Parameter Estimation: Maximum Likelihood Estimation#
Review Parameter Estimation: Model Fitting#
Model fitting is finding the parameter(s) \(\theta\) of a population distribution given that we know some data from it.

Distribution |
Parameters \(\theta\) |
|---|---|
Bernoulli |
\(p\) |
Binomial |
\((N,p)\) |
Poisson |
\(\lambda\) |
Geometric |
\(p\) |
Exponential |
\(\lambda\) |
Uniform |
\((a,b)\) |
Normal |
\((\mu, \sigma)\) |
When we think of \(p(x; \theta)\) as a function of \(\theta\) (instead of \(x\)) we call it a likelihood.
If \( X_s = \{x_1,x_2, \dots, x_m\} \) is a sample consisting of \(m\) data items drawn independently from the same population, then the corresponding likelihood function is equal to $\(p(X_s;\theta) = p\left(x_1,x_2, \dots, x_m;\theta \right) = p(x_1; \theta)p(x_2; \theta)\dots p(x_m; \theta)= \prod_{i=1}^{m} p\left(x_i; \theta\right).\)$
Here, \(\prod\) denotes a product. For example, the product of two numbers \(a_1\) and \(a_2\)
(i.e., \(a_1 a_2\)), can be written as \(\prod_{i=1}^2 a_i\).
Since \(p\left(x_i; \theta\right)\) is a value between 0 and 1, \(p(X_s;\theta)= \prod_{i=1}^{m} p\left(x_i; \theta\right)\) is very small. To avoid working with small numbers, we use the log of the likelihood: $\( \log p\left(X_s; \theta \right) = \log \prod_{i=1}^m p\left(x_i; \theta\right) = \sum_{i=1}^m \log p\left(x_i; \theta \right).\)$
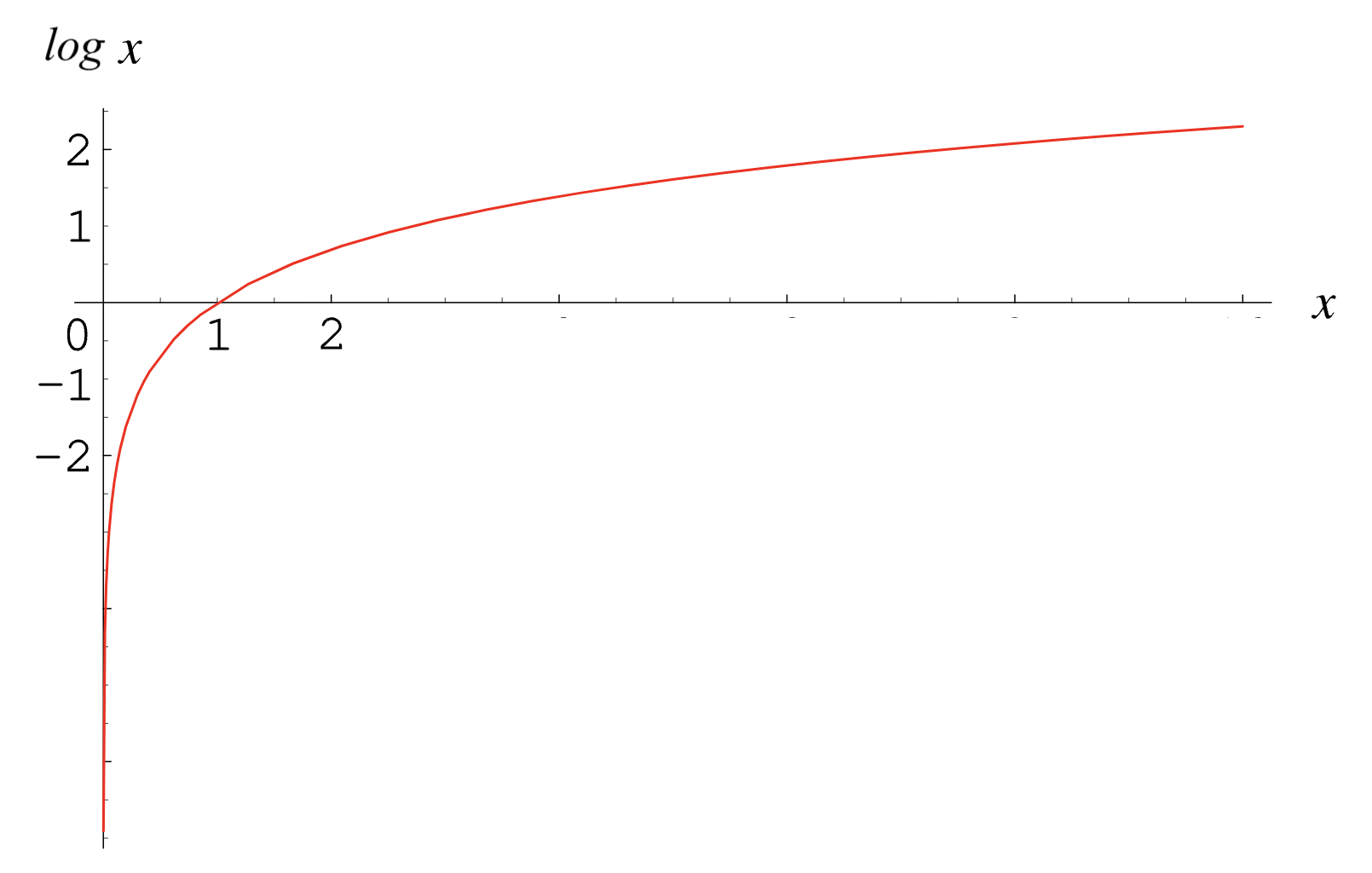
First part of model fitting: computing the log-likelihood function.
Second part of model fitting: computing the estimate(s) of the parameter(s).
The Maximum Likelihood Principle#
We have seen some examples of estimators for parameters in the first lecture on parameter estimation. But where do estimators come from exactly?
Rather than making guesses about what might be a good estimator, we’d like a principle that we can use to derive good estimators for different models.
The most common principle is the maximum likelihood principle.
The Maximum Likelihood Estimate (MLE) of \(\theta\) is that value of \(\theta\) that maximizes the likelihood function - that is, makes the observed data “most probable” or “most likely”.
Formally, we say that the maximum likelihood estimator for \(\theta\) is:
which for a dataset of \(m\) items is:
This is the same thing as maximizing the log-likelihood:
We will drop the ML subsript in the remaining part of the lecture.
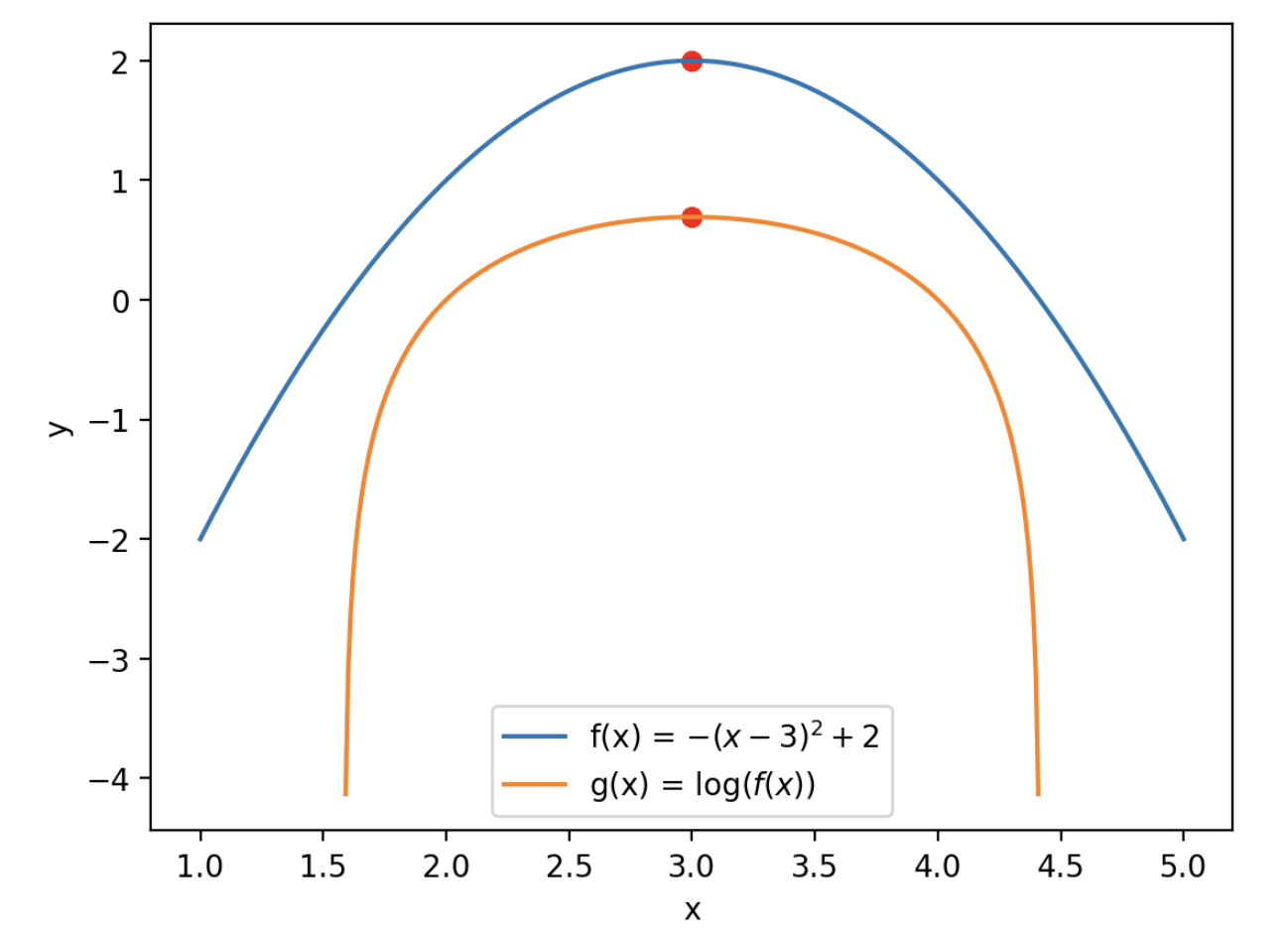
Since \(\log\) is a monotonic function, the likelihood function and the log-likehood function have maxima in the same location.
Illustration of this property for a general (i.e., not likehood function) function \(f(x)\) and its natural logarithm \(g(x) = \log f(x)\):
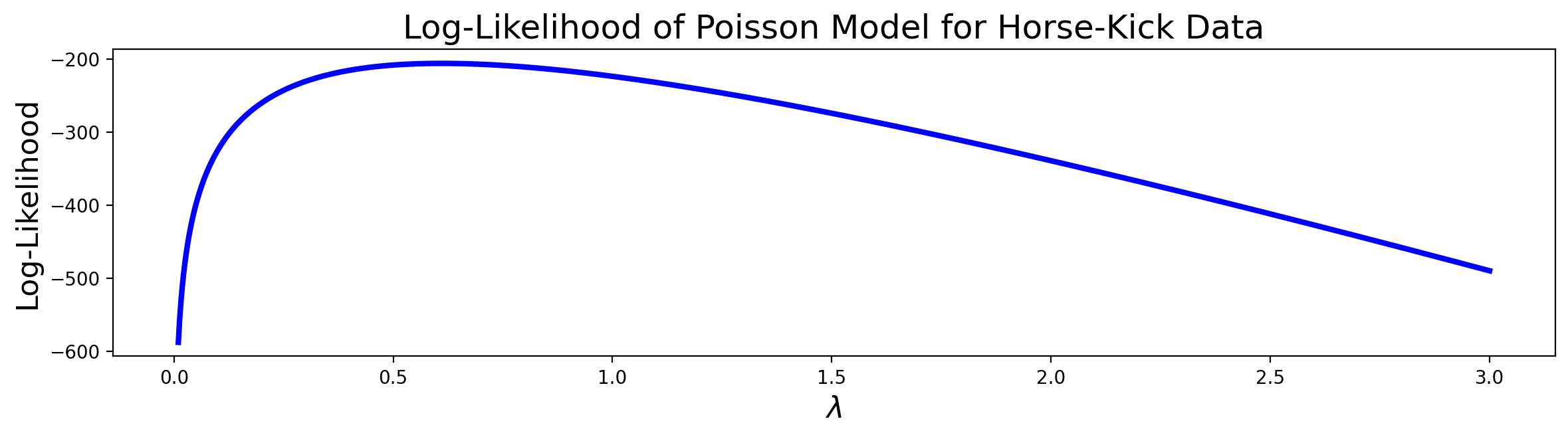
Example. Looking back at the deaths-by-horse-kick data, we can see that there is clearly a maximum in the plot of the log-likelihood function, somewhere between 0.5 and 1.
If we use the value of \(\theta = \lambda\) at the maximum, we are choosing to set \(\lambda\) to maximize the (log-)likelihood of the data under the model.
Computation of MLE#
Often, the MLE is found using calculus by locating a critical point:
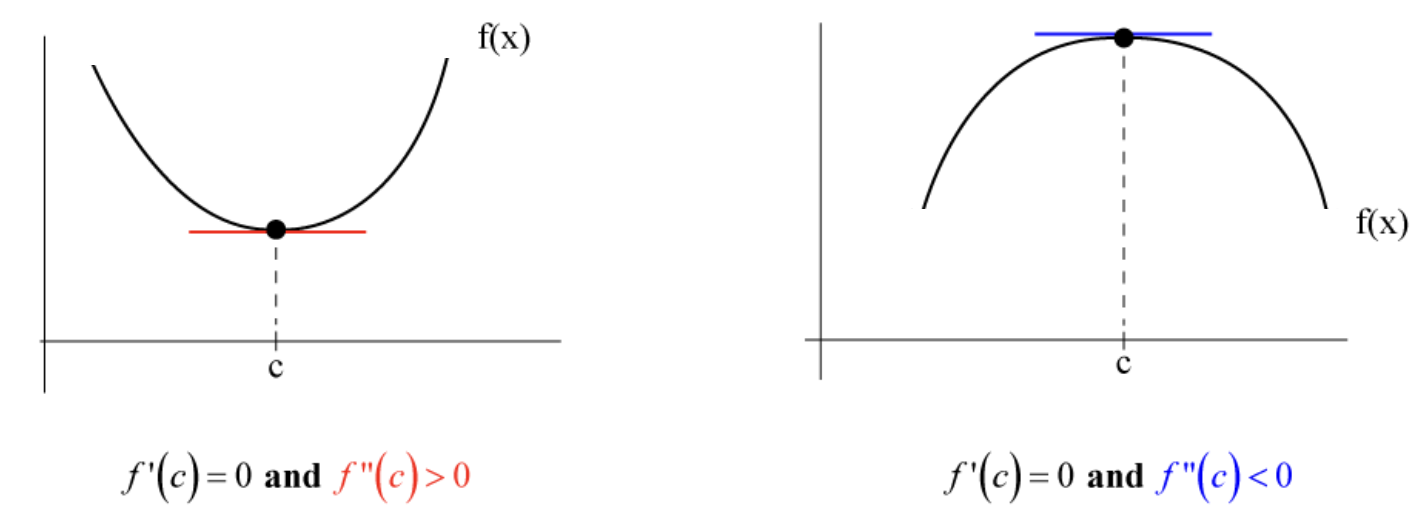
The computation of the second derivatives becomes reduntant when the graph of the log-likelihood function is available and confirms that the critical point is indeed a maximum.
The table below shows some useful properties of the derivatives.
Natural logarithm |
\(\frac{d}{dx}\log x = \frac{1}{x}\) |
Product rule |
\(\frac{d}{dx}(uv) = u\frac{dv}{dx} + v\frac{du}{dx}\) |
Quotient rule |
\(\frac{d}{dx}\left(\frac{u}{v}\right) = \frac{v\:du/dx\:-\:u\:dv/dx}{v^2}\) |
Chain rule |
\(\frac{d}{dx}z(y(x)) = \frac{dz}{dy}\frac{dy}{dx}\) |
Summary of the computational steps#
The steps to find Maximum Likelihood Estimate \(\hat{\theta}\) for distribution parameter \(\theta\):
Compute the likehood function \(p\left(X_s;\theta \right).\)
Compute the corresponding log-likelihood function \(\log p\left(X_s;\theta \right).\)
Take the derivative of the log-likelihood function with respect to \(\theta\).
Set the derivative to zero to find the MLE.
(Optional) Confirm that the obtained extremum is indeed a maximum by taking the second derivative or from the plot of the log-likelihood function.
Consistency#
The maximum likelihood estimator has a number of properties that make it the preferred way to estimate parameters whenever possible.
In particular, under appropriate conditions, the MLE is consistent, meaning that as the number of data items grows large, the estimate converges to the true value of the parameter.
It can also be shown that for large \(m\), no consistent estimator has a lower MSE than the maximum likelihood estimator.
Example.
Previously we looked at the following problem:
Suppose that \(x\) is a discrete random variable with the probability mass function shown below.
\(x\) |
\(0\) |
\(1\) |
\(2\) |
\(3\) |
|---|---|---|---|---|
\(p(x;\theta)\) |
\(\frac{2}{3}\theta\) |
\(\frac{1}{3}\theta\) |
\(\frac{2}{3}\left(1-\theta\right)\) |
\(\frac{1}{3}\left(1-\theta\right)\) |
Here \(0\leq \theta \leq 1\) is a parameter. The following 10 independent observations were taken from this distribution:
Before we found the corresponding log-likelihood function. This time we want to go a step further and find the MLE for \(\theta\).
We know that the likelihood function is equal to
This function is not easy to maximize. Let us look at the log-likelihood function.
The log-likelihood function is given by
The derivative of the log-likelihood function with respect to \(\theta\) is equal to
Setting the derivative to zero leads to
This suggests that the MLE for \(\theta\) is potentially \(\hat{\theta}=\frac{1}{2}.\)
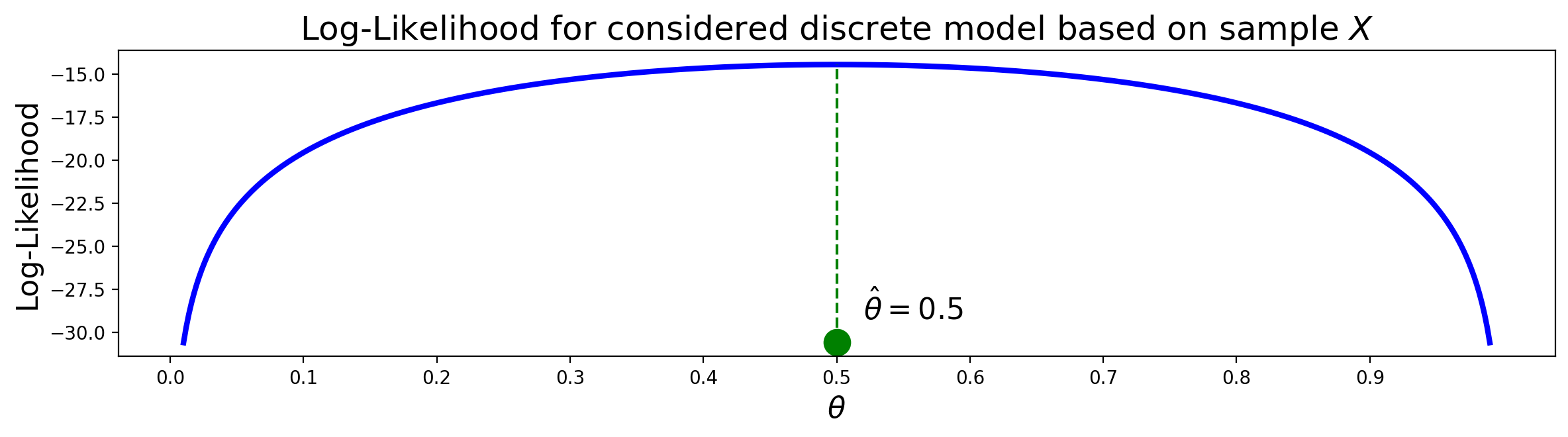
The figure shows that \(\hat{\theta}=\frac{1}{2}\) is a maximum. Therefore, the MLE of \(\theta\) is indeed \(\frac{1}{2}.\)
Question. Suppose that \(X\) is a discrete random variable with the probability mass function given by
\(x\) |
\(1\) |
\(2\) |
|---|---|---|
\(p(x;\theta)\) |
\(\theta\) |
\(1-\theta\) |
Here \(0\leq \theta \leq 1\) is the unknown parameter. Three independent oservations are made from this distribution: $\(x_1 = 1, x_2 = 2, x_3 = 2. \)$
What is the likelihood function?
a. \(\log \theta + 2 \log(1-\theta)\)
b. \(2\log \theta + \log(1-\theta)\)
c. \(\theta (1-\theta)^2\)
d. \(\theta (1-\theta)\)
Answer. c
Question. Since the likelihood function in this case is \(p(X_s;\theta)=\theta (1-\theta)^2\), the log-likelihood function is equal to
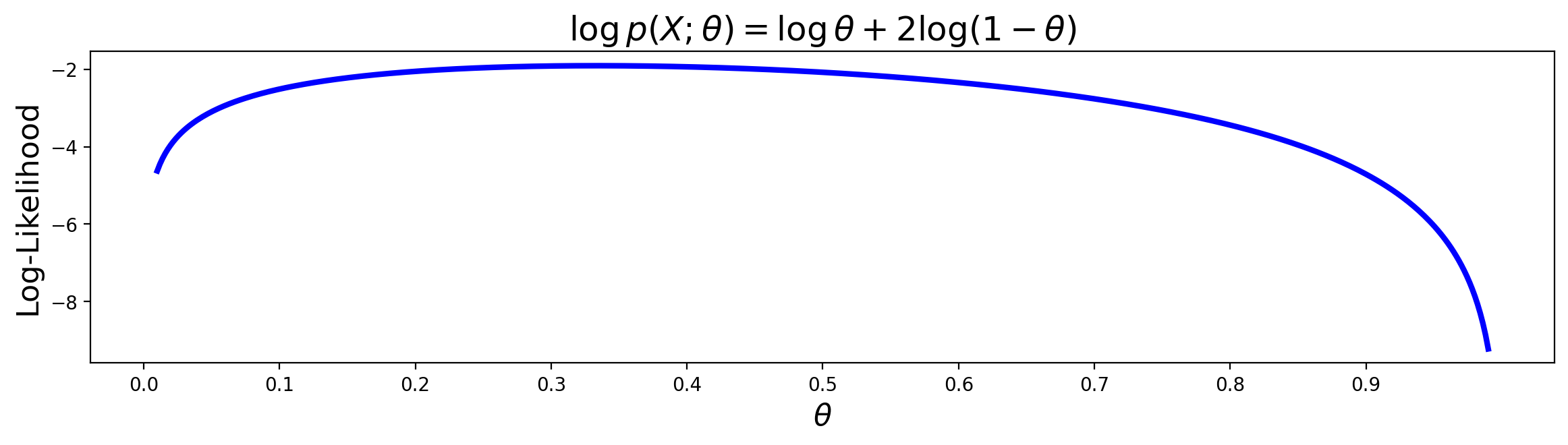
What is the maximum likelihood estimate of \(\theta\)?
Compute your answer using the derivative of \(\log p(X_s;\theta) = \log \theta + 2\log (1-\theta).\)
a. \(\hat{\theta} = \frac{1}{4} \)
b. \(\hat{\theta} =\frac{1}{3} \)
c. \(\hat{\theta} = 1 \)
d. \(\hat{\theta} =\frac{1}{5} \)
Answer. b
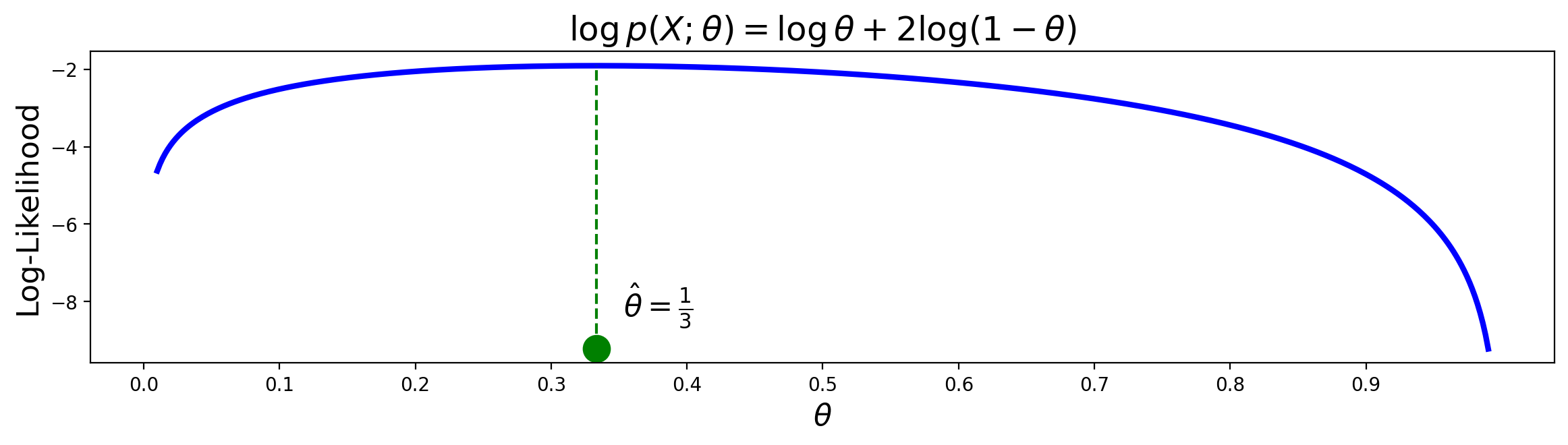
Example.
Let’s revisit the Bortkeiwicz’s horse-kick data as well. Recall that Bortkeiwicz had collected deaths by horse-kick in the Prussian army over a span of 200 years, and was curious whether they occurred at a constant, fixed rate.
| Deaths Per Year | Observed Instances |
|---|---|
| 0 | 109 |
| 1 | 65 |
| 2 | 22 |
| 3 | 3 |
| 4 | 1 |
| 5 | 0 |
| 6 | 0 |
Previously we started fitting the data to a Poisson distribution. We found that the likelihood function is given by
Answer. \(m=200,\) because it represents the number of data points.
From the likelihood function we obtained the log-likehood function:
To find the maximum of the log-likelihood of the data as a function of \(\lambda\), we need to compute the derivative w.r.t. \(\lambda\):
Setting the derivative to zero, we get the expression for the maximum likelihood estimator
This is just the mean of the data, that is, the average number of deaths per year! From the available data we can compute that the mean is 0.61. The plot confirms that 0.61 is indeed a maximum. Therefore, the MLE of \(\lambda\), \(\hat{\lambda}\) = 0.61.
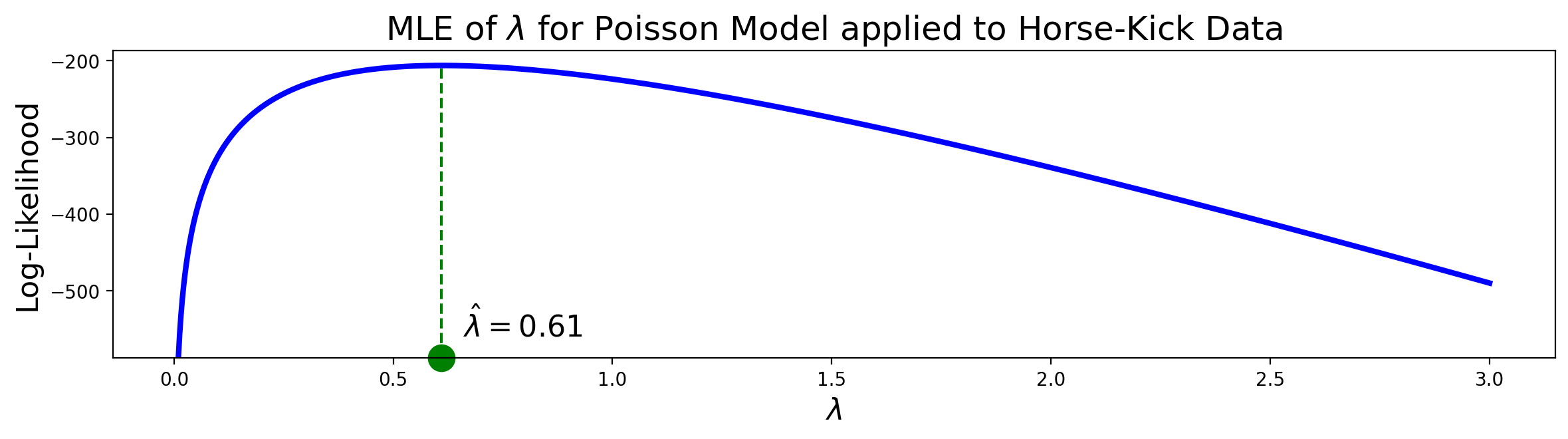
The plot confirms that 0.61 is indeed a maximum. Therefore, the MLE for \(\lambda\), \(\hat{\lambda}\) = 0.61.
Using this estimate for \(\lambda\), we can ask what the expected number of deaths per year would be, if deaths by horse-kick really followed the assumptions of the Poisson distribution (ie, happening at a fixed, constant rate):
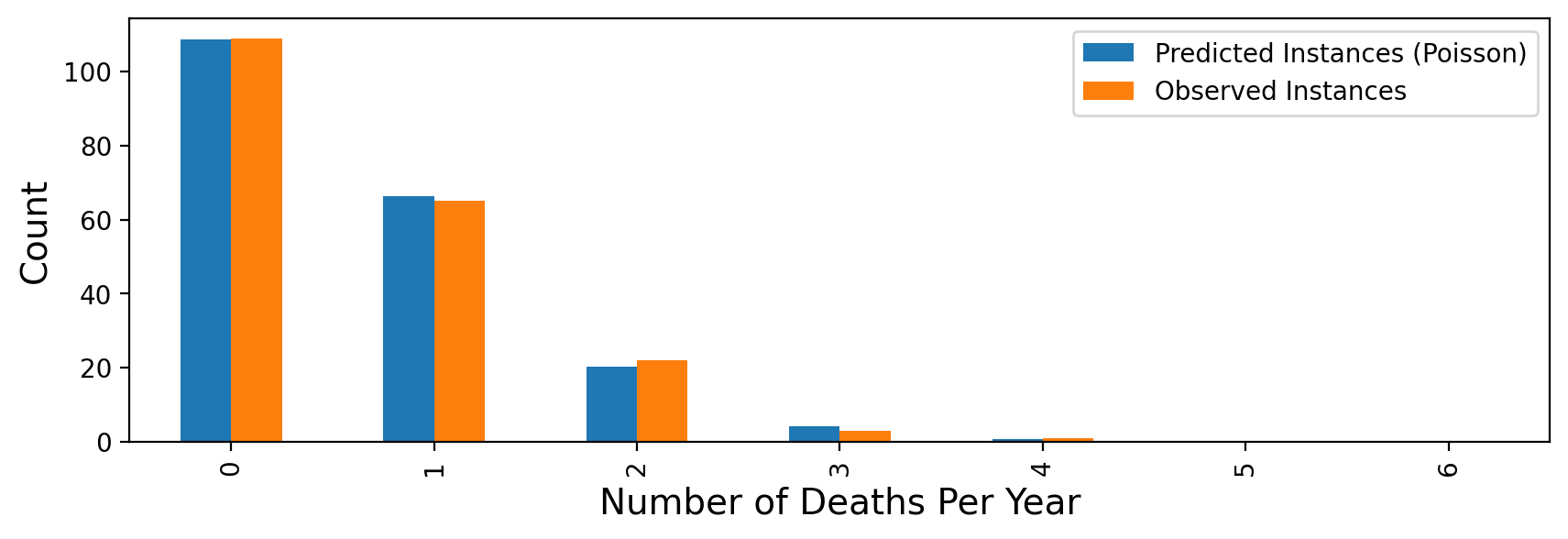
Which shows that the Poisson model is indeed a very good fit to the data!
From this, Bortkeiwicz concluded that there was nothing particularly unusual about the years when there were many deaths by horse-kick. They could be just what is expected if deaths occurred at a constant rate.
Example.
We also had looked at sample data \(X_s =\{x_1, \dots, x_m\}\) from a normal distribution \(N(\mu,\sigma^2)\) with \(\mu\) and \(\sigma\) unknown. To fit the data to a normal distribution both \(\mu\) and \(\sigma\) have to be estimated.
We found previously that the likelihood function is equal to
while the log-likelihood function is given by
Replacing the constant term by \(c\) we can write the log-likehood as
The partials with respect to \(\mu\) and \(\sigma\) are
We assume that \(\sigma>0\) and set the first partial derivative to zero:
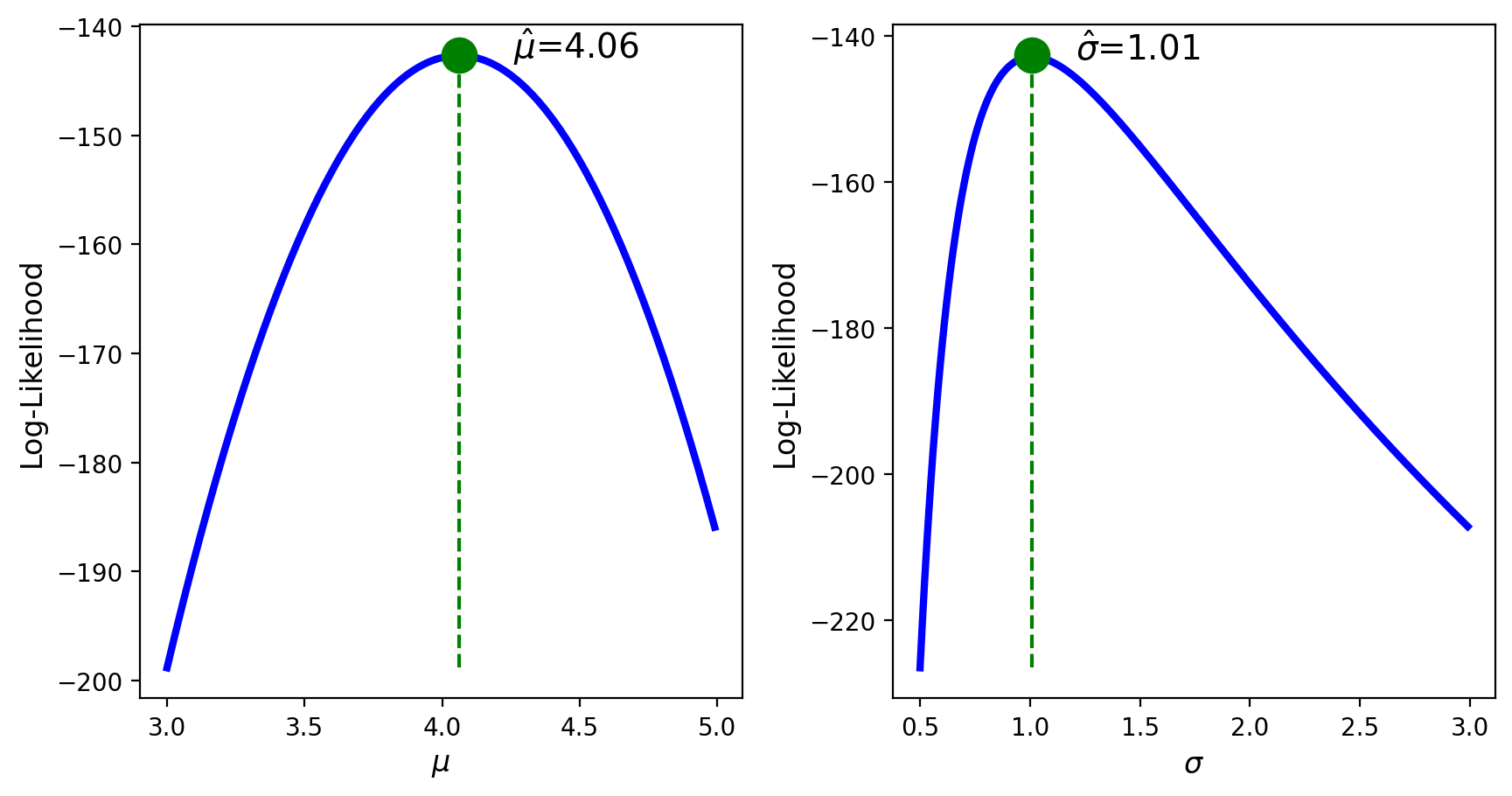
Thus, \(\hat{\mu}\) is the sample mean.
To find an estimate for the standard deviation we use \(\hat{\mu}\) and set the second partial derivative to zero. Since \(\sigma>0\), we obtain
where \(\hat{\mu}\) is the sample mean.
Thus, the potential MLE for \(\mu\) and \(\sigma\) are
The upcoming Python example will illustrate that the above \(\hat{\mu}\) and \(\hat{\sigma}\) are indeed maxima and hence are the MLE for \(\mu\) and \(\sigma\) of \(N(\mu,\sigma^2)\).
Python example#
We look at a sample of size 100 from a normal distribution. The log-likelihood function can be created in the following way.
# log-likelihood function for a normal distribution
# input: sample, parameters' domains
def normloglik(X,muV,sigmaV):
m = len(X)
return -m/2*np.log(2*np.pi) - m*np.log(sigmaV)\
- (np.sum(np.square(X))- 2*muV*np.sum(X)+m*muV**2)/(2*sigmaV**2)
The MLE for \(\mu\) and \(\sigma\) can be computed using the mean and var functions from NumPy.
# MLE for the mean and the standard deviation
mu_hat = np.mean(data)
sig_hat = np.sqrt(np.var(data, axis = 0, ddof = 0))
llik = normloglik(data, mu_hat, sig_hat)
We can visualize the MLE on the surface plot.
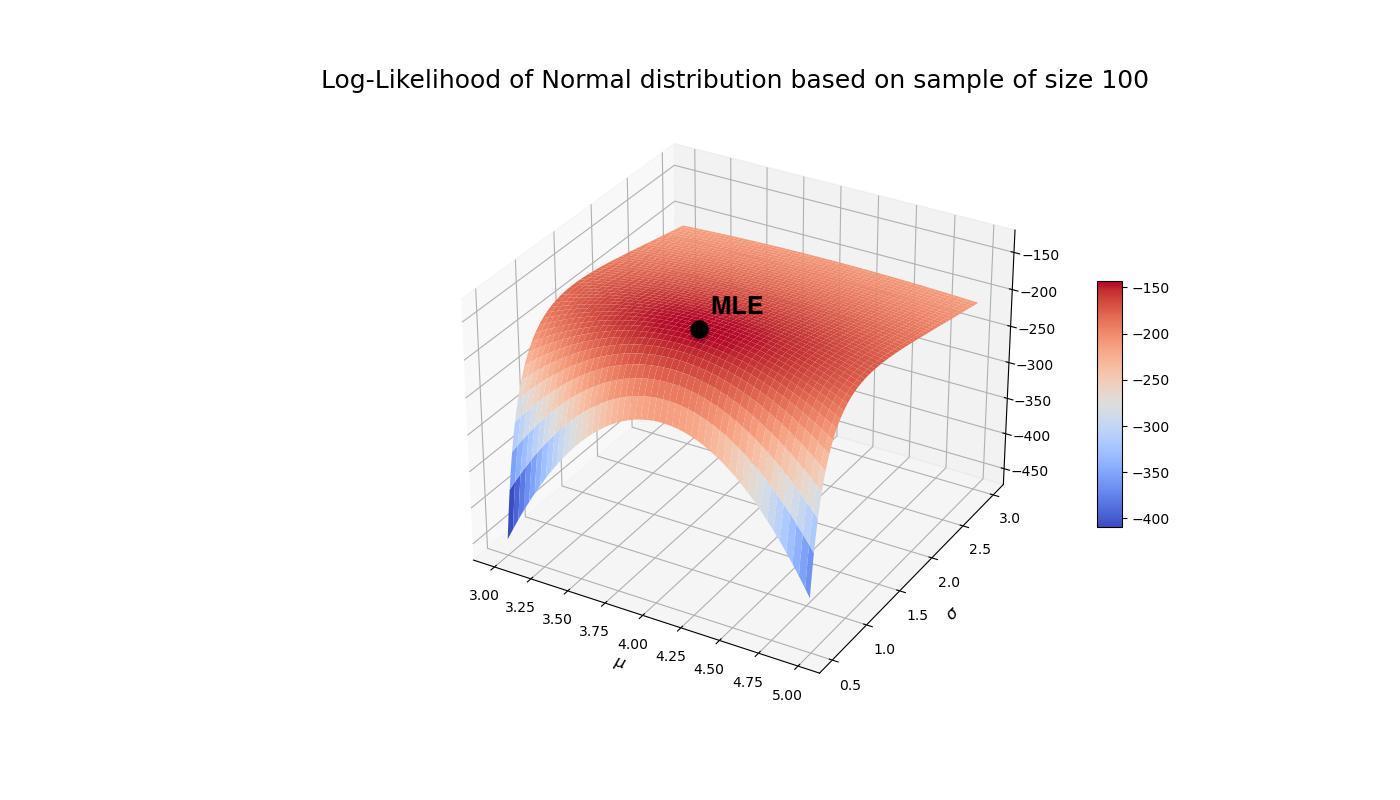
Alternatively, if one of the parameters is known, we visualize the log-likelihood as function of the unknown parameter and indicate the computed MLE.
Summary Parameter Estimation#
Parameter estimation is inference about a population parameter based on a sample statistic. Model fitting is a closely related concept: it implies finding the parameters of a distribution given that we know some data from it.
The maximum likelihood principle is often the preferred way to estimate parameters. The maximum likelihood estimate (MLE) is that value of the parameter that maximizes the probability of the data as a function of that parameter (i.e., the likelihood). The MLE can be found as follows:
Compute the likelihood function;
Compute the log-likelihood function;
Take the derivative of the log-likelihood function w.r.t. the unknown parameter;
Set the derivative to zero to find the MLE;
Optionally check the sign of the second derivative or use the graph to confirm that the critical point is a maximum.
To evaluate an estimator we use:
Bias: it measures the expected deviation from the true value of the parameter.
Variance: it measures how much the estimator can vary as a function of the data sample.
Mean Squared Error: it combines bias and variance.
Consistency: it evaluates whether the estimate converges to the true value of the parameter.