Parameter Estimation
Contents
Parameter Estimation#
Estimators#
A common situation in statistics is the following.
We are given some data and we want to treat is as an i.i.d. sample from some distribution. The distribution has certain parameters, such as the mean \(\mu\) or the variance \(\sigma^2\). These are assumed to be fixed but unknown.
For example, let’s say we have the data below. We want to treat the data as drawn from a Normal distribution \(\mathcal{N}(\mu, \sigma^2)\).
What values should we choose for \(\mu\) and \(\sigma\)?

We will use \(\theta\) (which can be a scalar or a vector) to represent the parameter(s). For example, we could have \(\theta = (\mu, \sigma).\)
Let’s say our data is \(\{x^{(1)}, \dots, x^{(m)}\}\). A point estimator or statistic is any function of the data:
We’ll use the hat notation (\(\hat{\theta}\)) to indicate that we want our point estimator to be an estimate of \(\theta\).
In the frequentist perspective on statistics, \(\theta\) is fixed but unknown, while \(\hat{\theta}\) is a function of the data (and therefore is a random variable).
This is a very important perspective to keep in mind; it is really the defining feature of the frequentist approach to statistics!
Example. Consider a set of samples \(\{x^{(1)}, \dots, x^{(m)}\}\) that are independently and identically distributed according to a Bernoulli distribution with mean \(\theta\):
A common estimator for \(\theta\) is the mean of the samples:
Bias and Variance#
How can we tell if an estimator is a good one?
We use two criteria: bias and variance.
Bias. The bias of an estimator is defined as:
where the expectation is over the data (seen as samples of a random variable) and \(\theta\) is the true underlying value of \(\theta\) used to define the data-generating distribution.
An estimator is said to be unbiased if \( \operatorname{bias}(\hat{\theta}_m) = 0\), or in other words \(E[\hat{\theta}_m] = \theta\).
Continuing our example for the mean of the Bernoulli:
So we have proven that this estimator of \(\theta\) is unbiased.
Variance. The variance of an estimator is simply the variance
where the random variable is the data set.
Remember that the data set is random; it is assumed to be an i.i.d. sample of some distribution.
Again, using our example of the Bernoulli distribution:
we know that the estimator \(\hat{\theta}_m = \frac{1}{m}\sum_{i=1}^m x^{(i)}\) is simply the mean of \(m\) samples of the distribution.
Recalling that variances of i.i.d. RVs sum:
when we divide the sum by \(m\) to get the mean, this divides the variance by \(m^2\).)
So we see that that the variance of the mean is:
Hence we conclude that
This has a desirable property: as the number of samples \(m\) increases, the variance of the estimate decreases.
Mean Squared Error#
Consider two estimators, \(g\) and \(h\), each of which are used as estimates of a certain parameter \(\theta\).
Let us say that these estimators show the following distributions:
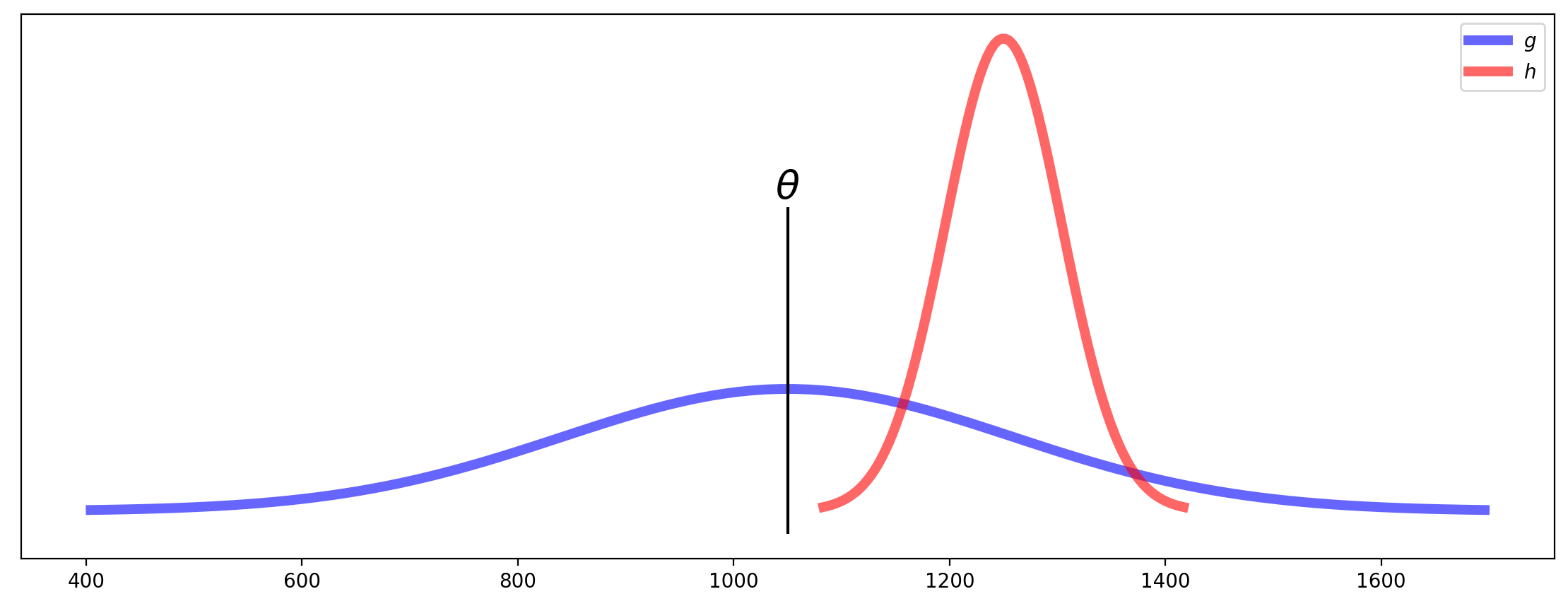
The figure shows that estimator \(h\) has low variance, but is biased. Meanwhile, estimator \(g\) is unbiased, but has high variance.
Which is better?
The answer of course depends, but there is a single criterion we can use to try to balance these two kinds of errors.
It is Mean Squared Error.
This measures the “average distance squared” between the estimator and the true value.
It is a good single number for evaluating an estimator, because it turns out that:
For example, the two estimators \(g\) and \(h\) in the plot above have approximately the same MSE.
Model Fitting#
The notion of parameter estimation leads to a more general concept called model fitting.
Imagine that you know that data is drawn from a particular kind of distribution, but you don’t know the value(s) of the distribution’s parameter(s).
We have actually been doing this quite a bit already, but now we want to treat the notion more directly.
We formalize the problem as follows. We say that data is drawn from a distribution
The way to read this is: the probability of \(x\) under a distribution having parameter(s) \(\theta\).
We call \(p(x; \theta)\) a family of distributions because there is a different distribution for each value of \(\theta\).
Model fitting is finding the parameters \(\theta\) of the distribution given that we know some data \(x\).
Notice that in this context, it is the parameters \(\theta\) that are varying (not the data \(x\)).
When we think of \(p(x; \theta)\) as a function of \(\theta\) (instead of \(x\), say) we call it a likelihood.
This change in terminology is just to emphasize that we are thinking about varying \(\theta\) when we look at the probability \(p(x; \theta)\).
For example, consider the dataset below:

Can you imagine that this dataset might be drawn from a Normal distribution?
In that case,
Then model fitting would consist of finding the \(\mu\) and \(\sigma\) that best matches the given data \(x\) shown above.
When we consider how the probability of the data shown varies as we vary \(\mu\) and \(\sigma\), we are dealing with the likelihood of the data.
Calculating Likelihood#
Let’s think about how to calculate likelihood. Consider a set of \(m\) data items
drawn independently from the true but unknown data-generating distribution \(p_{\text{data}}(x)\).
Let’s let \(p_{\text{model}}(x; \theta)\) be a family of probability distributions over the same space.
Then, for any value of \(\theta\), \(p_{\text{model}}(x; \theta)\) maps a particular data item \(x\) to a real number that we can use as an estimate of the true probability \(p_{\text{data}}(x)\).
What is the probability of the entire dataset \(X\) under the model?
We assume that the \(x^{(i)}\) are independent; so the probabilities multiply.
So the joint probability is
Now, each individual \(p_{\text{model}}(x^{(i)}; \theta)\) is a value between 0 and 1.
And there are \(m\) of these numbers being multiplied. So for any reasonable-sized dataset, the joint probability is going to be very small.
For example, if a typical probability is \(1/10\), and there are 500 data items, then the joint probability will be a number on the order of \(10^{-500}\).
So the probability of a given dataset as a number will usually be too small to even represent in a computer using standard floating point!
Log-Likelihood#
Luckily, there is an excellent way to handle this problem.
Instead of using likelihood, we will use the log of likelihood.
This is fine, because most of the time we are only interested in comparing different likelihoods. The log function does not change the results of comparisons (it is a monotonic function).
So we will work with the log-likelihood:
Which becomes:
This way we are no longer multiplying many small numbers, and we work with values that are easy to represent.
Note though that the log of a number less than one is negative, so log-likelihoods are always negative values.
Example.
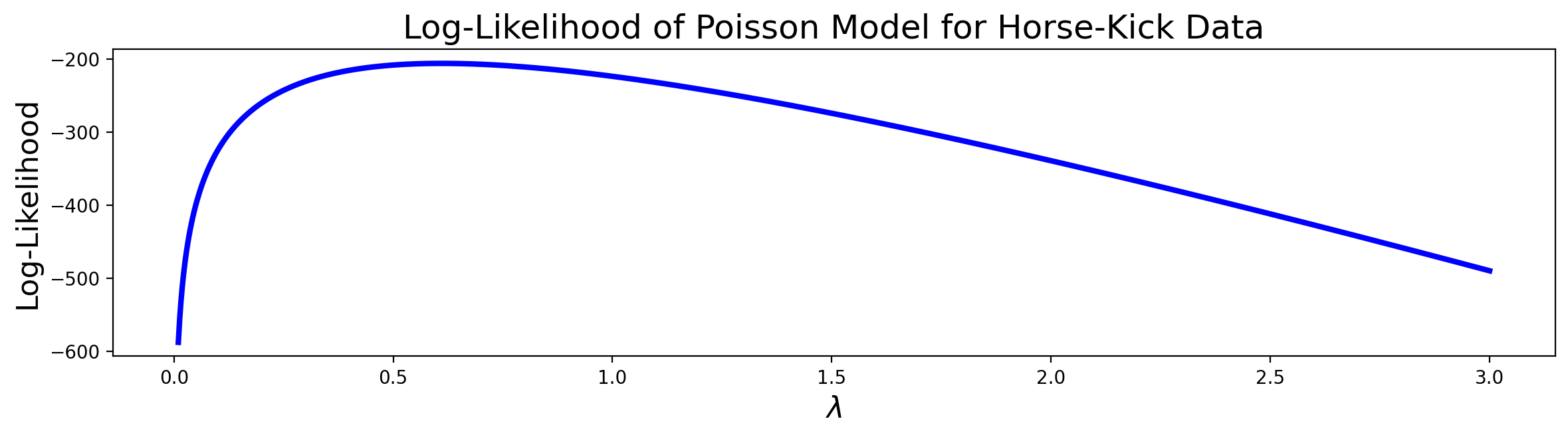
As an example, let’s return to Bortkeiwicz’s horse-kick data, and see how the log-likelihood changes for different values of the Poisson parameter \(\lambda\).
Recall that Bortkeiwicz had collected deaths by horse-kick in the Prussian army over a span of 200 years, and was curious whether they occurred at a constant, fixed rate.
To do this he fitted the data to a Poisson distribution. To do that, he needed to estimate the parameter \(\lambda\).
Let’s see how the log-likelihood of the data varies as a function of \(\lambda\).
| Deaths Per Year | Observed Instances |
|---|---|
| 0 | 109 |
| 1 | 65 |
| 2 | 22 |
| 3 | 3 |
| 4 | 1 |
| 5 | 0 |
| 6 | 0 |
As a reminder, \(\lambda\) is rate of deaths per year, and \(T = 1\) reflects that we are interested in one-year intervals.
The Poisson distribution predicts:
Since \(T = 1\) we can drop it, and so the likelihood of a particular number of deaths \(x^{(i)}\) in year \(i\) is:
So the log-likelihood is:
Using this we can calculate the log-likelihood of the data, ie:
Which looks like this as we vary \(\lambda\):
The Maximum Likelihood Principle#
We have seen some examples of estimators for parameters.
But where do estimators come from?
Rather than making guesses about what might be a good estimator, we’d like a principle that we can use to derive good estimators for different models.
The most common principle is the maximum likelihood principle.
Looking back at the deaths-by-horse-kick data, we can see that there is clearly a maximum in the plot of the likelihood function, somewhere between 0.5 and 1.
If we use the value of \(\lambda\) at the maximum, we are choosing to set \(\lambda\) to maximize the likelihood of the data under the model.
Formally, we say that the maximum likelihood estimator for \(\theta\) is:
which for a dataset of \(m\) items is:
And remember that (because the log function is monotonic) this is the same thing as maximizing the log-likelihood:
The maximum likelihood estimator has a number of properties that make it the preferred way to estimate parameters whenever possible.
In particular, under appropriate conditions, the MLE is consistent, meaning that as the number of data items grows large, the estimate converges to the true value of the parameter.
It can also be shown that for large \(m\), no consistent estimator has a lower MSE than the maximum likelihood estimator.
Example.
Let’s see how to find the MLE for the Poisson distribution, and apply it to the horse-kick data.
We will work with log-likelihood of the data:
We want to find the maximum of this expression as a function of \(\lambda\).
The derivative with respect to \(\lambda\) is:
Setting the derivative to zero means that \(\hat{\lambda}\) is our MLE. So we get
Thus we find that the MLE estimate of \(\lambda\) (the number of deaths per year) is just the mean of the data, ie, the average number of deaths per year!
From the data above we can compute that \(\hat{\lambda}\) = 0.61.
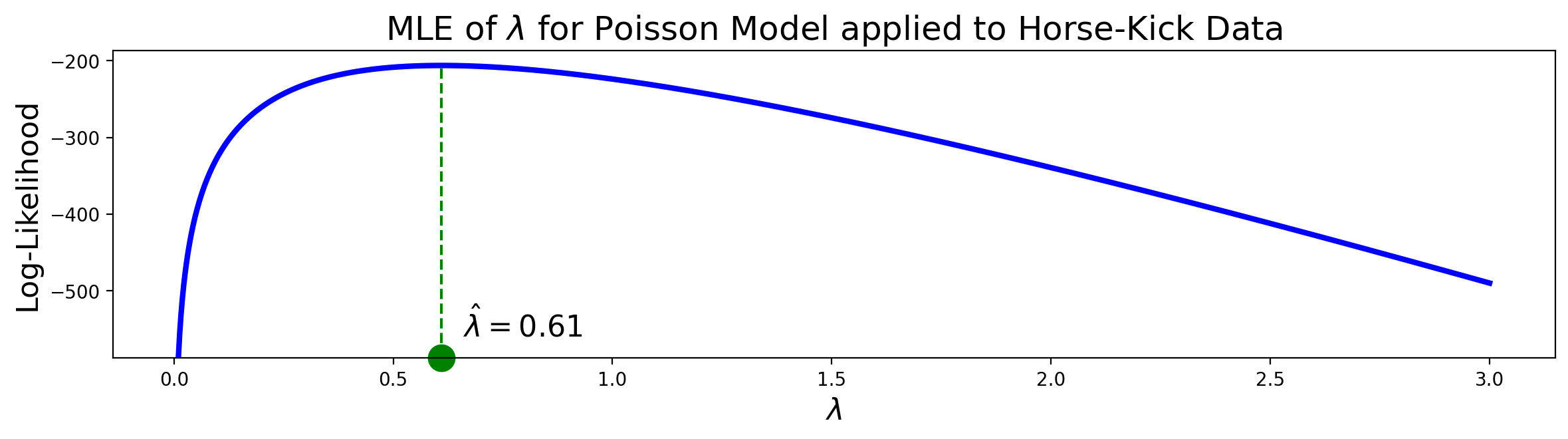
Using this estimate for \(\lambda\), we can ask what the expected number of deaths per year would be, if deaths by horse-kick really followed the assumptions of the Poisson distribution (ie, happening at a fixed, constant rate):
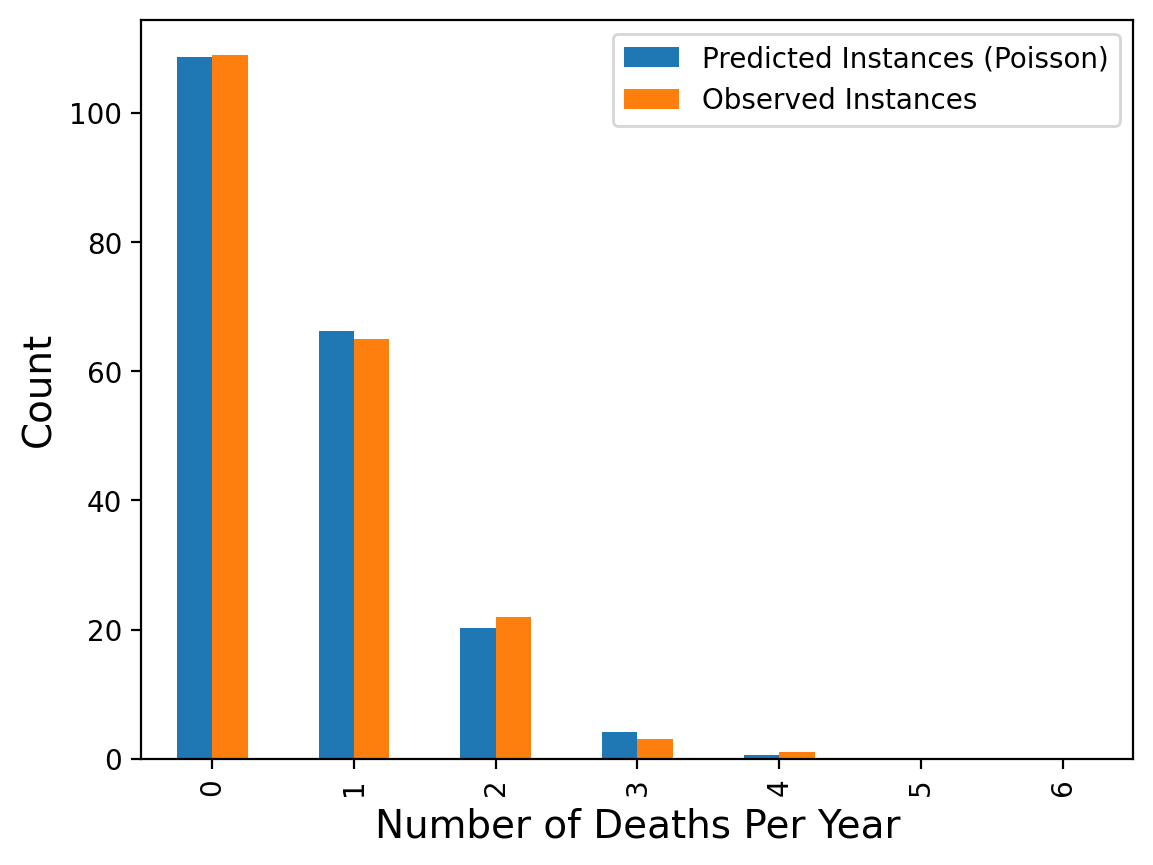
Which shows that the Poisson model is indeed a very good fit to the data!
From this, Bortkeiwicz concluded that there was nothing particularly unusual about the years when there were many deaths by horse-kick. They could be just what is expected if deaths occurred at a constant rate.