Orthogonal Sets and Projection
Many parts of this page are based on Linear Algebra and its Applications, by David C. Lay
Today we deepen our study of geometry.
In the last lecture we focused on points, lines, and angles.
Today we take on more challenging geometric notions that bring in sets of vectors and subspaces.
Within this realm, we will focus on orthogonality and a new notion called projection.
First of all, today we’ll study the properties of sets of orthogonal vectors.
These can be very useful.
Orthogonal Sets
A set of vectors \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) in \(\mathbb{R}^n\) is said to be an orthogonal set if each pair of distinct vectors from the set is orthogonal, i.e.,
\[\mathbf{u}_i^T\mathbf{u}_j = 0\;\;\text{whenever}\;i\neq j.\]
Example. Show that \(\{\mathbf{u}_1,\mathbf{u}_2,\mathbf{u}_3\}\) is an orthogonal set, where
\[ \mathbf{u}_1 = \begin{bmatrix}3\\1\\1\end{bmatrix},\;\;\mathbf{u}_2=\begin{bmatrix}-1\\2\\1\end{bmatrix},\;\;\mathbf{u}_3=\begin{bmatrix}-1/2\\-2\\7/2\end{bmatrix}.\]
Solution. Consider the three possible pairs of distinct vectors, namely, \(\{\mathbf{u}_1,\mathbf{u}_2\}, \{\mathbf{u}_1,\mathbf{u}_3\},\) and \(\{\mathbf{u}_2,\mathbf{u}_3\}.\)
\[ \mathbf{u}_1^T\mathbf{u}_2 = 3(-1) + 1(2) + 1(1) = 0\]
\[ \mathbf{u}_1^T\mathbf{u}_3 = 3(-1/2) + 1(-2) + 1(7/2) = 0\]
\[ \mathbf{u}_2^T\mathbf{u}_3 = -1(-1/2) + 2(-2) + 1(7/2) = 0\]
Each pair of distinct vectors is orthogonal, and so \(\{\mathbf{u}_1,\mathbf{u}_2, \mathbf{u}_3\}\) is an orthogonal set.
In three-space they describe three lines that we say are mutually perpendicular.
Orthogonal Sets Must be Independent
Orthogonal sets are very nice to work with.
First of all, we will show that any orthogonal set must be linearly independent.
Theorem. If \(S = \{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) is an orthogonal set of nonzero vectors in \(\mathbb{R}^n,\) then \(S\) is linearly independent.
Proof. We will prove that there is no linear combination of the vectors in \(S\) with nonzero coefficients that yields the zero vector.
Our proof strategy will be:
we will show that for any linear combination of the vectors in \(S\):
- if the combination is the zero vector,
- then all coefficients of the combination must be zero.
Specifically:
Assume \({\bf 0} = c_1\mathbf{u}_1 + \dots + c_p\mathbf{u}_p\) for some scalars \(c_1,\dots,c_p\). Then:
\[{\bf 0} = c_1\mathbf{u}_1 + c_2\mathbf{u}_2 + \dots + c_p\mathbf{u}_p\]
\[{\bf 0}^T\mathbf{u}_1 = (c_1\mathbf{u}_1 + c_2\mathbf{u}_2 + \dots + c_p\mathbf{u}_p)^T\mathbf{u}_1\]
\[0 = (c_1\mathbf{u}_1 + c_2\mathbf{u}_2 + \dots + c_p\mathbf{u}_p)^T\mathbf{u}_1\]
\[ 0 = (c_1\mathbf{u}_1)^T\mathbf{u}_1 + (c_2\mathbf{u}_2)^T\mathbf{u}_1 \dots + (c_p\mathbf{u}_p)^T\mathbf{u}_1\]
\[ 0 = c_1(\mathbf{u}_1^T\mathbf{u}_1) + c_2(\mathbf{u}_2^T\mathbf{u}_1) + \dots + c_p(\mathbf{u}_p^T\mathbf{u}_1)\]
Because \(\mathbf{u}_1\) is orthogonal to \(\mathbf{u}_2,\dots,\mathbf{u}_p\):
\[ 0 = c_1(\mathbf{u}_1^T\mathbf{u}_1) \]
Since \(\mathbf{u}_1\) is nonzero, \(\mathbf{u}_1^T\mathbf{u}_1\) is not zero and so \(c_1 = 0\).
We can use the same kind of reasoning to show that, \(c_2,\dots,c_p\) must be zero.
In other words, there is no nonzero combination of \(\mathbf{u}_i\)’s that yields the zero vector …
… so \(S\) is linearly independent.
Notice that since \(S\) is a linearly independent set, it is a basis for the subspace spanned by \(S\).
This leads us to a new kind of basis.
Orthogonal Basis
Definition. An orthogonal basis for a subspace \(W\) of \(\mathbb{R}^n\) is a basis for \(W\) that is also an orthogonal set.
For example, consider
\[\mathbf{u} = \begin{bmatrix} -1/2\\ 2\\ 1 \end{bmatrix}, \mathbf{v} = \begin{bmatrix} 8/3\\ 1/3\\ 2/3 \end{bmatrix}.\]
Note that \(\mathbf{u}^T\mathbf{v} = 0.\) Hence they form an orthogonal basis for their span.
Here is the subspace \(W = \text{Span}\{\mathbf{u},\mathbf{v}\}\):
Finding Coordinates in an Orthogonal Basis
We have seen that for any subspace \(W\), there may be many different sets of vectors that can serve as a basis for \(W\).
For example, let’s say we have a basis \(\mathcal{B} = \{\mathbf{u}_1, \mathbf{u}_2, \mathbf{u}_3\}.\)
We know that to compute the coordinates of \(\mathbf{y}\) in this basis, we need to solve the linear system: \[c_1 \mathbf{u}_1 + c_2\mathbf{u}_2 + c_3\mathbf{u}_3 = \mathbf{y}\] or \[U\mathbf{c} = \mathbf{y}.\]
In general, we’d need to perform Gaussian Elimination, or matrix inversion, or some other complex method to do this.
However, an orthogonal basis is a particularly nice basis, because the weights (coordinates) of any point can be computed easily and simply.
Let’s see how:
Theorem. Let \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) be an orthogonal basis for a subspace \(W\) of \(\mathbb{R}^n\). For each \(\mathbf{y}\) in \(W,\) the weights of the linear combination
\[c_1\mathbf{u}_1 + \dots + c_p\mathbf{u}_p = \mathbf{y}\]
are given by
\[c_j = \frac{\mathbf{y}^T\mathbf{u}_j}{\mathbf{u}_j^T\mathbf{u}_j}\;\;\;j = 1,\dots,p\]
Proof.
Let’s consider the inner product of \(\mathbf{y}\) and one of the \(\mathbf{u}\) vectors — say, \(\mathbf{u}_1\).
As we saw in the last proof, the orthogonality of \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) means that
\[\mathbf{y}^T\mathbf{u}_1 = (c_1\mathbf{u}_1 + c_2\mathbf{u}_2 + \dots + c_p\mathbf{u}_p)^T\mathbf{u}_1\]
\[=c_1(\mathbf{u}_1^T\mathbf{u}_1)\]
Since \(\mathbf{u}_1^T\mathbf{u}_1\) is not zero (why?), the equation above can be solved for \(c_1.\)
Thus:
\[c_1 = \frac{\mathbf{y}^T\mathbf{u}_1}{\mathbf{u}_1^T\mathbf{u}_1}\]
To find any other \(c_j,\) compute \(\mathbf{y}^T\mathbf{u}_j\) and solve for \(c_j\).
Example. The set \(S\) which we saw earlier, ie,
\[ \mathbf{u}_1 = \begin{bmatrix}3\\1\\1\end{bmatrix},\;\;\mathbf{u}_2=\begin{bmatrix}-1\\2\\1\end{bmatrix},\;\;\mathbf{u}_3=\begin{bmatrix}-1/2\\-2\\7/2\end{bmatrix},\]
is an orthogonal basis for \(\mathbb{R}^3.\)
Now, let us express the vector \(\mathbf{y} = \begin{bmatrix}6\\1\\-8\end{bmatrix}\) as a linear combination of the vectors in \(S\).
That is, find \(\mathbf{y}\)’s coordinates in the basis \(S\) — i.e., in the coordinate system \(S\).
Solution. Compute
\[\mathbf{y}^T\mathbf{u}_1 = 11,\;\;\;\mathbf{y}^T\mathbf{u}_2 = -12,\;\;\;\mathbf{y}^T\mathbf{u}_3 = -33,\]
\[\mathbf{u}_1^T\mathbf{u}_1 = 11,\;\;\;\mathbf{u}_2^T\mathbf{u}_2 = 6,\;\;\;\mathbf{u}_3^T\mathbf{u}_3 = 33/2\]
So
\[\mathbf{y} = \frac{\mathbf{y}^T\mathbf{u}_1}{\mathbf{u}_1^T\mathbf{u}_1}\mathbf{u}_1 + \frac{\mathbf{y}^T\mathbf{u}_2}{\mathbf{u}_2^T\mathbf{u}_2}\mathbf{u}_2 + \frac{\mathbf{y}^T\mathbf{u}_3}{\mathbf{u}_3^T\mathbf{u}_3}\mathbf{u}_3\]
\[ = \frac{11}{11}\mathbf{u}_1 + \frac{-12}{6}\mathbf{u}_2 + \frac{-33}{33/2}\mathbf{u}_3\]
\[ = \mathbf{u}_1 - 2\mathbf{u}_2 - 2 \mathbf{u}_3.\]
Note how much simpler it is finding the coordinates of \(\mathbf{y}\) in the orthogonal basis,
because each coefficient \(c_1\) can be found separately without matrix operations.
Orthogonal Projection
Now let’s turn to the notion of projection.
In general, a projection happens when we decompose a vector into the sum of other vectors.
Here is the central idea. We will use this a lot over the next couple lectures.
Given a nonzero vector \(\mathbf{u}\) in \(\mathbb{R}^n,\) consider the problem of decomposing a vector \(\mathbf{y}\) in \(\mathbb{R}^n\) into the sum of two vectors:
- one that is a multiple of \(\mathbf{u}\), and
- one that is orthogonal to \(\mathbf{u}.\)


In other words, we wish to write:
\[\mathbf{y} = \hat{\mathbf{y}} + \mathbf{z}\]
where \(\hat{\mathbf{y}} = \alpha\mathbf{u}\) for some scalar \(\alpha\) and \(\mathbf{z}\) is some vector orthogonal to \(\mathbf{u}.\)

That is, we are given \(\mathbf{y}\) and \(\mathbf{u}\), and asked to compute \(\mathbf{z}\) and \(\hat{\mathbf{y}}.\)
To solve this, assume that we have some \(\alpha\), and with it we compute \(\mathbf{y} - \alpha\mathbf{u} = \mathbf{y}-\hat{\mathbf{y}} = \mathbf{z}.\)
We want \(\mathbf{z}\) to be orthogonal to \(\mathbf{u}.\)
Now \(\mathbf{z} = \mathbf{y} - \alpha{\mathbf{u}}\) is orthogonal to \(\mathbf{u}\) if and only if
\[0 = (\mathbf{y} - \alpha\mathbf{u})^T\mathbf{u}\]
\[ = \mathbf{y}^T\mathbf{u} - (\alpha\mathbf{u})^T\mathbf{u}\]
\[ = \mathbf{y}^T\mathbf{u} - \alpha(\mathbf{u}^T\mathbf{u})\]
That is, the solution in which \(\mathbf{z}\) is orthogonal to \(\mathbf{u}\) happens if and only if
\[\alpha = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}\]
and since \(\hat{\mathbf{y}} = \alpha\mathbf{u}\),
\[\hat{\mathbf{y}} = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}\mathbf{u}.\]
The vector \(\hat{\mathbf{y}}\) is called the orthogonal projection of \(\mathbf{y}\) onto \(\mathbf{u}\), and the vector \(\mathbf{z}\) is called the component of \(\mathbf{y}\) orthogonal to \(\mathbf{u}.\)

Projections are onto Subspaces

Now, note that if we had scaled \(\mathbf{u}\) by any amount (ie, moved it to the right or the left), we would not have changed the location of \(\hat{\mathbf{y}}.\)
This can be seen as well by replacing \(\mathbf{u}\) with \(c\mathbf{u}\) and recomputing \(\hat{\mathbf{y}}\):
\[\hat{\mathbf{y}} = \frac{\mathbf{y}^Tc\mathbf{u}}{c\mathbf{u}^Tc\mathbf{u}}c\mathbf{u} = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}\mathbf{u}.\]
Thus, the projection of \(\mathbf{y}\) is determined by the subspace \(L\) that is spanned by \(\mathbf{u}\) – in other words, the line through \(\mathbf{u}\) and the origin.
Hence sometimes \(\hat{\mathbf{y}}\) is denoted by \(\operatorname{proj}_L \mathbf{y}\) and is called the orthogonal projection of \(\mathbf{y}\) onto \(L\).
Specifically:
\[\hat{\mathbf{y}} = \operatorname{proj}_L \mathbf{y} = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}\mathbf{u}\]
Example. Let \(\mathbf{y} = \begin{bmatrix}7\\6\end{bmatrix}\) and \(\mathbf{u} = \begin{bmatrix}4\\2\end{bmatrix}.\)
Find the orthogonal projection of \(\mathbf{y}\) onto \(\mathbf{u}.\) Then write \(\mathbf{y}\) as the sum of two orthogonal vectors, one in Span\(\{\mathbf{u}\}\), and one orthogonal to \(\mathbf{u}.\)
Solution. Compute
\[\mathbf{y}^T\mathbf{u} = \begin{bmatrix}7&6\end{bmatrix}\begin{bmatrix}4\\2\end{bmatrix} = 40\]
\[\mathbf{u}^T\mathbf{u} = \begin{bmatrix}4&2\end{bmatrix}\begin{bmatrix}4\\2\end{bmatrix} = 20\]
The orthogonal projection of \(\mathbf{y}\) onto \(\mathbf{u}\) is
\[\hat{\mathbf{y}} = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}} \mathbf{u}\]
\[=\frac{40}{20}\mathbf{u} = 2\begin{bmatrix}4\\2\end{bmatrix} = \begin{bmatrix}8\\4\end{bmatrix}\]
And the component of \(\mathbf{y}\) orthogonal to \(\mathbf{u}\) is
\[\mathbf{y}-\hat{\mathbf{y}} = \begin{bmatrix}7\\6\end{bmatrix} - \begin{bmatrix}8\\4\end{bmatrix} = \begin{bmatrix}-1\\2\end{bmatrix}.\]
So
\[\mathbf{y} = \hat{\mathbf{y}} + \mathbf{z}\]
\[\begin{bmatrix}7\\6\end{bmatrix} = \begin{bmatrix}8\\4\end{bmatrix} + \begin{bmatrix}-1\\2\end{bmatrix}.\]

Important Properties of \(\hat{\mathbf{y}}\)
Here is a proof that the closest point on the line to \(\mathbf{y}\) is given by the projection of \(\mathbf{y}\) onto the line.
Let \(\mathbf{q} = \alpha \mathbf{u}\). The squared distance from \(\mathbf{y}\) to \(\mathbf{q}\) is \(\Vert \mathbf{y}-\mathbf{q}\Vert^2 = \Vert \mathbf{y}-\alpha\mathbf{u}\Vert^2\).
Expanding this, \(\Vert \mathbf{y}-\alpha\mathbf{u}\Vert^2 =\) \(\mathbf{y}^T\mathbf{y} - 2\alpha(\mathbf{y}^T\mathbf{u}) + \alpha^2(\mathbf{u}^T\mathbf{u}).\)
This is a quadratic function in \(\alpha\). To minimize it, we take the derivative with respect to \(\alpha\): \(\frac{d}{d\alpha} [\mathbf{y}^T\mathbf{y} - 2\alpha(\mathbf{y}^T\mathbf{u}) + \alpha^2(\mathbf{u}^T\mathbf{u})]\) \(= -2(\mathbf{y}^T\mathbf{u}) + 2\alpha(\mathbf{u}^T\mathbf{u})\).
Setting the derivative to zero gives \(\alpha = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}.\)
Therefore the closest point to \(\mathbf{y}\) on the line \(\operatorname{Span}\{\mathbf{u}\}\) is \(\frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}} \mathbf{u}\), namely, the orthogonal projection of \(\mathbf{y}\) onto \(\operatorname{Span}\{\mathbf{u}\}\).
The closest point.
Recall from geometry that given a line and a point \(\mathbf{y}\), the closest point on the line to \(\mathbf{y}\) is given by the perpendicular from \(\mathbf{y}\) to the line.
There is a short proof in the margin.
So this gives an important interpretation of \(\hat{\mathbf{y}}\): it is the closest point to \(\mathbf{y}\) in the subspace \(L\).
The distance from \(\mathbf{y}\) to \(L\).
The distance from \(\mathbf{y}\) to \(L\) is the length of the perpendicular from \(\mathbf{y}\) to its orthogonal projection on \(L\), namely \(\hat{\mathbf{y}}\).
This distance equals the length of \(\mathbf{y} - \hat{\mathbf{y}}\).
In this example, the distance is
\[\Vert\mathbf{y}-\hat{\mathbf{y}}\Vert = \sqrt{(-1)^2 + 2^2} = \sqrt{5}.\]
Projections find Coordinates in an Orthogonal Basis
Earlier in this lectureopen, we saw that when we decompose a vector \(\mathbf{y}\) into a linear combination of vectors \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) in a orthogonal basis, we have
\[\mathbf{y} = c_1\mathbf{u}_1 + \dots + c_p\mathbf{u}_p\]
where
\[c_j = \frac{\mathbf{y}^T\mathbf{u}_j}{\mathbf{u}_j^T\mathbf{u}_j}\]
And just now we have seen that the projection of \(\mathbf{y}\) onto the subspace spanned by any \(\mathbf{u}\) is
\[\operatorname{proj}_L \mathbf{y} = \frac{\mathbf{y}^T\mathbf{u}}{\mathbf{u}^T\mathbf{u}}\mathbf{u}.\]
So a decomposition like \(\mathbf{y} = c_1\mathbf{u}_1 + \dots + c_p\mathbf{u}_p\) is really decomposing \(\mathbf{y}\) into a sum of orthogonal projections onto one-dimensional subspaces.
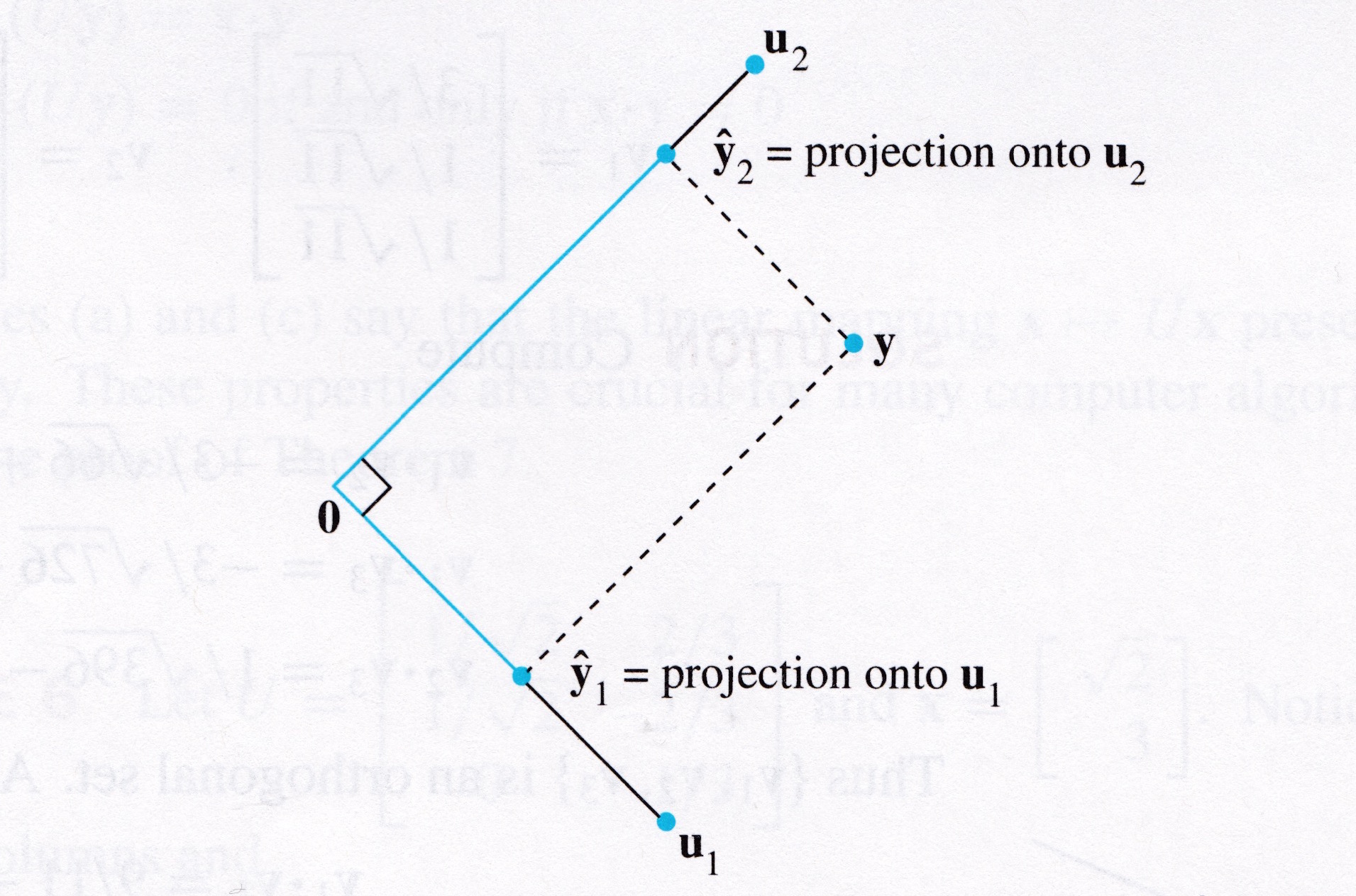
For example, let’s take the case where \(\mathbf{y} \in \mathbb{R}^2.\)
Let’s say we are given \(\mathbf{u}_1, \mathbf{u}_2\) such that \(\mathbf{u}_1\) is orthogonal to \(\mathbf{u}_2\), and so together they span \(\mathbb{R}^2.\)
Then \(\mathbf{y}\) can be written in the form
\[\mathbf{y} = \frac{\mathbf{y}^T\mathbf{u}_1}{\mathbf{u}_1^T\mathbf{u}_1}\mathbf{u}_1 + \frac{\mathbf{y}^T\mathbf{u}_2}{\mathbf{u}_2^T\mathbf{u}_2}\mathbf{u}_2.\]
The first term is the projection of \(\mathbf{y}\) onto the subspace spanned by \(\mathbf{u}_1\) and the second term is the projection of \(\mathbf{y}\) onto the subspace spanned by \(\mathbf{u}_2.\)
So this equation expresses \(\mathbf{y}\) as the sum of its projections onto the (orthogonal) axes determined by \(\mathbf{u}_1\) and \(\mathbf{u}_2\).
This is an useful way of thinking about coordinates in an orthogonal basis: coordinates are projections onto the axes!
Orthonormal Sets
Orthogonal sets are therefore very useful. However, they become even more useful if we normalize the vectors in the set.
A set \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) is an orthonormal set if it is an orthogonal set of unit vectors.
If \(W\) is the subspace spanned by such as a set, then \(\{\mathbf{u}_1,\dots,\mathbf{u}_p\}\) is an orthonormal basis for \(W\) since the set is automatically linearly independent.
The simplest example of an orthonormal set is the standard basis \(\{\mathbf{e}_1, \dots,\mathbf{e}_n\}\) for \(\mathbb{R}^n\).
Pro tip: keep the terms clear in your head:
- orthogonal is (just) perpendicular, while
- orthonormal is perpendicular and unit length.
(You can see the word “normalized” inside “orthonormal”).
Orthogonal Mappings
Matrices with orthonormal columns are particularly important.
Theorem. A \(m\times n\) matrix \(U\) has orthonormal columns if and only if \(U^TU = I\).
Proof. Let us suppose that \(U\) has only three columns which are each vectors in \(\mathbb{R}^m\) (but the proof will generalize to \(n\) columns).
Let \(U = [\mathbf{u}_1\;\mathbf{u}_2\;\mathbf{u}_3].\) Then:
\[U^TU = \begin{bmatrix}\mathbf{u}_1^T\\\mathbf{u}_2^T\\\mathbf{u}_3^T\end{bmatrix}\begin{bmatrix}\mathbf{u}_1&\mathbf{u}_2&\mathbf{u}_3\end{bmatrix}\]
\[ = \begin{bmatrix} \mathbf{u}_1^T\mathbf{u}_1&\mathbf{u}_1^T\mathbf{u}_2&\mathbf{u}_1^T\mathbf{u}_3\\ \mathbf{u}_2^T\mathbf{u}_1&\mathbf{u}_2^T\mathbf{u}_2&\mathbf{u}_2^T\mathbf{u}_3\\ \mathbf{u}_3^T\mathbf{u}_1&\mathbf{u}_3^T\mathbf{u}_2&\mathbf{u}_3^T\mathbf{u}_3 \end{bmatrix}\]
The columns of \(U\) are orthogonal if and only if
\[\mathbf{u}_1^T\mathbf{u}_2 = \mathbf{u}_2^T\mathbf{u}_1 = 0,\;\; \mathbf{u}_1^T\mathbf{u}_3 = \mathbf{u}_3^T\mathbf{u}_1 = 0,\;\; \mathbf{u}_2^T\mathbf{u}_3 = \mathbf{u}_3^T\mathbf{u}_2 = 0\]
The columns of \(U\) all have unit length if and only if
\[\mathbf{u}_1^T\mathbf{u}_1 = 1,\;\;\mathbf{u}_2^T\mathbf{u}_2 = 1,\;\;\mathbf{u}_3^T\mathbf{u}_3 = 1.\]
So \(U^TU = I.\)
Orthonormal Matrices Preserve Length and Orthogonality
Theorem. Let \(U\) by an \(m\times n\) matrix with orthonormal columns, and let \(\mathbf{x}\) and \(\mathbf{y}\) be in \(\mathbb{R}^n.\) Then:
1. \(\Vert U\mathbf{x}\Vert = \Vert\mathbf{x}\Vert.\) 2. \((U\mathbf{x})^T(U\mathbf{y}) = \mathbf{x}^T\mathbf{y}.\)
Proof of (1):
\[\Vert U\mathbf{x}\Vert = \sqrt{(U\mathbf{x})^T U\mathbf{x}} = \sqrt{\mathbf{x}^T\mathbf{x}} = \Vert\mathbf{x}\Vert.\]
Proof of (2):
\[(U\mathbf{x})^T(U\mathbf{y}) = \mathbf{x}^TU^T(U\mathbf{y}) = \mathbf{x}^T(U^TU)\mathbf{y} = \mathbf{x}^T\mathbf{y}.\]
These make important statements:
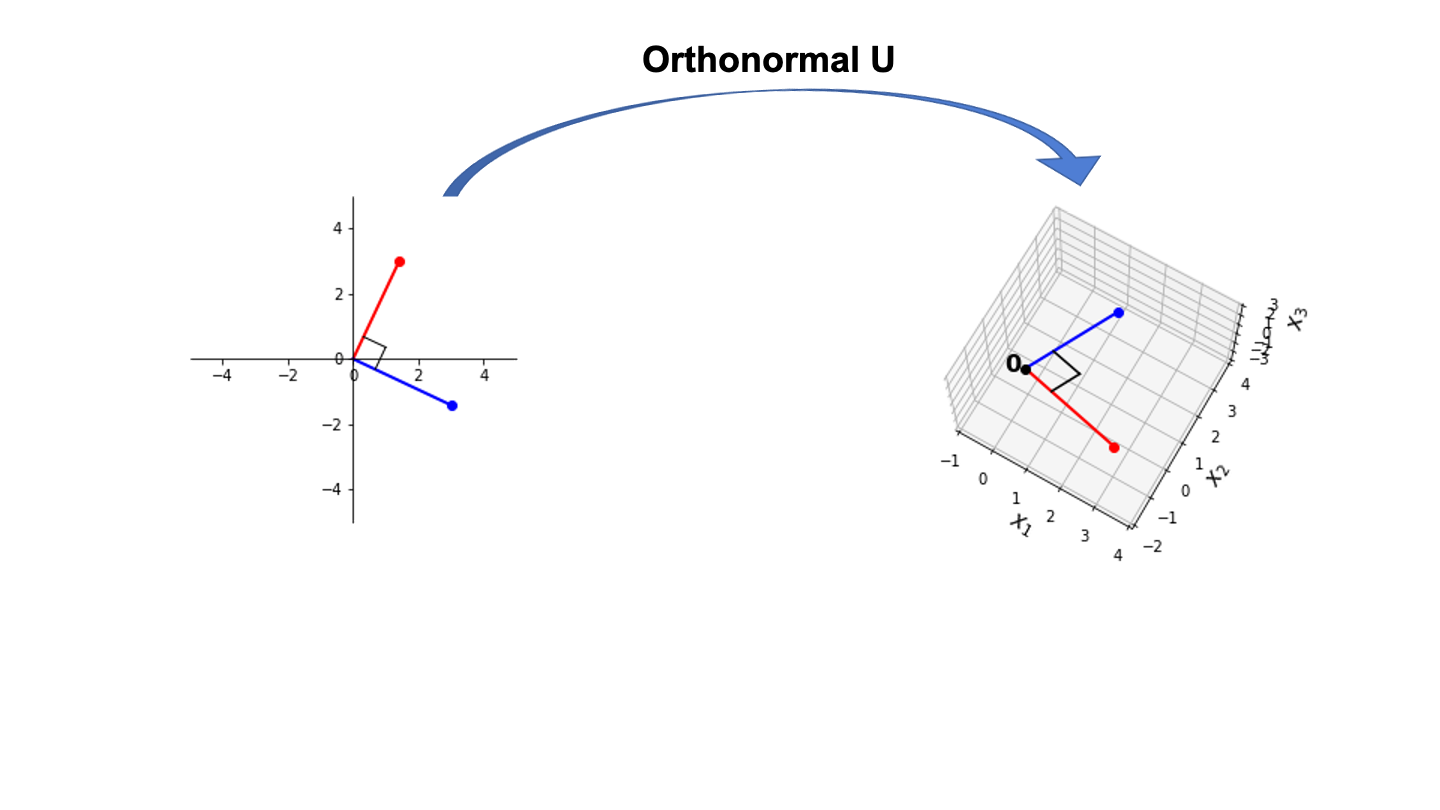
- Property (1) means that the mapping \(\mathbf{x}\mapsto U\mathbf{x}\) preserves the lengths of vectors – and, therefore, also the distance between any two vectors.
- Properties (1) and (2) together mean that the mapping \(\mathbf{x}\mapsto U\mathbf{x}\) preserves the angles between vectors – and, therefore, also any orthogonality between two vectors.
So, viewed as a linear operator, an orthonormal matrix is very special: the lengths of vectors, and therefore the distances between points is not changed by the action of \(U\).
Notice as well that \(U\) is \(m \times n\) – it may not be square.
So it may map vectors from one vector space to an entirely different vector space – but the distances between points will not be changed!
… and the orthogonality of vectors will not be changed!
Note however that we cannot in general construct an orthonormal map from a higher dimension to a lower one.
For example, three orthogonal vectors in \(\mathbb{R}^3\) cannot be mapped to three orthogonal vectors in \(\mathbb{R}^2\). Can you see why this is impossible? What is it about the definition of an orthonormal set that prevents this?
Example.
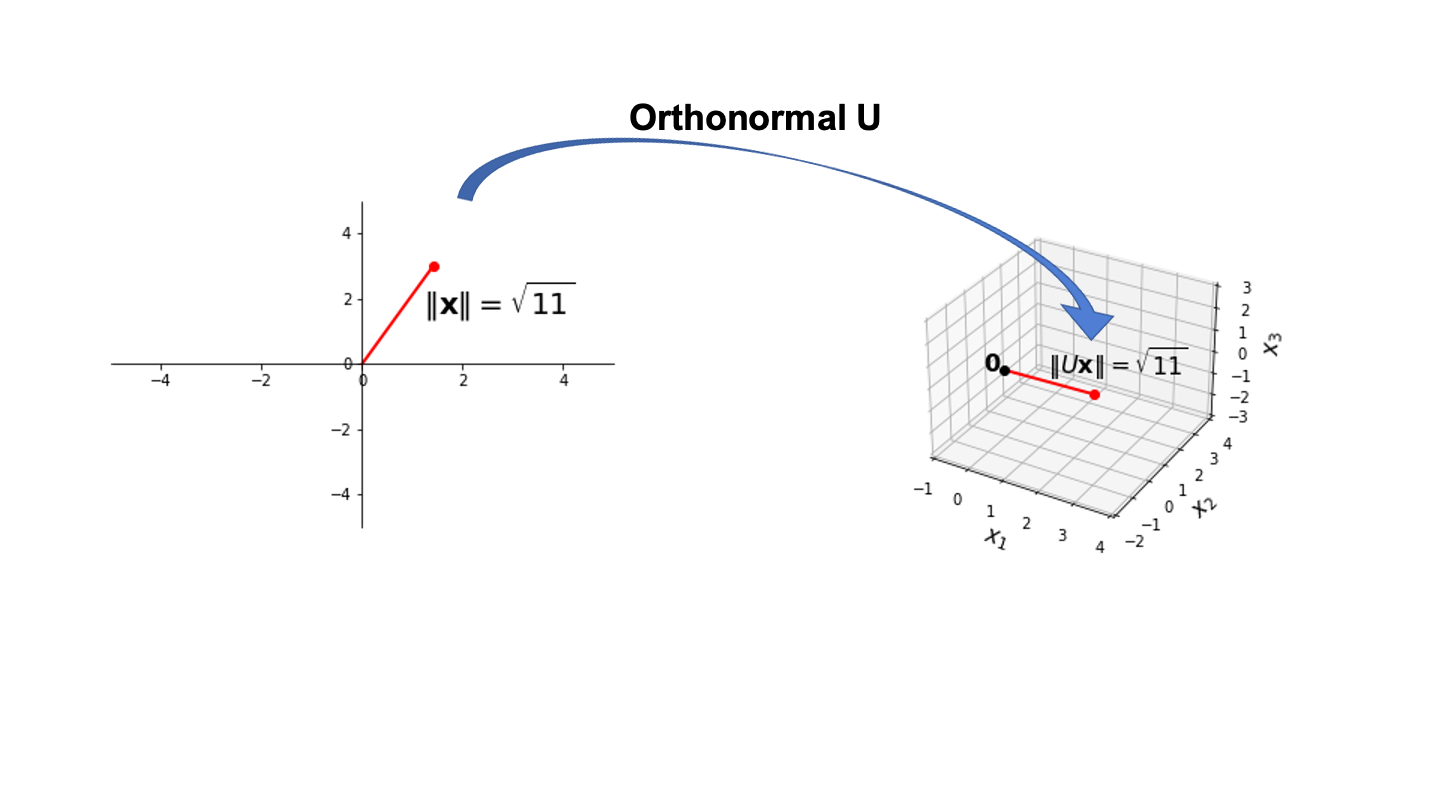
Let \(U = \begin{bmatrix}1/\sqrt{2}&2/3\\1/\sqrt{2}&-2/3\\0&1/3\end{bmatrix}\) and \(\mathbf{x} = \begin{bmatrix}\sqrt{2}\\3\end{bmatrix}.\)
Notice that \(U\) has orthonormal columns, so
\[U^TU = \begin{bmatrix}1/\sqrt{2}&1/\sqrt{2}&0\\2/3&-2/3&1/3\end{bmatrix}\begin{bmatrix}1/\sqrt{2}&2/3\\1/\sqrt{2}&-2/3\\0&1/3\end{bmatrix} = \begin{bmatrix}1&0\\0&1\end{bmatrix}.\]
Let’s verify that \(\Vert Ux\Vert = \Vert x\Vert.\)
\[U\mathbf{x} = \begin{bmatrix}1/\sqrt{2}&2/3\\1/\sqrt{2}&-2/3\\0&1/3\end{bmatrix}\begin{bmatrix}\sqrt{2}\\3\end{bmatrix} = \begin{bmatrix}3\\-1\\1\end{bmatrix}\]
\[\Vert U\mathbf{x}\Vert = \sqrt{9 + 1 + 1} = \sqrt{11}.\]
\[\Vert\mathbf{x}\Vert = \sqrt{2+9}= \sqrt{11}.\]
When Orthonormal Matrices are Square
Finally, one of the most useful transformation matrices is obtained when the columns of the matrix are orthonormal…
… and the matrix is square.
These matrices map vectors in \(\mathbb{R}^n\) to new locations in the same space, ie, \(\mathbb{R}^n\).
… in a way that preserves lengths, distances and orthogonality.
Now, consider the case when \(U\) is square, and has orthonormal columns.
Then the fact that \(U^TU = I\) implies that \(U^{-1} = U^T.\)
Then \(U\) is called an orthogonal matrix.
A good example of an orthogonal matrix is a rotation matrix:
\[{\displaystyle R ={\begin{bmatrix}\cos \theta &-\sin \theta \\\sin \theta &\cos \theta \\\end{bmatrix}}.}\]
Using trigonometric identities, you should be able to convince yourself that
\[R^TR = I\]
and hopefully you can visualize how \(R\) preserves lengths and orthogonality.