Eigenvectors and Eigenvalues
Many parts of this page are based on Linear Algebra and its Applications, by David C. Lay
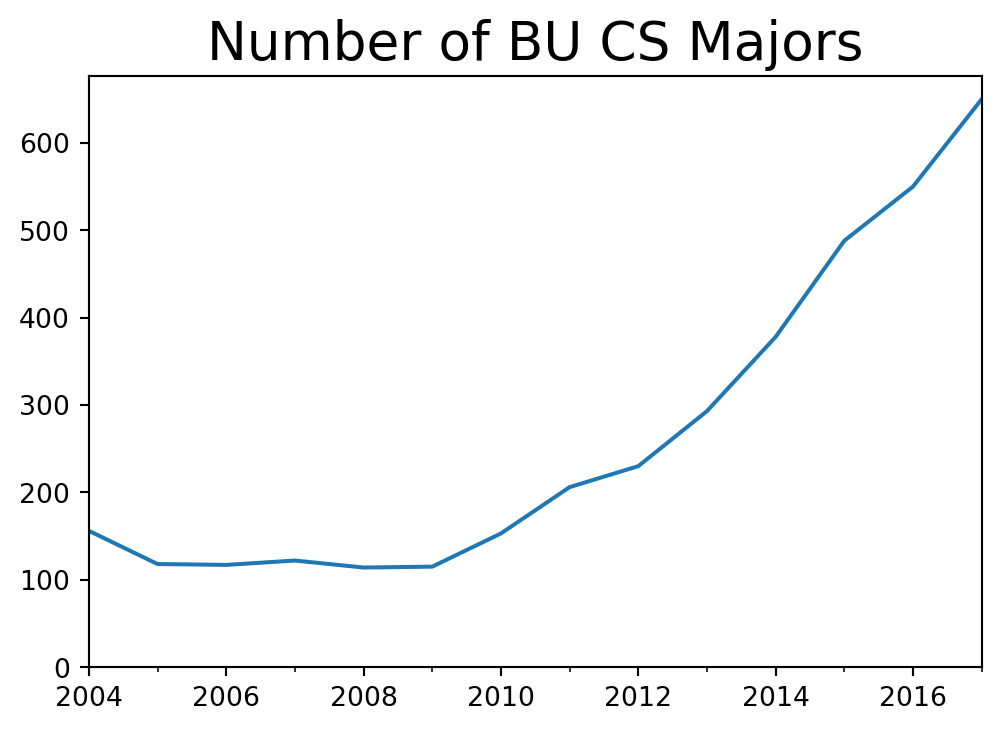
During the time period shown, the number of CS majors was growing very rapidly. I needed to have some estimate of where the numbers might be going.
Modeling the number of students in the CS major is challenging because students enter and leave the major at various points during their undergraduate degree.
We will use a linear difference model that we will train on historical data.
Our state variable is
\[\mathbf{x}_t = \begin{bmatrix}x_{1,t}\\ x_{2,t}\\ x_{3,t}\\ x_{4,t}\end{bmatrix}\]
where \(x_{i,t}\) is the number of students who are declared CS majors and in their \(i\)th year at BU, in the fall of year \(t\).
Our model is a linear dynamical system:
\[ \mathbf{x}_{t+1} = A \mathbf{x}_t.\]
Given historical data which are measurements of our state variable from past years, we can estimate \(A\) by a method called least squares.
(We will cover least squares later in the semester.)
Here is the \(A\) that we get when look at historical data:
print(A)[[ 0.62110633 0.28792787 0.0204491 0.10003897]
[ 0.65239203 0.55574243 0.30323349 -0.16349735]
[ 0.33101614 1.24636712 -0.26153545 0.07684781]
[ 0.49319575 -0.30684656 1.00419585 0.07532737]]Now, using \(A\), we can predict growth into the future via \(\mathbf{x}_{t+1} = A \mathbf{x}_t.\)
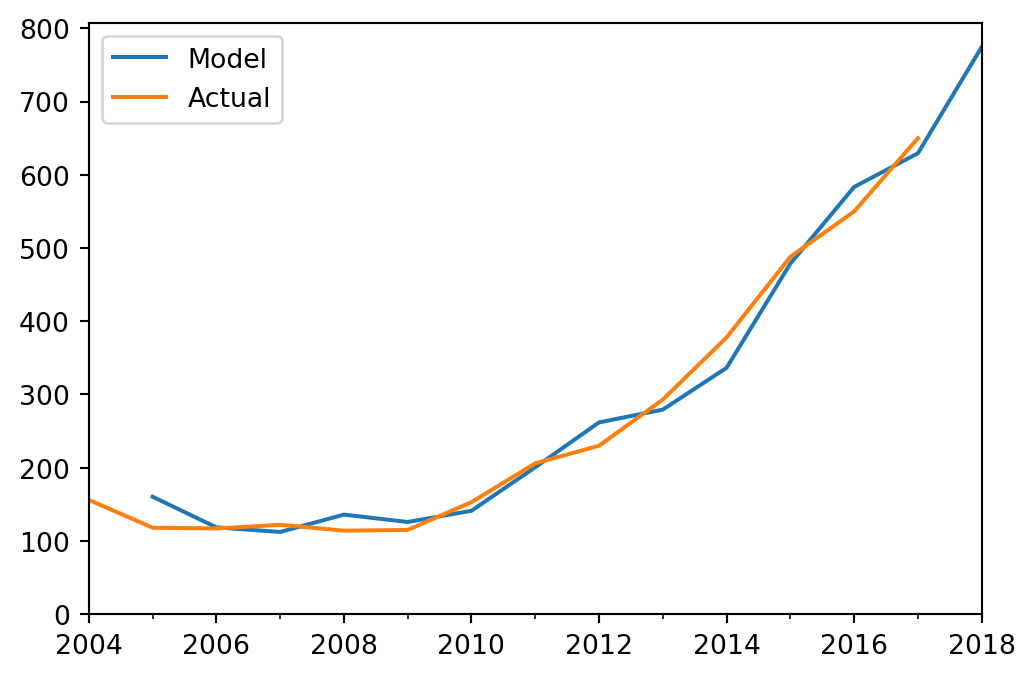
Notice how the matrix \(A\) captures the complex way that one year’s student population relates to the next year’s population.
Because of this complexity, can be hard to understand what is going on just by looking at the values of \(A\).
But, when we look at the plot above, it appears that there is a relatively simple kind of exponential growth going on.
Can we “extract” this exponential growth model from \(A\)? How?
Today’s lecture will start to develop the tools to answer such questions (and more).
Eigenvectors and Eigenvalues
As we’ve seen, linear transformations (thinking geometrically) can “move” a vector to a new location.
For example, a linear transformation \(A\mathbf{x}\) can do the following to \(\mathbf{x}\):
- rotate \(\mathbf{x}\)
- reflect \(\mathbf{x}\)
- shear \(\mathbf{x}\)
- project \(\mathbf{x}\)
- scale \(\mathbf{x}\)
Of the above transformations, one is a bit different: scaling.
That is because, if a matrix \(A\) scales \(\mathbf{x}\),
that transformation could also have been expressed without a matrix-vector multiplication
that is, a scalinbg can be simply written as \(\lambda\mathbf{x}\) for some scalar value \(\lambda\).
In many ways, life would be simpler if we could avoid all of the complexities of rotation, reflection, and projection … and only work in terms of scaling.
That is the idea we will develop today.
Let’s start with a simple example: a shear matrix:
\[ A = \begin{bmatrix}1&0.1\\0&1\end{bmatrix} \]
Let’s look at what this matrix does to each point in the plane.
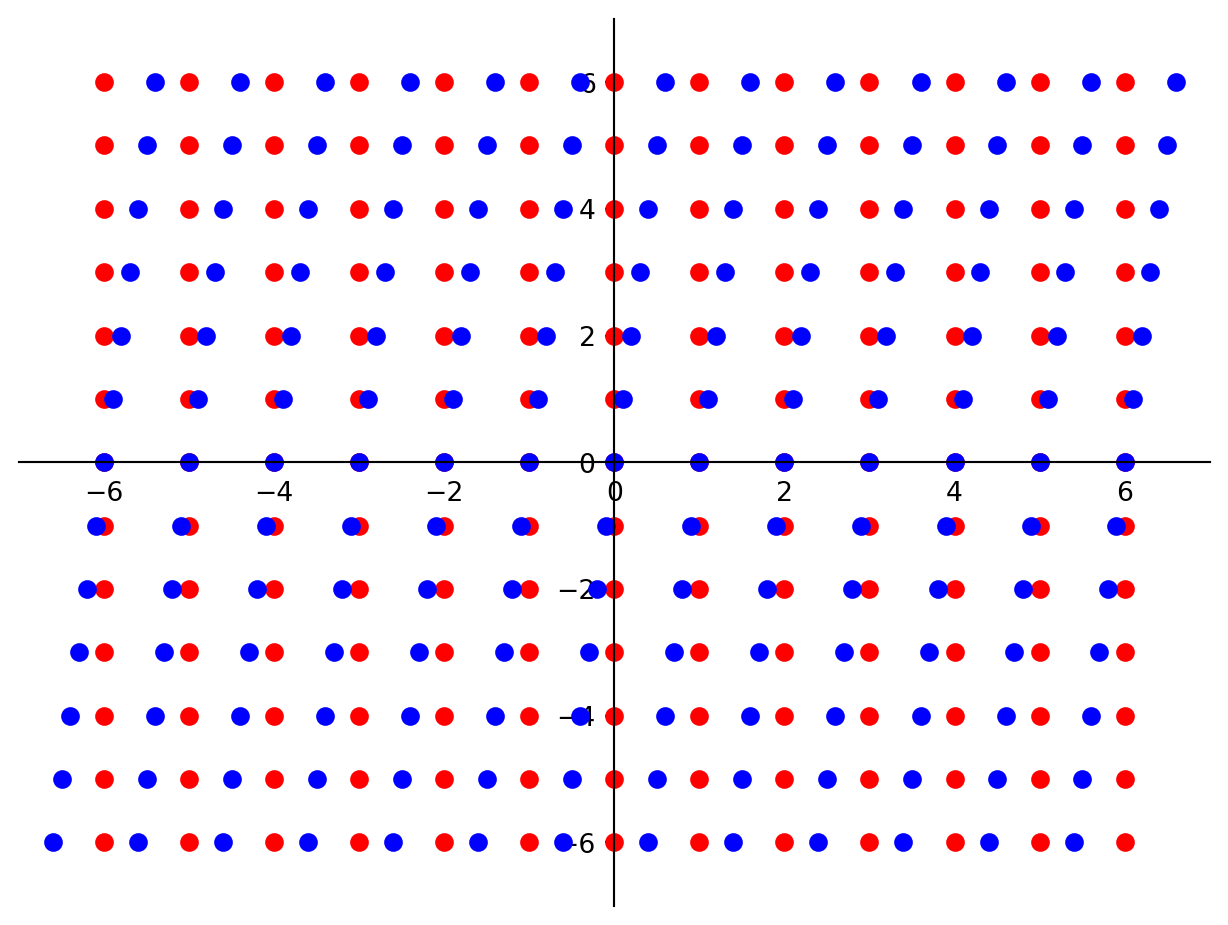
We can use arrows to show how each red point is moved to the corresponding blue point.
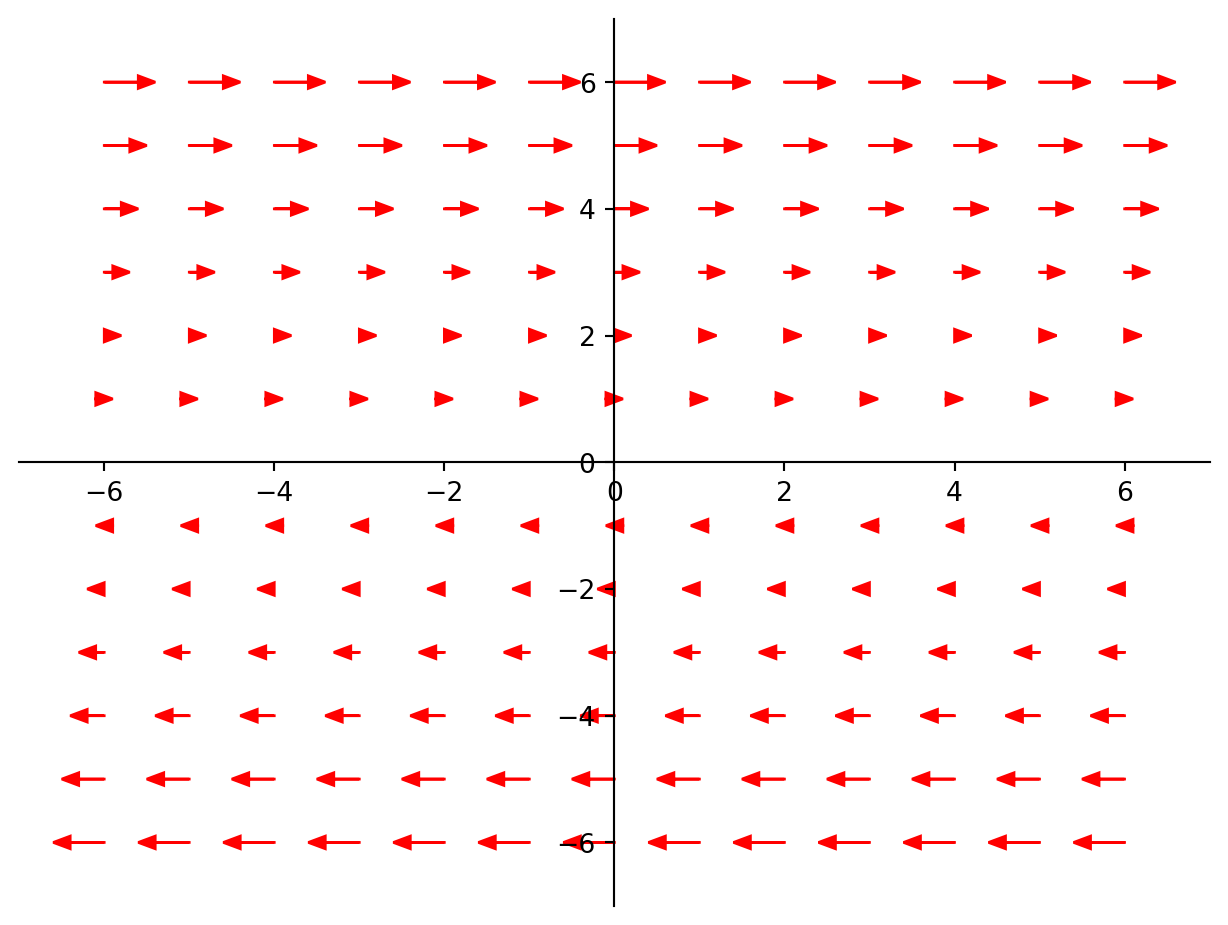
Now let’s look at a more complicated situation.
Consider the matrix \(A = \begin{bmatrix}1.0&0.2\\0.1&0.9\end{bmatrix}\).
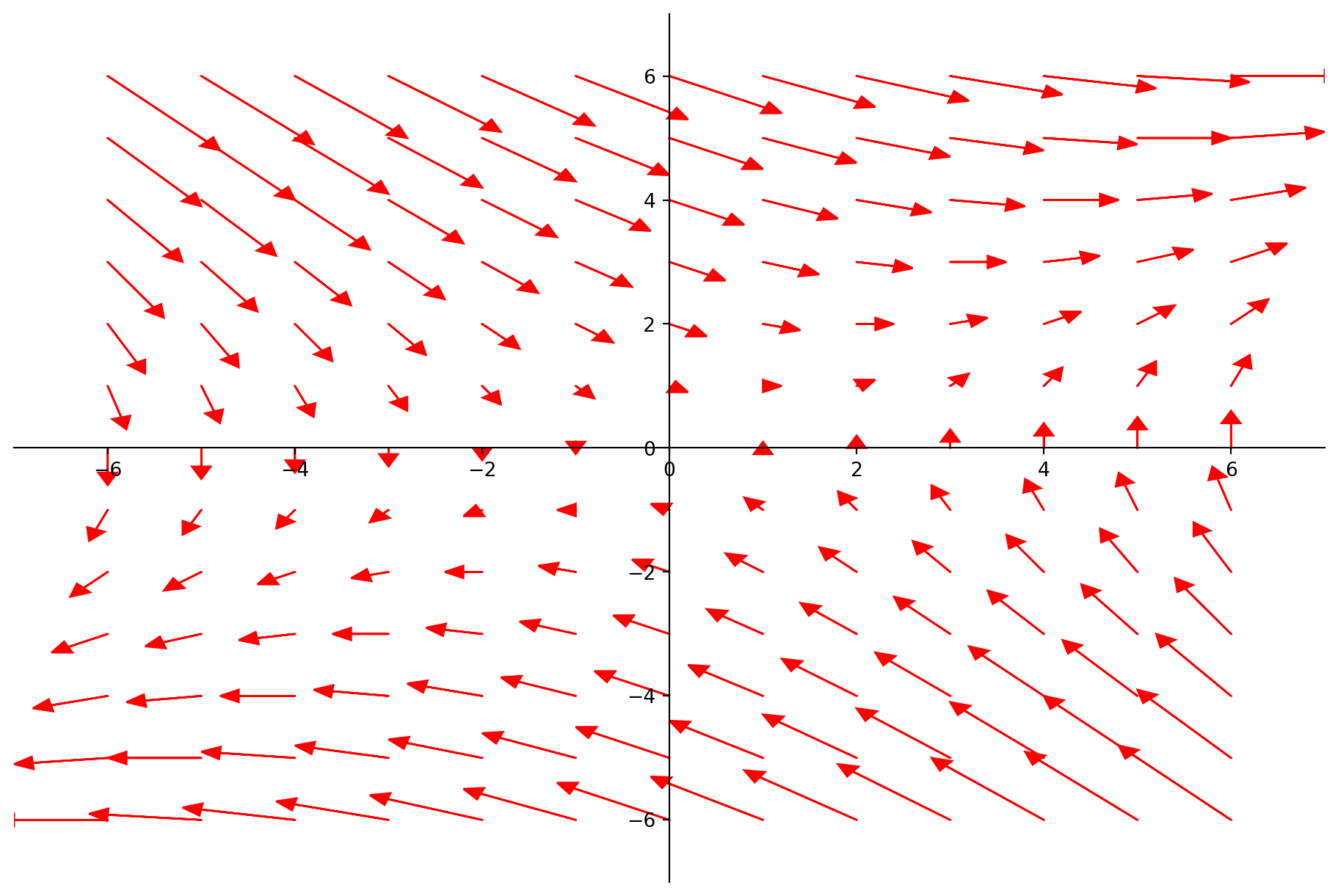
The starting point for understanding what \(A\) does is to look for special vectors which do not change their direction when multiplied by \(A\).
Example.
Let \(A = \begin{bmatrix}3&-2\\1&0\end{bmatrix}, \mathbf{u} = \begin{bmatrix}-1\\1\end{bmatrix}, \mathbf{v}=\begin{bmatrix}2\\1\end{bmatrix}.\) The images of \(\mathbf{u}\) and \(\mathbf{v}\) under multiplication by \(A\) are shown here:
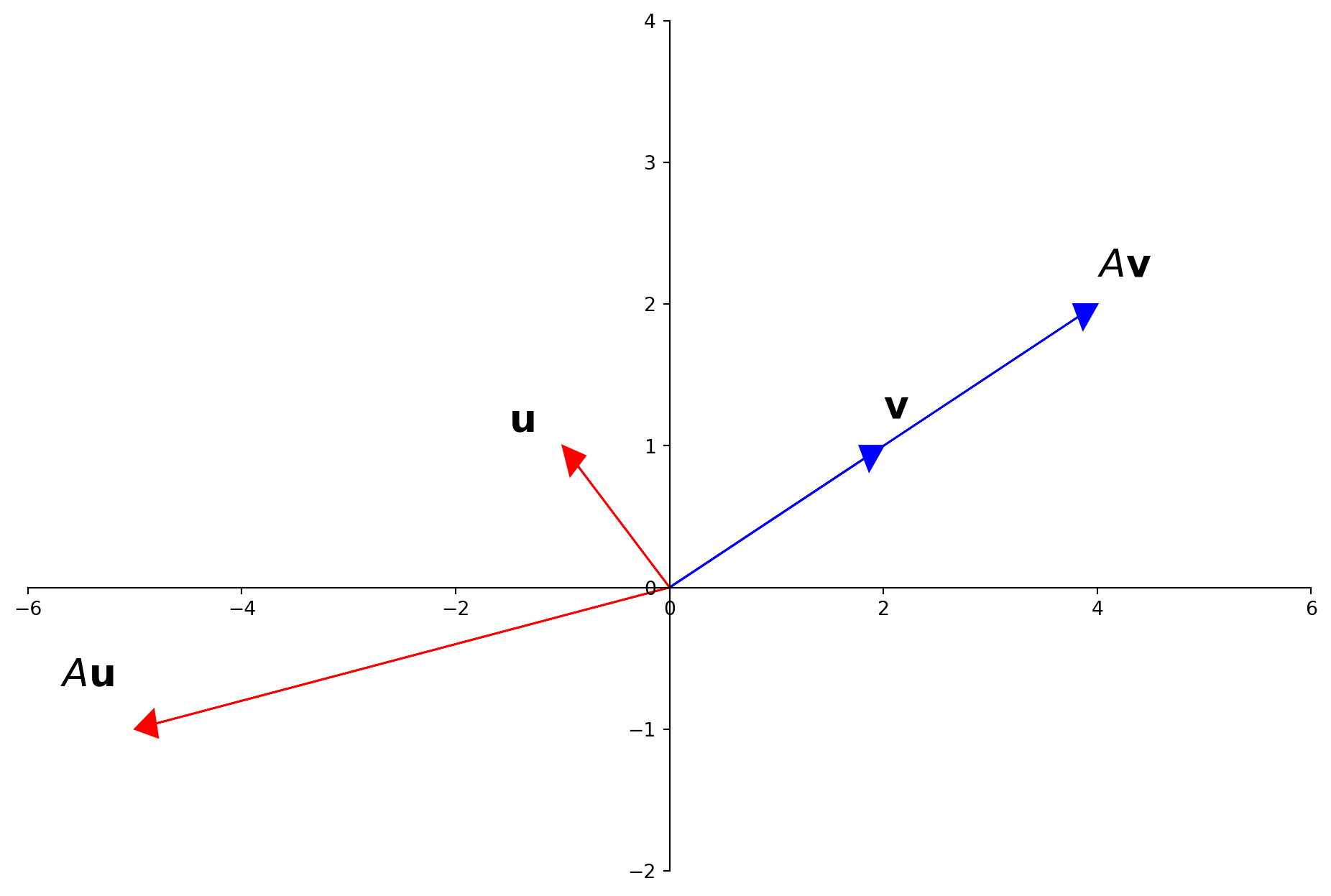
For a “typical” vector (like \(\mathbf{u}\)) the action of \(A\) is to scale, reflect, and/or rotate it.
But for some special vectors (like \(\mathbf{v}\)) the action of \(A\) is only to “stretch” it (without any rotation or reflection).
In fact, \(A\mathbf{v}\) is simply \(2\mathbf{v}.\)
Today we will by studying equations such as
\[ A\mathbf{x} = 2\mathbf{x}\;\;\;\;\text{or}\;\;\;\;A\mathbf{x} = -4\mathbf{x}\]
where special vectors are transformed by \(A\) into scalar multiples of themselves.
Definitions.
An eigenvector of an \(n\times n\) matrix \(A\) is a nonzero vector \(\mathbf{x}\) such that \(A\mathbf{x} = \lambda\mathbf{x}\) for some scalar \(\lambda.\)
A scalar \(\lambda\) is called an eigenvalue of \(A\) if there is a nontrivial solution \(\mathbf{x}\) of \(A\mathbf{x} = \lambda\mathbf{x}.\)
Such an \(\mathbf{x}\) is called an eigenvector corresponding to \(\lambda.\)
Checking Eigenvectors and Eigenvalues
Before considering how to compute eigenvectors, let’s look at simply how to determine if a given vector is an eigenvector of a matrix.
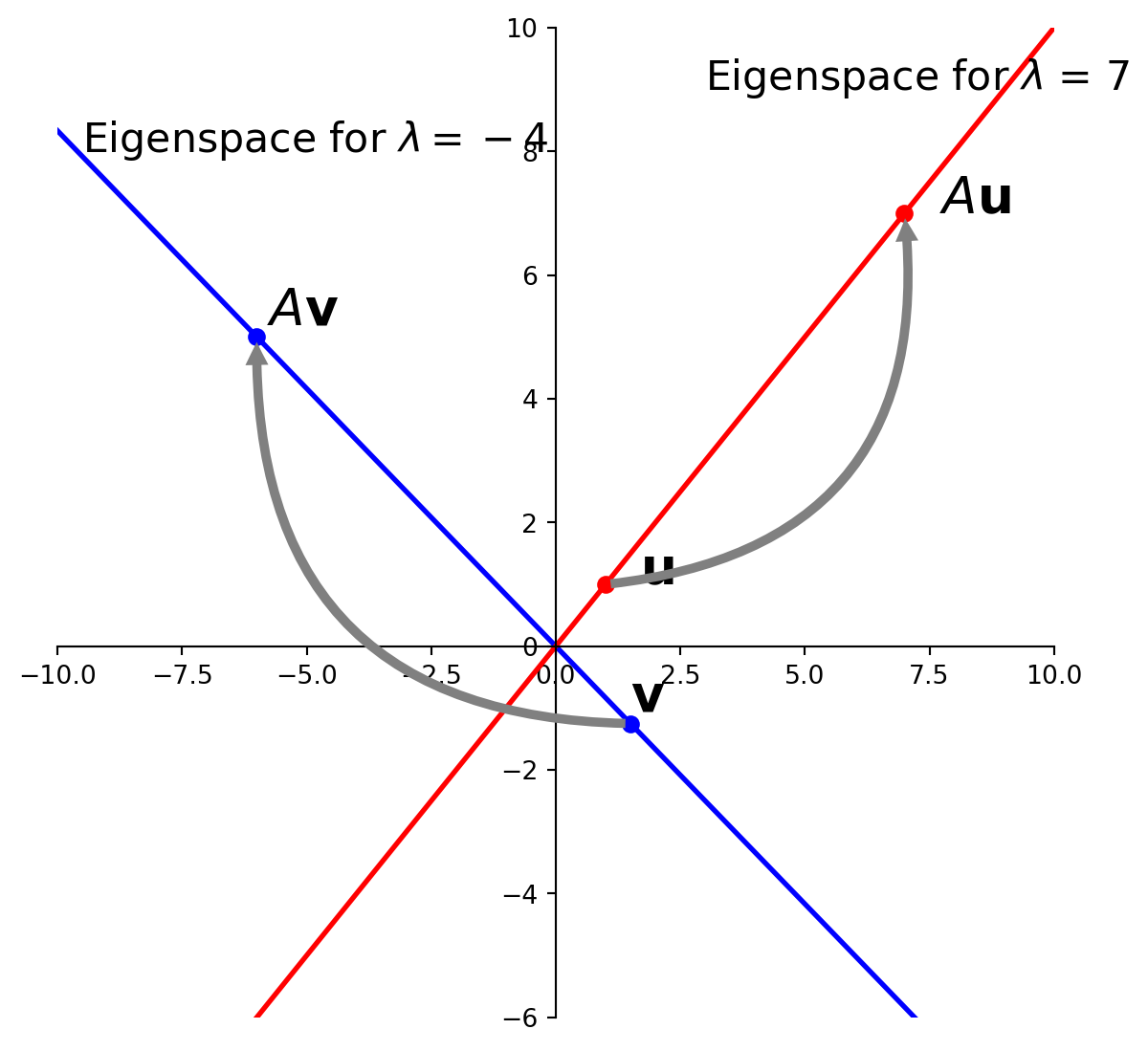
Example. Let \(A = \begin{bmatrix}1&6\\5&2\end{bmatrix}, \mathbf{u} = \begin{bmatrix}6\\-5\end{bmatrix}, \mathbf{v}=\begin{bmatrix}3\\-2\end{bmatrix}.\)
Are \(\mathbf{u}\) and \(\mathbf{v}\) eigenvectors of \(A\)?
Solution.
\[A\mathbf{u} = \begin{bmatrix}1&6\\5&2\end{bmatrix}\begin{bmatrix}6\\-5\end{bmatrix} = \begin{bmatrix}-24\\20\end{bmatrix} = -4\begin{bmatrix}6\\-5\end{bmatrix} = -4\mathbf{u}.\]
\[A\mathbf{v} = \begin{bmatrix}1&6\\5&2\end{bmatrix}\begin{bmatrix}3\\-2\end{bmatrix} = \begin{bmatrix}-9\\11\end{bmatrix} \neq \lambda\begin{bmatrix}3\\-2\end{bmatrix}.\]
So \(\mathbf{u}\) is an eigenvector corresponding to the eigenvalue \(-4\),
but \(\mathbf{v}\) is not an eigenvector of \(A\).
Finding Eigenvectors
Our first task will be to find eigenvectors. We’ll start by working through an example.
Example. Let’s use the same matrix \(A = \begin{bmatrix}1&6\\5&2\end{bmatrix}.\)
We’ll now show that 7 is an eigenvalue of the matrix \(A\), and we will find the corresponding eigenvectors.
For 7 to be an eigenvalue of \(A\), it must be the case that
\[ A\mathbf{x}=7\mathbf{x}\]
has a nontrivial solution.
This is equivalent to:
\[ A\mathbf{x} - 7\mathbf{x} = {\bf 0}\]
or
\[ (A - 7I)\mathbf{x} = {\bf 0}.\]
To solve this homogeneous equation, form the matrix
\[A - 7I = \begin{bmatrix}1&6\\5&2\end{bmatrix}-\begin{bmatrix}7&0\\0&7\end{bmatrix} = \begin{bmatrix}-6&6\\5&-5\end{bmatrix}.\]
To see that \((A - 7I)\mathbf{x} = {\bf 0}\) has a nontrivial solution, observe that the columns of \(A-7I\) are obviously linearly dependent.
So there are nonzero vectors that are solutions of \((A - 7I)\mathbf{x} = {\bf 0}\).
So 7 is an eigenvalue of \(A\).
To find the corresponding eigenvectors, we solve \((A - 7I)\mathbf{x} = {\bf 0}\) using row operations:
\[\begin{bmatrix}-6&6&0\\5&-5&0\end{bmatrix}\sim\begin{bmatrix}1&-1&0\\0&0&0\end{bmatrix}.\]
This says that \(x_1 = x_2,\) and \(x_2\) is free.
So the general solution has the form \(x_2\begin{bmatrix}1\\1\end{bmatrix}.\)
Each vector of this form with \(x_2 \neq 0\) is an eigenvector corresponding to \(\lambda = 7.\)
Eigenspace
Now, let’s generalize what we just did.
From the previous example, we can conclude that \(\lambda\) is an eigenvalue of an \(n\times n\) matrix \(A\) if and only if the equation
\[(A-\lambda I)\mathbf{x} = {\bf 0}\]
has a nontrivial solution.
Notice that the set of all solutions of that equation is just
the null space of the matrix \(A-\lambda I.\)
So the set of all eigenvectors corresponding to a particular \(\lambda\) (along with the trivial solution, that is the \(\mathbf{0}\) vector) forms a subspace of \(\mathbb{R}^n\),
and is called the eigenspace of \(A\) corresponding to \(\lambda\).
Example. For matrix \(A = \begin{bmatrix}1&6\\5&2\end{bmatrix},\) we found that the general solution for the eigenvector corresponding to \(\lambda = 7\) is the expression \(x_2\begin{bmatrix}1\\1\end{bmatrix}.\)
This means that the eigenspace corresponding to \(\lambda = 7\) consist|s of all multiples of \(\begin{bmatrix}1\\1\end{bmatrix},\)
… in other words \(\operatorname{Span}\left\{\begin{bmatrix}1\\1\end{bmatrix}\right\}\).
So we would also say that \(\left\{\begin{bmatrix}1\\1\end{bmatrix}\right\}\) is a basis for the eigenspace corresponding to \(\lambda = 7\).
We could also show that the eigenspace corresponding to \(\lambda = -4\) is \(\operatorname{Span}\left\{\begin{bmatrix}-6\\5\end{bmatrix}\right\}\)
Example. Let \(A = \begin{bmatrix}4&-1&6\\2&1&6\\2&-1&8\end{bmatrix}.\) An eigenvalue of \(A\) is \(2.\) Find a basis for the the corresponding eigenspace.
Solution. The eigenspace we are looking for is the nullspace of \(A - 2I.\)
We will use the strategy for finding a basis for a nullspace that we learned in the last lecture.
Form
\[A - 2I = \begin{bmatrix}4&-1&6\\2&1&6\\2&-1&8\end{bmatrix}-\begin{bmatrix}2&0&0\\0&2&0\\0&0&2\end{bmatrix} = \begin{bmatrix}2&-1&6\\2&-1&6\\2&-1&6\end{bmatrix}\]
and row reduce the augmented matrix for \((A-2I)\mathbf{x}={\bf 0}\):
\[\begin{bmatrix}2&-1&6&0\\2&-1&6&0\\2&-1&6&0\end{bmatrix} \sim \begin{bmatrix}2&-1&6&0\\0&0&0&0\\0&0&0&0\end{bmatrix}\]
At this point, it is clear that 2 is indeed an eigenvalue of \(A\),
because the equation \((A-2I)\mathbf{x} = {\bf 0}\) has free variables.
The general solution is \(x_1 = \frac{1}{2}x_2 -3x_3.\)
Expressed as a vector, the general solution is:
\[\begin{bmatrix}\frac{1}{2}x_2 - 3x_3\\x_2\\x_3\end{bmatrix}.\]
Expressed as a vector sum, this is:
\[x_2\begin{bmatrix}1/2\\1\\0\end{bmatrix} + x_3\begin{bmatrix}-3\\0\\1\end{bmatrix}\;\;\;\;\text{with $x_2$ and $x_3$ free.}\]
So this eigenspace is a two-dimensional subspace of \(\mathbb{R}^3,\) and a basis for this subspace is
\[\left\{\begin{bmatrix}1/2\\1\\0\end{bmatrix},\begin{bmatrix}-3\\0\\1\end{bmatrix}\right\}.\]
Eigenvalues of a Triangular Matrix
Theorem. The eigenvalues of a triangular matrix are the entries on its main diagonal.
Proof. We’ll consider the \(3\times 3\) case. If \(A\) is upper triangular, then \(A-\lambda I\) has the form
\[A - \lambda I = \begin{bmatrix}a_{11}&a_{12}&a_{13}\\0&a_{22}&a_{23}\\0&0&a_{33}\end{bmatrix} - \begin{bmatrix}\lambda&0&0\\0&\lambda&0\\0&0&\lambda\end{bmatrix}\]
\[ = \begin{bmatrix}a_{11}-\lambda&a_{12}&a_{13}\\0&a_{22}-\lambda&a_{23}\\0&0&a_{33}-\lambda\end{bmatrix}\]
Now, \(\lambda\) is an eigenvalue of \(A\) if and only if the equation \((A-\lambda I)\mathbf{x} = {\bf 0}\) has a nontrivial solution –
in other words, if and only if the equation has a free variable.
The special pattern that the zero entries have in \(A\) means that there will be a free variable if any diagonal entry is also zero, because then there will be a column without a pivot.
That is, \((A-\lambda I)\mathbf{x} = {\bf 0}\) has a free variable if and only if at least one of the entries on the diagonal of \((A-\lambda I)\) is zero.
This happens if and only if \(\lambda\) equals one of the entries \(a_{11}, a_{22},\) or \(a_{33}\) on the diagonal of \(A\).
Example. Let \(A = \begin{bmatrix}3&6&-8\\0&0&6\\0&0&2\end{bmatrix}\) and \(B = \begin{bmatrix}4&0&0\\-2&1&0\\5&3&4\end{bmatrix}\).
Then the eigenvalues of \(A\) are 3, 0, and 2. The eigenvalues of \(B\) are 4 and 1.
Invertibility and Eigenvalues
So far we haven’t probed what it means for a matrix to have an eigenvalue of 0.
This happens if and only if the equation \(A\mathbf{x} = 0\mathbf{x}\) has a nontrivial solution.
But that equation is equivalent to \(A\mathbf{x} = {\bf 0}\) which has a nontrivial solution if and only if \(A\) is not invertible.
This means that
This draws an important connection between invertibility and zero eigenvalues.
So we have yet another addition to the Invertible Matrix Theorem!
Eigenvectors Solve Difference Equations
Let’s return to the problem we considered at the outset: predicting future values of \(\mathbf{x}_t\) (the number of CS majors of each class in year \(t\)).
We modeled the future as \(\mathbf{x}_{t+1} = A\mathbf{x}_t\;\;\;(t = 0,1,2,\dots).\)
So then \(\mathbf{x}_{t} = A^t\mathbf{x}_0\;\;\;(t = 0,1,2,\dots).\)
A solution of such an equation is an explicit description of \(\{\mathbf{x}_t\}\) whose formula for each \(\mathbf{x}_t\) does not depend directly on \(A\) or on the preceding terms in the sequence other than the initial term \(\mathbf{x}_0.\)
The simplest way to build a solution is to take an eigenvector \(\mathbf{x}_0\) and its corresponding eigenvalue \(\lambda\).
Then
\[ \mathbf{x}_t = \lambda^t \mathbf{x}_0 \;\;\;(t = 0,1,2,\dots)\]
This sequence is a solution because
\[A\mathbf{x}_t = A(\lambda^t\mathbf{x}_0) = \lambda^t(A\mathbf{x}_0) = \lambda^t(\lambda\mathbf{x}_0) = \lambda^{t+1}\mathbf{x}_0 = \mathbf{x}_{t+1}.\]
We can extend this to combinations of eigenvectors.
If \(A\) has two eigenvectors \(\mathbf{u}\) and \(\mathbf{v}\) corresponding to eigenvalues \(\lambda\) and \(\mu\), then another solution is
\[\mathbf{x}_t = \lambda^t\mathbf{u} + \mu^t \mathbf{v}\]
To address the problem of predicting the CS major population,
we assume that we can express the state vector \(\mathbf{x}\) as a linear combination of eigenvectors \(\mathbf{u}_1, \mathbf{u}_2, \dots,\mathbf{u}_p\).
That is,
\[\mathbf{x}_0 = a_1\mathbf{u}_1 + a_2\mathbf{u}_2+\dots+a_p\mathbf{u}_p.\]
Then at time \(t\),
\[\mathbf{x}_t = \lambda_1^ta_1\mathbf{u}_1 + \lambda_2^ta_2\mathbf{u}_2 + \dots + \lambda_p^ta_p\mathbf{u}_p.\]
Which gives us an explicit solution for the number of students in the major in any future year.
Note that the expression above is exponential in each of the \(\lambda_1,\dots,\lambda_p\).
The resulting value will be essentially determined by the largest \(\lambda_i\).
To see this, let’s say that \(\lambda_1\) is the largest eigenvalue, and \(\lambda_2\) is the second largest.
Then the proportion of \(\mathbf{u}_1\) to \(\mathbf{u}_2\) contained in \(\mathbf{x}_t\) will be given by \((\lambda_1/\lambda_2)^t\).
Since this ratio is larger than 1, the relative proportion of \(\mathbf{u}_1\) will grow exponentially.
This shows the importance of the largest eigenvalue in the value of \(\mathbf{x}_t\) for large \(t\).
In the long run, \(\mathbf{x}_t\) will be very close to \(\lambda_1^t\mathbf{u}_1.\)
The largest eigenvalue shows the asymptotic rate of growth (or shrinkage) of the state vector \(\mathbf{x}_t\).
For the matrix \(A\) that describes CS major population growth, the largest eigenvalue is 1.19.
In other words, this models the population growth rate of CS majors at that time as increasing about 19% per year.