cdot \sigma/\sqrt{n}\).
This number is called a z-statistic. We write: \(z_{0.975} = 1.96.\) We use 0.975 because we want 2.5% of the probability in each of the two tails.
So …
We can now compute the 95% confidence interval for the mean!
Set \(f = 1.96 \cdot \sigma / \sqrt{n}\).
Then:
So the final 95% confidence interval is:
And we are done!
Standard Errors#
Well, we are not quite done.
We assumed we knew \(\sigma\), the population standard deviation.
How will we compute \(\sigma\)?
The simple answer is that we will estimate \(\sigma\) from the data. That is, for \(\sigma\) we will use the sample standard deviation:
However, there is a slight caveat. This is known to be a biased estimate of the true standard deviation, so we typically apply a correction to get an unbiased estimate:
The exact reason for using \(n-1\) is outside the scope of this class (though some of you may still remember the reasoning from DS120). The intution is that we need a slightly larger variance because our calculation is based on the estimated mean and not the true mean of the population. Because we estimate the mean from the sample, we have lost a “degree of freedom.”
Do we introduce error when using \(s\) in place of \(\sigma\)?
The short answer is that when we have 30 or more samples (\(n \geq 30\)) then \(s\) is an acceptably close estimate of \(\sigma\).
When \(n < 30\) we use a correction factor. Instead of the \(z\) statistc (1.96), we use the \(t\) statistic, which you can look up in a table. The \(t\) statistic depends on \(n\) – we say it has \(n - 1\) “degrees of freedom.”
So you would look up the \(t\) statistic for \(n-1\) degrees of freedom and confidence level of 95%, and use that number in place of 1.96.
So our final recipe for computing a 95% confidence interval for \(\mu\) from a set of samples \(x_i\) that come from a normally distributed population is:
Sample mean:
Unbiased sample standard deviation:
Test statistic times standard error:
and voila:
Visualizing Samples and the Confidence Intervals#
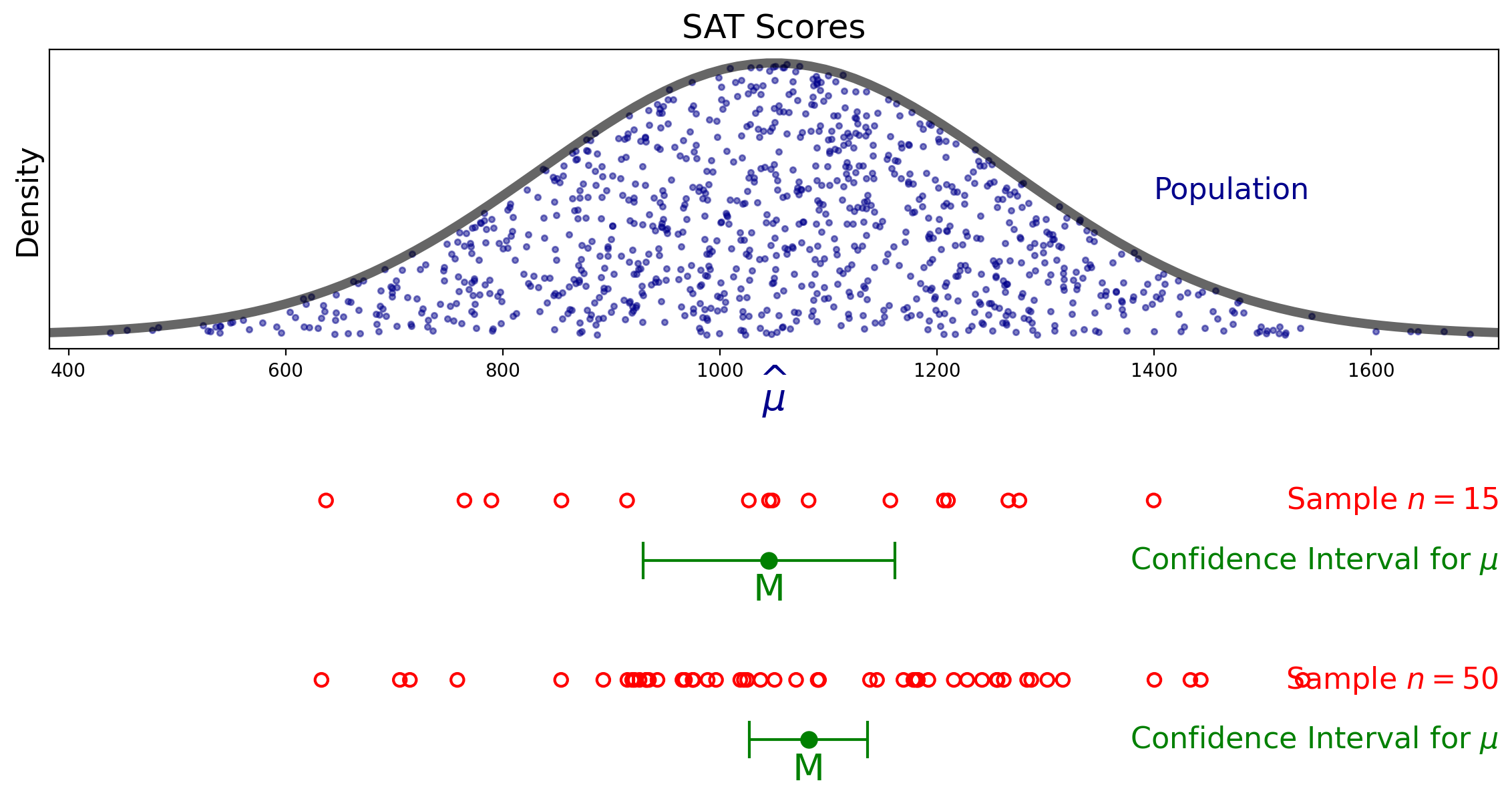
Here is an example of two samples from our population, and the associated confidence intervals.
Notice how the size of the confidence interval changes for different sample sizes.
When the Population is not Normal#
Now, we have so far been assuming that the population is normally distributed. This may seem like a very limiting assumption.
However, it turns out that in the majority of cases, the distribution of the population does not matter too much.
Here is why.
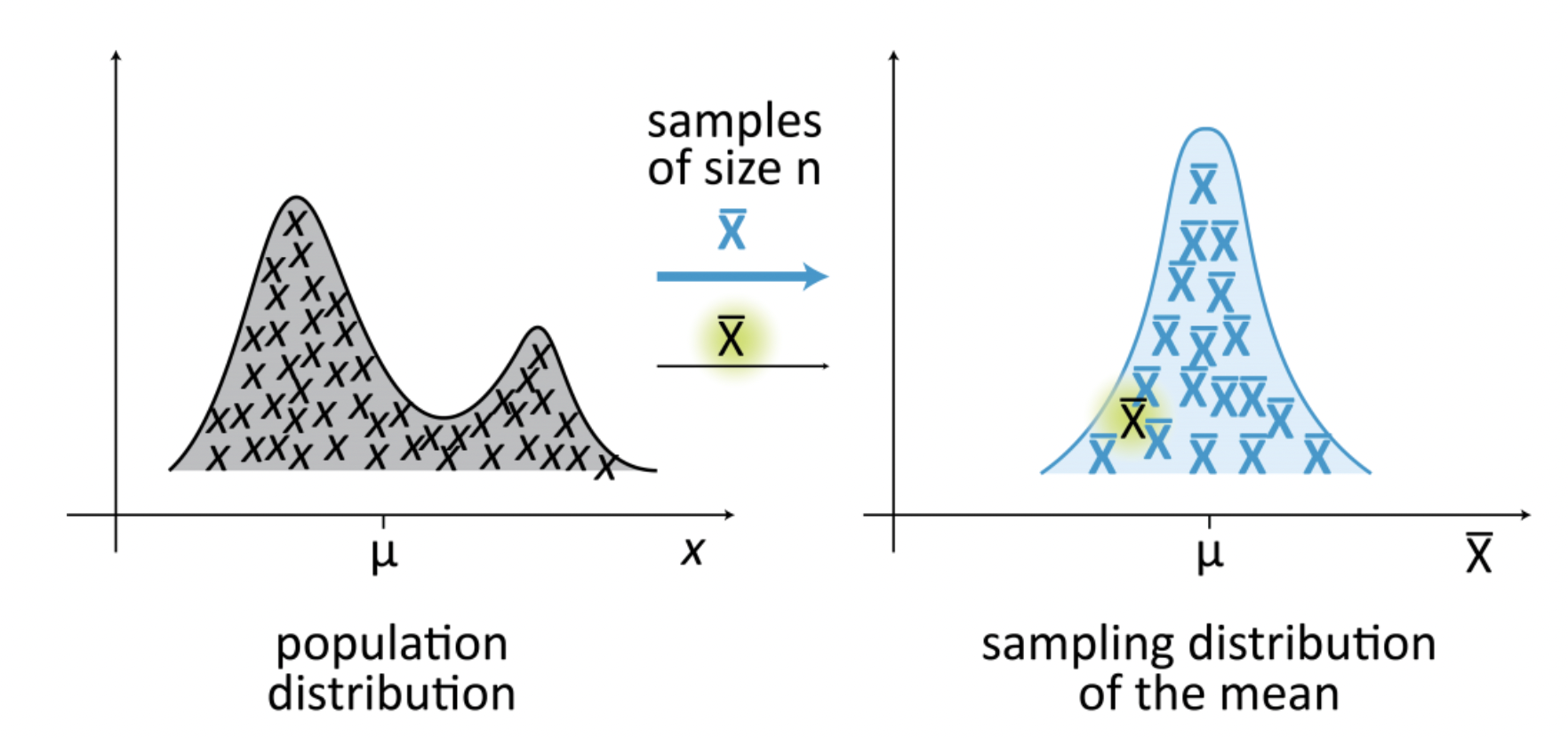
Recall that our sample statistic is
Now recall that the Central Limit Theorem tells us that for \(n\) large enough, the sum of \(n\) samples from any distribution is approximately normally distributed.
(A technical limitation: the underlying distribution must have finite variance. Most distributions you encounter in practice will have this property.)
How large should \(n\) be for us to be able to rely on the Central Limit Theorem?
The long answer is that it depends on the population distribution. A highly skewed distribution, or one with a large ratio of standard deviation to mean, will require larger sample sizes.
However, for most practical purposes, a sample size of \(n = 30\) is large enough to allow use of the normal distribution to describe the distribution of the sample mean.
Example. A pollster asks 196 people if they prefer candidate A to candidate B and finds that 120 prefer A and 76 prefer B. Find the 95% conservative normal confidence interval for \(p\), the proportion of the population that prefers A.
Solution.
The sample mean is
The sample standard deviation is
Since there are only two values of \(x_i\), 1 and 0, we can see that
So we conclude that the 95% confidence interval of support for candidate A is
In other words, 95% CI = [.544, .680].
Note that there are some simplifications to the above that we can make.
The standard deviation of the Binomial distribution is \(\sigma = \sqrt{p(1-p)}\). We notice that this is always less than or equal to 1/2.
So we could generate a conservative estimate of the confidence interval by using 1/2 in place of \(s\).
And let’s also use the approximation 2 in place of 1.96.
Then the 95% confidence interval becomes:
Notice that this confidence interval is slightly wider than the more precise one that uses the actual sample standard deviation.
However, it is much simpler to compute (and remember):
The 95% confidence interval for the Bernoulli is approximately \(M \pm \frac{1}{\sqrt{n}}\).
This leads to a simple rule for interpreting, eg polling data.
Political polls are often reported as a value with a margin-of-error. For example you might hear 52% favor candidate A with a margin-of-error of \(\pm\)5%.
The actual precise meaning of this is if \(p\) is the proportion of the population that supports A then the point estimate for \(p\) is 52% and the 95% confidence interval is 52% \(\pm\) 5%.
And you can estimate from this statement that the poll involved about
respondents, ie, \(n \approx 400\) respondents.
Notice that reporters of polls in the news do not mention the 95% confidence. You just have to know that that’s what pollsters do.
Interpreting Confidence Intervals#
What does the 95% confidence interval mean? How can we interpret it?
The simple answer is that about 95% of the time, the confidence interval you calculate using our recipe will contain the mean.
In other words, imagine you performed the sampling process 100 times, and each time you computed a confidence interval. Then you’d expect about 95 of those confidence intervals to include the mean.
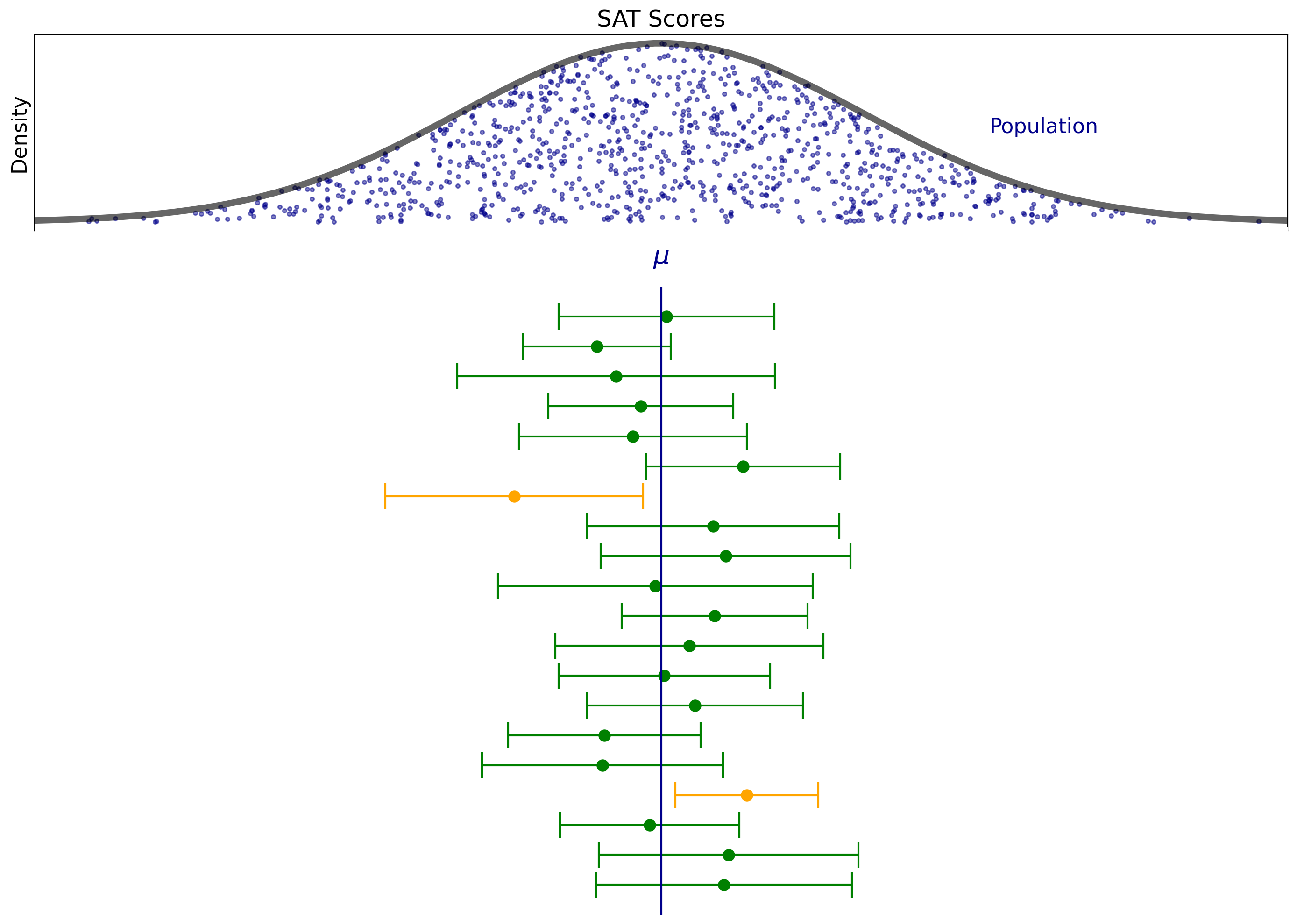
Here is an example of that process. Here we’ve repeated the sampling process 20 times.
Note how the confidence intervals dance around, and how their sizes vary.
Note that not every confidence interval contains the mean (the orange ones don’t).
However, roughly 95% of the confidence intervals will contain the mean.
There is a small technical point here: any time you compute a specific confidence interval, it either does or does not include the mean.
So it is not correct to say that “this confidence interval includes the mean with probability 0.95”.
But it quite correct to use the level of 0.95 as a measure of subjective confidence, in which the 0.95 probability is used to reflect our state of knowledge (ie, from a Bayesian standpoint), and to say “I am 95% confident that this interval contains the mean.”
Reporting and Using Confidence Intervals#
What is the role of confidence intervals in summarizing data?
The simple answer is confidence intervals are crucial.
You cannot communicate with clarity without reporting confidence intervals.
Any time you are reporting a statistic derived from a sample, such as the sample mean, you should report the associated confidence intervals.
Confidence intervals combine information on location and precision.
They tell you (or your reader) both how large is the quantity (location) and how much information the estimate provides.
There are standard ways for doing this.
In text, it is standard to write in this format:
\(M = 30.5 \text{cm, 95% CI } [18.0, 45.0]\)
In a table, you should use this format:
height |
95% CI |
|
|---|---|---|
men, n = 25 |
69.0 in |
[68.1, 69.9] |
women, n = 23 |
61.1 in |
[60.3, 62.0] |
In figures, it is standard to use error bars as we have in this lecture.
And a final point: throughout this lecture we’ve computed 95% confidence intervals. Some statisticians will suggest that you may want to use a different confidence level depending on the setting.
If your results will be used to make life-or-death decisions, perhaps a 99% or even a 99.9% confidence interval should be used.
On the other hand, if we are not so concerned about an occasional miss, perhaps a 90% or 80% confidence interval should be used.
These are reasonable considerations, but in general work it’s probably best to stick with 95% confidence intervals for consistency and ease of interpretation.