Show code cell source
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import matplotlib as mp
import sklearn
from IPython.display import Image, HTML
import statsmodels.api as sm
from sklearn import model_selection
from sklearn import metrics
import laUtilities as ut
%matplotlib inline
from statsmodels.sandbox.regression.predstd import wls_prediction_std
from statsmodels.regression.linear_model import OLS
import statsmodels.formula.api as smf
np.random.seed(9876789)
Regularization#
Today, we’ll look at some additional aspects of Linear Regression.
Our first topic is multicollinearity.
Multicollinearity#
To illustrate the multcollinearity problem, we’ll load a standard dataset.
The Longley dataset contains various US macroeconomic variables from 1947–1962.
Note
A good reference for the following is https://www.sjsu.edu/faculty/guangliang.chen/Math261a/Ch9slides-multicollinearity.pdf and https://www.stat.cmu.edu/~ryantibs/datamining/lectures/17-modr2.pdf
from statsmodels.datasets.longley import load_pandas
y = load_pandas().endog
X = load_pandas().exog
X['const'] = 1.0
X.index = X['YEAR']
y.index = X['YEAR']
X.drop('YEAR', axis = 1, inplace = True)
X
| GNPDEFL | GNP | UNEMP | ARMED | POP | const | |
|---|---|---|---|---|---|---|
| YEAR | ||||||
| 1947.0 | 83.0 | 234289.0 | 2356.0 | 1590.0 | 107608.0 | 1.0 |
| 1948.0 | 88.5 | 259426.0 | 2325.0 | 1456.0 | 108632.0 | 1.0 |
| 1949.0 | 88.2 | 258054.0 | 3682.0 | 1616.0 | 109773.0 | 1.0 |
| 1950.0 | 89.5 | 284599.0 | 3351.0 | 1650.0 | 110929.0 | 1.0 |
| 1951.0 | 96.2 | 328975.0 | 2099.0 | 3099.0 | 112075.0 | 1.0 |
| 1952.0 | 98.1 | 346999.0 | 1932.0 | 3594.0 | 113270.0 | 1.0 |
| 1953.0 | 99.0 | 365385.0 | 1870.0 | 3547.0 | 115094.0 | 1.0 |
| 1954.0 | 100.0 | 363112.0 | 3578.0 | 3350.0 | 116219.0 | 1.0 |
| 1955.0 | 101.2 | 397469.0 | 2904.0 | 3048.0 | 117388.0 | 1.0 |
| 1956.0 | 104.6 | 419180.0 | 2822.0 | 2857.0 | 118734.0 | 1.0 |
| 1957.0 | 108.4 | 442769.0 | 2936.0 | 2798.0 | 120445.0 | 1.0 |
| 1958.0 | 110.8 | 444546.0 | 4681.0 | 2637.0 | 121950.0 | 1.0 |
| 1959.0 | 112.6 | 482704.0 | 3813.0 | 2552.0 | 123366.0 | 1.0 |
| 1960.0 | 114.2 | 502601.0 | 3931.0 | 2514.0 | 125368.0 | 1.0 |
| 1961.0 | 115.7 | 518173.0 | 4806.0 | 2572.0 | 127852.0 | 1.0 |
| 1962.0 | 116.9 | 554894.0 | 4007.0 | 2827.0 | 130081.0 | 1.0 |
ols_model = sm.OLS(y, X)
ols_results = ols_model.fit()
print(ols_results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 0.987
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 156.4
Date: Wed, 12 Jul 2023 Prob (F-statistic): 3.70e-09
Time: 12:44:03 Log-Likelihood: -117.83
No. Observations: 16 AIC: 247.7
Df Residuals: 10 BIC: 252.3
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
GNPDEFL -48.4628 132.248 -0.366 0.722 -343.129 246.204
GNP 0.0720 0.032 2.269 0.047 0.001 0.143
UNEMP -0.4039 0.439 -0.921 0.379 -1.381 0.573
ARMED -0.5605 0.284 -1.975 0.077 -1.193 0.072
POP -0.4035 0.330 -1.222 0.250 -1.139 0.332
const 9.246e+04 3.52e+04 2.629 0.025 1.41e+04 1.71e+05
==============================================================================
Omnibus: 1.572 Durbin-Watson: 1.248
Prob(Omnibus): 0.456 Jarque-Bera (JB): 0.642
Skew: 0.489 Prob(JB): 0.725
Kurtosis: 3.079 Cond. No. 1.21e+08
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.21e+08. This might indicate that there are
strong multicollinearity or other numerical problems.
/Users/crovella/miniconda3/lib/python3.9/site-packages/scipy/stats/_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
What does this mean?
In statistics, multicollinearity (also collinearity) is a phenomenon in which two or more predictor variables in a multiple regression model are highly correlated, meaning that one can be linearly predicted from the others with a substantial degree of accuracy.
(Wikipedia)
Condition Number#
The condition number being referred to is the condition number of the design matrix.
That is the \(X\) in \(X\beta = y\).
Remember that to solve a least-squares problem \(X\beta = y\), we solve the normal equations
These equations always have at least one solution.
However, the “at least one” part is problematic!
If there are multiple solutions, they are in a sense all equivalent in that they yield the same value of \(\Vert X\beta - y\Vert\).
However, the actual values of \(\beta\) can vary tremendously and so it is not clear how best to interpret the case when \(X\) does not have full column rank.
When does this problem occur? Look at the normal equations:
It occurs when \(X^TX\) is not invertible.
In that case, we cannot simply solve the normal equations by computing \(\hat{\beta} = (X^TX)^{-1}X^Ty.\)
When is \((X^TX)\) not invertible?
This happens when the columns of \(X\) are linearly dependent –
That is, one column can be expressed as a linear combination of the other columns.
This is the simplest kind of multicollinearity.
Sources of Multicollinearity#
One obvious case is if \(X\) has more columns than rows. That is, if data have more features than there are observations.
This case is easy to recognize.
However, a more insidious case occurs when the columns of \(X\) happen to be linearly dependent because of the nature of the data itself.
This happens when one column is a linear function of the other columns.
In other words, one independent variable is a linear function of one or more of the others.
Unfortunately, in practice we will run into trouble even if variables are almost linearly dependent.
Near-dependence causes problems because measurements are not exact, and small errors are magnified when computing \((X^TX)^{-1}\).
So, more simply, when two or more columns are strongly correlated, we will have problems with linear regression.
Consider an experiment with the following predictors:
Condition number is a measure of whether \(X\) is nearly lacking full column rank.
In other words, whether some column is close to being a linear combination of the other columns.
In this case, the actual values of \(\beta\) can vary a lot due to noise in the measurements.
One way to say that \(X^TX\) is not invertible is to say that it has at least one zero eigenvalue.
Condition number relaxes this – it asks if \(X^TX\) has a very small eigenvalue (compared to its largest eigenvalue).
An easy way to assess this is using the SVD of \(X\).
(Thank you, “swiss army knife”!)
The eigenvalues of \(X^TX\) are the squares of the singular values of \(X\).
So the condition number of \(X\) is defined as:
where \(\sigma_{\mbox{max}}\) and \(\sigma_{\mbox{min}}\) are the largest and smallest singular values of \(X\).
A large condition number is evidence of a problem.
If the condition number is less than 100, there is no serious problem with multicollinearity.
Condition numbers between 100 and 1000 imply moderate to strong multicollinearity.
Condition numbers bigger than 1000 indicate severe multicollinearity.
Recall that the condition number of our data is around \(10^8\).
Let’s look at pairwise scatterplots of the Longley data:
Show code cell source
sns.pairplot(X[['GNPDEFL', 'GNP', 'UNEMP', 'ARMED', 'POP']]);
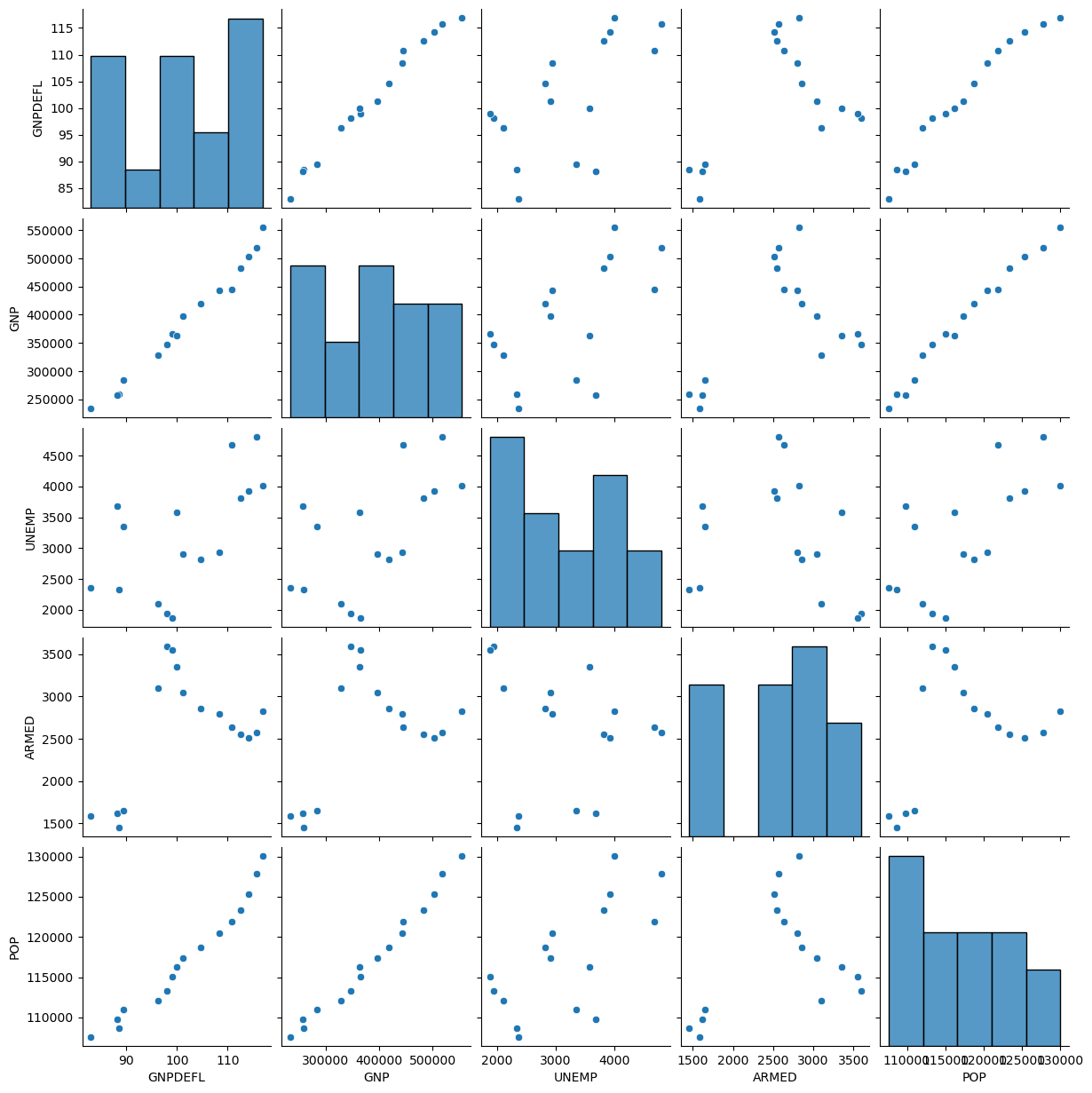
We can see very strong linear relationships between, eg, GNP Deflator, GNP, and Population.
Addressing Multicollinearity#
There are some things that can be done if it does happen.
We will review two strategies:
Ridge Regression
Model Selection via LASSO
Ridge Regression#
The first thing to note is that when columns of \(X\) are nearly dependent, the components of \(\hat{\beta}\) tend to be large in magnitude.
Consider a regression in which we are predicting the point \(\mathbf{y}\) as a linear function of two \(X\) columns, which we’ll denote \(\mathbf{u}\) and \(\mathbf{v}\).
Show code cell source
ax = ut.plotSetup(size=(6,3))
ut.centerAxes(ax)
u = np.array([1, 2])
v = np.array([4, 1])
alph = 1.6
beta = -1.25
sum_uv = (alph * u) + (beta * v)
ax.arrow(0, 0, u[0], u[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.arrow(0, 0, v[0], v[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.text(sum_uv[0]-.5, sum_uv[1]+0.25, r'$\mathbf{y}$',size=12)
ax.text(u[0]+0.25, u[1]-0.25, r'${\bf u}$', size=12)
ax.text(v[0]+0.25, v[1]+0.25, r'${\bf v}$',size=12)
ut.plotPoint(ax, sum_uv[0], sum_uv[1])
ax.plot(0, 0, '');
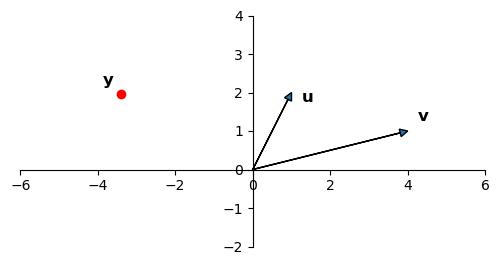
Via least-squares, we determine the coefficients \(\beta_1\) and \(\beta_2\):
Show code cell source
ax = ut.plotSetup(size=(6,3))
ut.centerAxes(ax)
u = np.array([1, 2])
v = np.array([4, 1])
alph = 1.6
beta = -1.25
sum_uv = (alph * u) + (beta * v)
ax.arrow(0, 0, u[0], u[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.arrow(0, 0, v[0], v[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.arrow(0, 0, alph * u[0], alph * u[1], head_width=0.2,
head_length=0.2, length_includes_head = True)
ax.arrow(alph * u[0], alph * u[1], sum_uv[0] - alph * u[0], sum_uv[1] - alph * u[1],
head_width=0.2,
head_length=0.2, length_includes_head = True, color = 'r')
ax.text(sum_uv[0]-2, sum_uv[1]+0.25, r'$\beta_1{\bf u}$+$\beta_2{\bf v}$',size=12)
ax.text(u[0]+0.25, u[1]-0.25, r'${\bf u}$', size=12)
ax.text(alph * u[0]+0.25, alph * u[1]-0.25, r'$\beta_1{\bf u}$', size=12)
ax.text(-2, 2.75, r'$\beta_2{\bf v}$', size=12)
ax.text(v[0]+0.25, v[1]+0.25, r'${\bf v}$',size=12)
ut.plotPoint(ax, sum_uv[0], sum_uv[1])
ax.plot(0, 0, '');
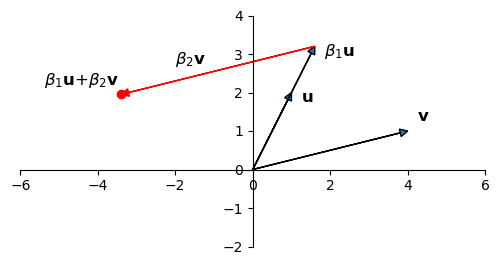
Now consider if the columns of \(X\) are nearly dependent: ie, they are almost in the same direction:
Show code cell source
ax = ut.plotSetup(size=(6,3))
ut.centerAxes(ax)
u = np.array([2, 1])
v = np.array([4, 1])
ax.arrow(0, 0, u[0], u[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.arrow(0, 0, v[0], v[1], head_width=0.2, head_length=0.2, length_includes_head = True)
ax.text(sum_uv[0]-.5, sum_uv[1]+0.25, r'$\mathbf{y}$',size=12)
ax.text(u[0]+0.25, u[1]-0.25, r'${\bf u}$', size=12)
ax.text(v[0]+0.25, v[1]+0.25, r'${\bf v}$',size=12)
ut.plotPoint(ax, sum_uv[0], sum_uv[1])
ax.plot(0, 0, '');
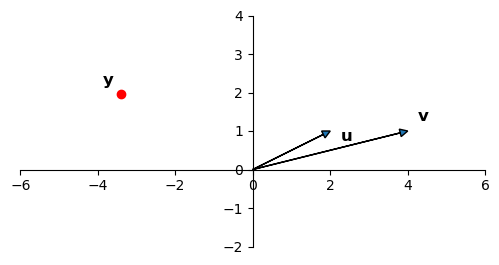
If you imagine the values of \(\beta_1\) and \(\beta_2\) necessary to create \(\mathbf{y} = \beta_1{\bf u}\)+\(\beta_2{\bf v}\), you can see that \(\beta_1\) and \(\beta_2\) will be very large in magnitude.
This geometric argument illustrates why the regression coefficients will be very large under multicollinearity.
Put another way, the value of \(\Vert\beta\Vert\) will be very large.
Ridge Regression#
Ridge regression adjusts least squares regression by shrinking the estimated coefficients towards zero.
The purpose is to fix the magnitude inflation of \(\Vert\beta\Vert\).
To do this, Ridge regression assumes that the model has no intercept term –
both the response and the predictors have been centered so that \(\beta_0 = 0\).
Ridge regression then consists of adding a penalty term to the regression:
For any given \(\lambda\) this has a closed-form solution in which \(\hat{\beta}\) is a linear function of \(X\) (just as in ordinary least squares).
The solution to the Ridge regression problem always exists and is unique, even when the data contains multicollinearity.
Here, \(\lambda \geq 0\) is a tradeoff parameter (amount of shrinkage).
It controls the strength of the penalty term:
When \(\lambda = 0\), we get the least squares estimator: \(\hat{\beta} = (X^TX)^{−1}X^T\mathbf{y}\)
When \(\lambda = \infty\), we get \(\hat{\beta} = 0.\)
Increasing the value of \(\lambda\) forces the norm of \(\hat{\beta}\) to decrease, yielding smaller coefficient estimates (in magnitude).
For a finite, positive value of \(\lambda\), we are balancing two tasks: fitting a linear model and shrinking the coefficients.
So once again, we have a hyperparameter that controls model complexity:
hence, we typically set \(\lambda\) by holding out data, ie, cross-validation.
Note that the penalty term \(\Vert\beta\Vert^2\) would be unfair to the different predictors, if they are not on the same scale.
Therefore, if we know that the variables are not measured in the same units, we typically first perform unit normal scaling on the columns of \(X\) and on \(\mathbf{y}\) (to standardize the predictors), and then perform ridge regression.
Note that by scaling \(\mathbf{y}\) to zero-mean, we do not need (or include) an intercept in the model.
The general strategy of including extra criteria to improve the behavior of a model is called “regularization.”
Accordingly, Ridge regression is also known as Tikhanov regularization.
Here is the performance of Ridge regression on the Longley data.
We are training on half of the data, and using the other half for testing.
Show code cell source
from sklearn.metrics import r2_score
nreps = 1000
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_std = scaler.fit_transform(X[['GNPDEFL', 'GNP', 'UNEMP', 'ARMED', 'POP']])
y_std = scaler.fit_transform(y.values.reshape(-1, 1))
np.random.seed(1)
vals = []
for alpha in np.r_[np.array([0]), 10**np.linspace(-8.5, -0.5, 20)]:
res = []
for rep in range(nreps):
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X_std, y_std,
test_size=0.5)
model = sm.OLS(y_train, X_train)
results = model.fit_regularized(alpha = alpha, L1_wt = 0)
y_oos_predict = results.predict(X_test)
r2_test = r2_score(y_test, y_oos_predict)
res.append(r2_test)
vals.append([alpha, np.mean(res), np.std(res)/np.sqrt(nreps)])
results = np.array(vals)
Show code cell source
ax = plt.figure(figsize = (6, 4)).add_subplot()
ax.errorbar(np.log10(results[1:][:, 0]), results[1:][:, 1],
results[1:][:, 2],
label = 'Ridge Regression')
ax.hlines(results[0,1], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dashed',
label = 'Without Regularization')
ax.hlines(results[0,1]+results[0,2], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dotted')
ax.hlines(results[0,1]-results[0,2], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dotted')
ax.tick_params(labelsize=12)
ax.set_ylabel('$R^2$', fontsize = 14)
plt.legend(loc = 'best')
ax.set_xlabel('$\log_{10}(\lambda)$', fontsize = 14)
ax.set_title('Ridge Regression Accuracy on Longley Data', fontsize = 16);
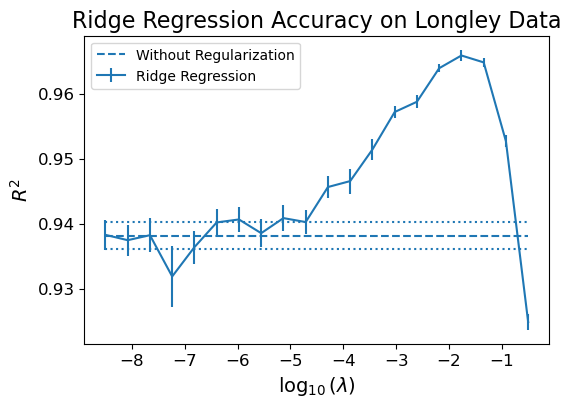
To sum up the idea behind Ridge regression:
There may be many \(\beta\) values that are (approximately) consistent with the equations.
However over-fit \(\beta\) values tend to have large magnitudes
We apply shrinkage to avoid those solutions
We do so by tuning \(\lambda\) via cross-validation
Model Selection#
Of course, one might attack the problem of multicollinearity as follows:
Multicollinearity occurs because there are near-dependences among variables (features)
The extra variables do not contribute anything “meaningful” to the quality of the model
Hence, why not simply remove variables from the model that are causing dependences?
If we remove variables from our regression, we are creating a new model.
Hence this strategy is called “model selection.”
One of the advantages of model selection is interpretability: by eliminating variables, we get a clearer picture of the relationship between truly useful features and dependent variables.
However, there is a big challenge inherent in model selection:
in general, the possibilities to consider are exponential in the number of features.
That is, if we have \(n\) features to consider, then there are \(2^n-1\) possible models that incorporate one or more of those features.
This space is usually too big to search directly.
Can we use Ridge regression for this problem?
Ridge regression does not set any coefficients exactly to zero unless \(\lambda = \infty\) (in which case they’re all zero).
Hence, Ridge regression cannot perform variable selection, and even though it performs well in terms of prediction accuracy, it does not offer a clear interpretation
The LASSO#
LASSO differs from Ridge regression only in terms of the norm used by the penalty term.
Ridge regression:
LASSO:
However, this small change in the norm makes a big difference in practice.
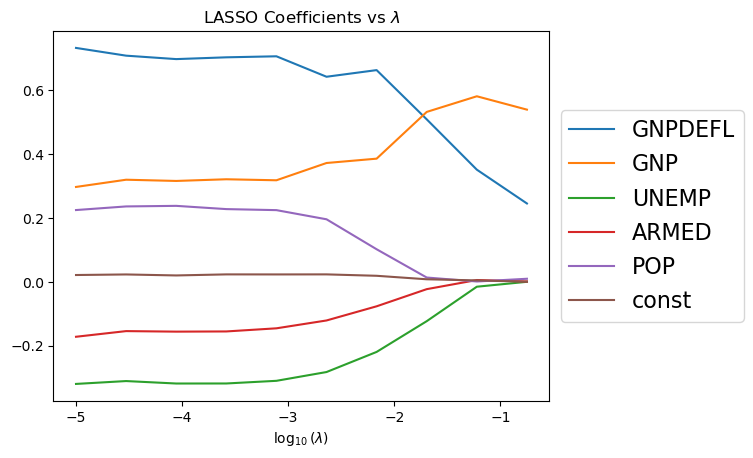
The nature of the \(\ell_1\) penalty will cause some coefficients to be shrunken to zero exactly!
This means that LASSO can perform model selection: it can tell us which variables to keep and which to set aside.
As \(\lambda\) increases, more coefficients are set to zero (fewer variables are selected).
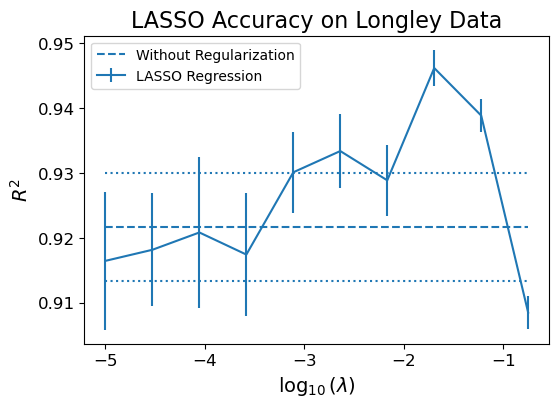
In terms of prediction error, LASSO performs comparably to Ridge regression,
… but it has a big advantage with respect to interpretation.
Show code cell source
from sklearn.metrics import r2_score
nreps = 200
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_std = scaler.fit_transform(X[['GNPDEFL', 'GNP', 'UNEMP', 'ARMED', 'POP']])
X_std = np.column_stack([X_std, np.ones(X_std.shape[0])])
y_std = scaler.fit_transform(y.values.reshape(-1, 1))
np.random.seed(1)
vals = []
mean_params = []
for alpha in np.r_[np.array([0]), 10**np.linspace(-5, -0.75, 10)]:
res = []
params = []
for rep in range(nreps):
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X_std, y_std,
test_size=0.5)
model = sm.OLS(y_train, X_train)
results = model.fit_regularized(alpha = alpha, L1_wt = 1.0)
y_oos_predict = results.predict(X_test)
r2_test = r2_score(y_test, y_oos_predict)
res.append(r2_test)
params.append(results.params)
vals.append([alpha, np.mean(res), np.std(res)/np.sqrt(nreps)])
mean_params.append(np.r_[alpha, np.mean(params, axis = 0)])
results = np.array(vals)
mean_params = np.array(mean_params)
Show code cell source
ax = plt.figure(figsize = (6, 4)).add_subplot()
ax.errorbar(np.log10(results[1:][:, 0]), results[1:][:, 1],
results[1:][:, 2],
label = 'LASSO Regression')
ax.hlines(results[0,1], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dashed',
label = 'Without Regularization')
ax.hlines(results[0,1]+results[0,2], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dotted')
ax.hlines(results[0,1]-results[0,2], np.log10(results[1, 0]),
np.log10(results[-1, 0]), linestyles = 'dotted')
ax.tick_params(labelsize=12)
ax.set_ylabel('$R^2$', fontsize = 14)
#ax.set_xlim([-4, -1])
plt.legend(loc = 'best')
ax.set_xlabel('$\log_{10}(\lambda)$', fontsize = 14)
ax.set_title('LASSO Accuracy on Longley Data', fontsize = 16);
Show code cell source
df = pd.DataFrame(mean_params, columns = ['$\log_{10}(\lambda)$', 'GNPDEFL', 'GNP', 'UNEMP', 'ARMED', 'POP', 'const'])
param_df = df[['GNPDEFL', 'GNP', 'UNEMP', 'ARMED', 'POP', 'const']].iloc[1:].copy()
param_df.index = np.log10(df.iloc[1:]['$\log_{10}(\lambda)$'])
Show code cell source
param_df.plot()
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), prop={'size': 16})
plt.title('LASSO Coefficients vs $\lambda$');
Flexible Modeling#
To look at model selection in practice, we will consider another famous dataset.
The Guerry dataset is a collection of historical data used in support of Andre-Michel Guerry’s 1833 “Essay on the Moral Statistics of France.”
Andre-Michel Guerry’s (1833) Essai sur la Statistique Morale de la France was one of the foundation studies of modern social science. Guerry assembled data on crimes, suicides, literacy and other “moral statistics,” and used tables and maps to analyze a variety of social issues in perhaps the first comprehensive study relating such variables.
Wikipedia
Guerry’s results were startling for two reasons. First he showed that rates of crime and suicide remained remarkably stable over time, when broken down by age, sex, region of France and even season of the year; yet these numbers varied systematically across departements of France. This regularity of social numbers created the possibility to conceive, for the first time, that human actions in the social world were governed by social laws, just as inanimate objects were governed by laws of the physical world.
Source: “A.-M. Guerry’s Moral Statistics of France: Challenges for Multivariable Spatial Analysis”, Michael Friendly. Statistical Science 2007, Vol. 22, No. 3, 368–399.
Show code cell content
X['TOTEMP'] = y
Show code cell content
mod = smf.ols(formula='TOTEMP ~ GNPDEFL + GNP + UNEMP + ARMED + POP', data=X)
res = mod.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 0.987
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 156.4
Date: Wed, 12 Jul 2023 Prob (F-statistic): 3.70e-09
Time: 12:44:25 Log-Likelihood: -117.83
No. Observations: 16 AIC: 247.7
Df Residuals: 10 BIC: 252.3
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 9.246e+04 3.52e+04 2.629 0.025 1.41e+04 1.71e+05
GNPDEFL -48.4628 132.248 -0.366 0.722 -343.129 246.204
GNP 0.0720 0.032 2.269 0.047 0.001 0.143
UNEMP -0.4039 0.439 -0.921 0.379 -1.381 0.573
ARMED -0.5605 0.284 -1.975 0.077 -1.193 0.072
POP -0.4035 0.330 -1.222 0.250 -1.139 0.332
==============================================================================
Omnibus: 1.572 Durbin-Watson: 1.248
Prob(Omnibus): 0.456 Jarque-Bera (JB): 0.642
Skew: 0.489 Prob(JB): 0.725
Kurtosis: 3.079 Cond. No. 1.21e+08
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.21e+08. This might indicate that there are
strong multicollinearity or other numerical problems.
/Users/crovella/miniconda3/lib/python3.9/site-packages/scipy/stats/_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Show code cell content
mod = smf.ols(formula='TOTEMP ~ GNPDEFL + GNP + UNEMP - 1', data=X)
res = mod.fit()
print(res.summary())
OLS Regression Results
=======================================================================================
Dep. Variable: TOTEMP R-squared (uncentered): 1.000
Model: OLS Adj. R-squared (uncentered): 1.000
Method: Least Squares F-statistic: 1.127e+04
Date: Wed, 12 Jul 2023 Prob (F-statistic): 1.92e-22
Time: 12:44:25 Log-Likelihood: -137.20
No. Observations: 16 AIC: 280.4
Df Residuals: 13 BIC: 282.7
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
GNPDEFL 871.0961 25.984 33.525 0.000 814.961 927.231
GNP -0.0532 0.007 -8.139 0.000 -0.067 -0.039
UNEMP -0.8333 0.496 -1.679 0.117 -1.905 0.239
==============================================================================
Omnibus: 0.046 Durbin-Watson: 1.422
Prob(Omnibus): 0.977 Jarque-Bera (JB): 0.274
Skew: -0.010 Prob(JB): 0.872
Kurtosis: 2.359 Cond. No. 2.92e+04
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[3] The condition number is large, 2.92e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
/Users/crovella/miniconda3/lib/python3.9/site-packages/scipy/stats/_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
# Lottery is per-capital wager on Royal Lottery
df = sm.datasets.get_rdataset("Guerry", "HistData").data
df = df[['Lottery', 'Literacy', 'Wealth', 'Region']].dropna()
df.head()
| Lottery | Literacy | Wealth | Region | |
|---|---|---|---|---|
| 0 | 41 | 37 | 73 | E |
| 1 | 38 | 51 | 22 | N |
| 2 | 66 | 13 | 61 | C |
| 3 | 80 | 46 | 76 | E |
| 4 | 79 | 69 | 83 | E |
We can use another version of the module that can directly type formulas and expressions in the functions of the models.
We can specify the name of the columns to be used to predict another column, remove columns, etc.
mod = smf.ols(formula='Lottery ~ Literacy + Wealth + Region', data=df)
res = mod.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Wed, 12 Jul 2023 Prob (F-statistic): 1.07e-05
Time: 12:44:25 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Categorical variables
Patsy is the name of the interpreter that parses the formulas.
Looking at the summary printed above, notice that patsy determined that elements of Region were text strings, so it treated Region as a categorical variable.
Patsy‘s default is also to include an intercept, so we automatically dropped one of the Region categories.
Removing variables
The “-” sign can be used to remove columns/variables. For instance, we can remove the intercept from a model by:
res = smf.ols(formula='Lottery ~ Literacy + Wealth + C(Region) -1 ', data=df).fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Wed, 12 Jul 2023 Prob (F-statistic): 1.07e-05
Time: 12:44:25 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
C(Region)[C] 38.6517 9.456 4.087 0.000 19.826 57.478
C(Region)[E] 23.2239 14.931 1.555 0.124 -6.501 52.949
C(Region)[N] 28.6347 13.127 2.181 0.032 2.501 54.769
C(Region)[S] 34.1034 10.370 3.289 0.002 13.459 54.748
C(Region)[W] 28.5604 10.018 2.851 0.006 8.616 48.505
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 653.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Functions
We can also apply vectorized functions to the variables in our model:
res = smf.ols(formula='Lottery ~ np.log(Literacy)', data=df).fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.161
Model: OLS Adj. R-squared: 0.151
Method: Least Squares F-statistic: 15.89
Date: Wed, 12 Jul 2023 Prob (F-statistic): 0.000144
Time: 12:44:25 Log-Likelihood: -385.38
No. Observations: 85 AIC: 774.8
Df Residuals: 83 BIC: 779.7
Df Model: 1
Covariance Type: nonrobust
====================================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------------
Intercept 115.6091 18.374 6.292 0.000 79.064 152.155
np.log(Literacy) -20.3940 5.116 -3.986 0.000 -30.570 -10.218
==============================================================================
Omnibus: 8.907 Durbin-Watson: 2.019
Prob(Omnibus): 0.012 Jarque-Bera (JB): 3.299
Skew: 0.108 Prob(JB): 0.192
Kurtosis: 2.059 Cond. No. 28.7
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.