Recommender Systems
Contents
Recommender Systems#
Today, we look at a topic that has become enormously important in society: recommender systems.
We will
Define recommender systems
Review the challenges they pose
Discuss two classic methods:
Collaborative Filtering
Matrix Factorization
What are Recommender Systems?#
The concept of recommender systems emerged in the late 1990s / early 2000s as social life moved online:
online purchasing and commerce
online discussions and ratings
social information sharing
In these systems content was exploding and users were having a hard time finding things they were interested in.
Users wanted recommendations.
Over time, the problem has only gotten worse:
An enormous need has emerged for systems to help sort through products, services, and content items.
This often goes by the term personalization.
Some examples:
Movie recommendation (Netflix, YouTube)
Related product recommendation (Amazon)
Web page ranking (Google)
Social content filtering (Facebook, Twitter)
Services (Airbnb, Uber, TripAdvisor)
News content recommendation (Apple News)
Priority inbox & spam filtering (Google)
Online dating (OK Cupid)
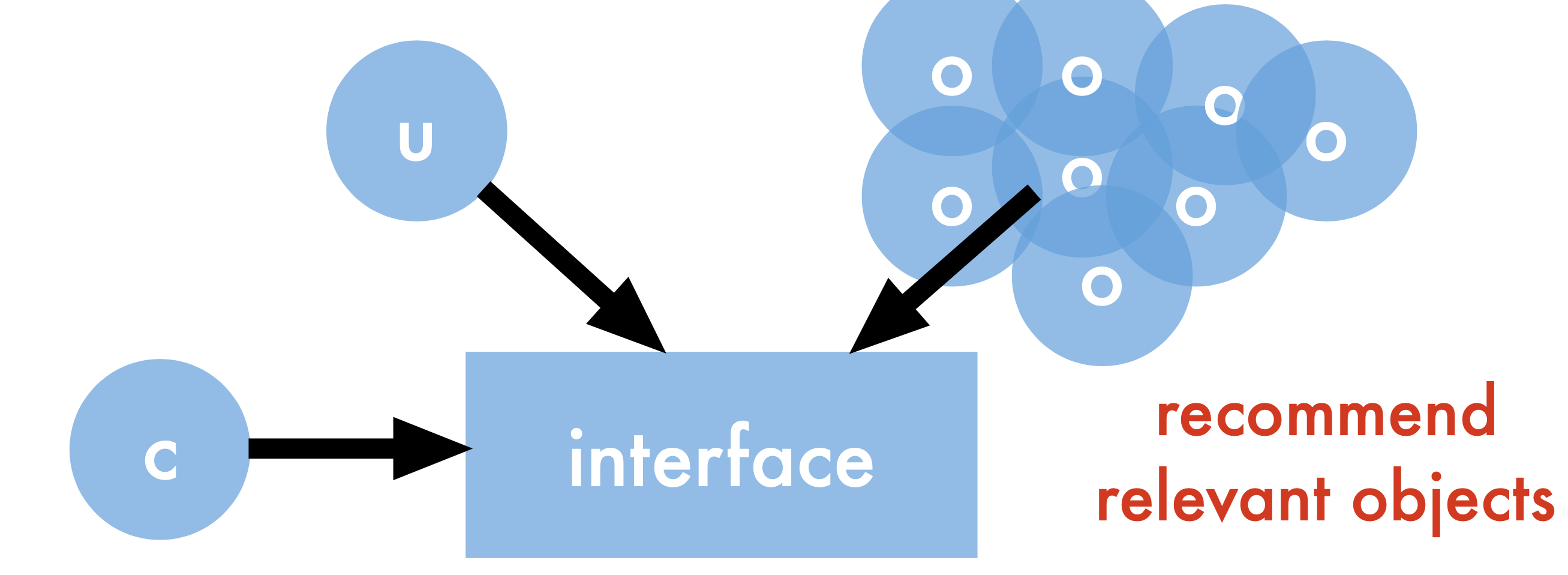
A more formal view:
User - requests content
Objects - that can be displayed
Context - device, location, time
Interface - browser, mobile
Inferring Preferences#
Unfortunately, users generally have a hard time explaining what types of content they prefer. Some early systems worked by interviewing users to ask what they liked. Those systems did not work very well.
Instead, modern systems work by capturing user’s opinions about specific items.
This can be done actively:
When a user is asked to rate a movie, product, or experience,
Or it can be done passively:
By noting which items a user chooses to purchase (for example).
Challenges#
The biggest issue is scalability: typical data for this problem is huge.
Millions of objects
100s of millions of users
Changing user base
Changing inventory (movies, stories, goods)
Available features
Imbalanced dataset
User activity / item reviews are power law distributed
# This is a 1.7 GB file, delete it after use
import os.path
if not os.path.exists('train.csv'):
os.system('kaggle competitions download -c cs-506-midterm-a1-b1')
os.system('unzip cs-506-midterm-a1-b1.zip')
cs-506-midterm-a1-b1.zip: Skipping, found more recently modified local copy (use --force to force download)
Archive: cs-506-midterm-a1-b1.zip
inflating: test.csv
inflating: train.csv
replace sample.csv? [y]es, [n]o, [A]ll, [N]one, [r]ename: NULL
(EOF or read error, treating as "[N]one" ...)
df = pd.read_csv('train.csv')
n_users = df["UserId"].unique().shape[0]
n_movies = df["ProductId"].unique().shape[0]
n_reviews = len(df)
print(f'There are {n_reviews} reviews, {n_movies} movies and {n_users} users.')
print(f'There are {n_users * n_movies} potential reviews, meaning sparsity of {(n_reviews/(n_users * n_movies)):0.4%}')
There are 1697533 reviews, 50052 movies and 123960 users.
There are 6204445920 potential reviews, meaning sparsity of 0.0274%
Reviews are Sparse.
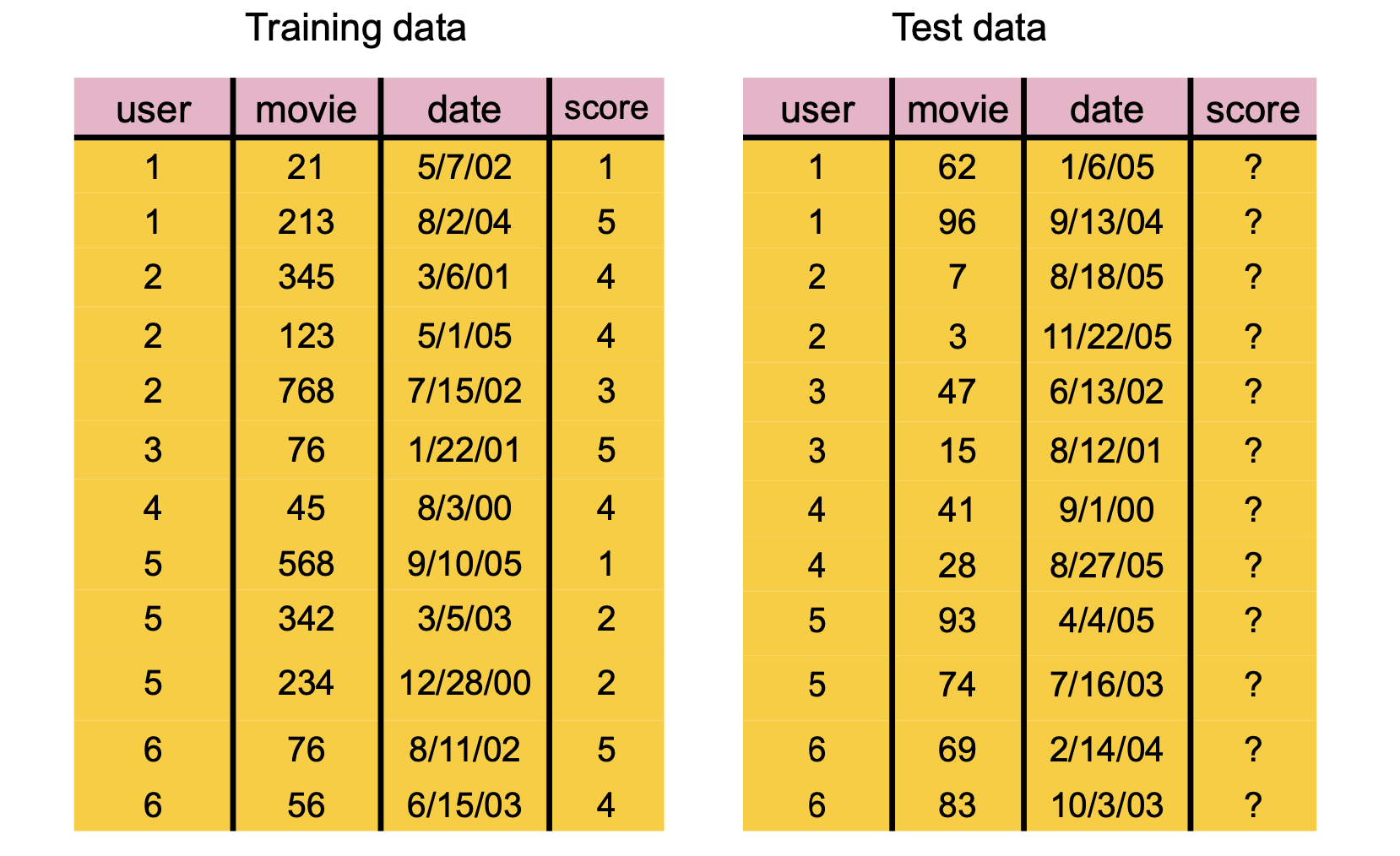
Example: A commonly used dataset for testing consists of Amazon movie reviews:
1,697,533 reviews
123,960 users
50,052 movies
Notice that there are 6,204,445,920 potential reviews, but we only have 1,697,533 actual reviews.
Only 0.02% of the reviews are available – 99.98% of the reviews are missing.
print(f'There are on average {n_reviews/n_movies:0.1f} reviews per movie' +
f' and {n_reviews/n_users:0.1f} reviews per user')
There are on average 33.9 reviews per movie and 13.7 reviews per user
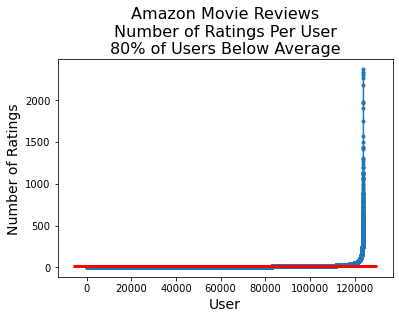
Sparseness is skewed.
Although on average a movie receives 34 reviews, almost all movies have even fewer reviews.
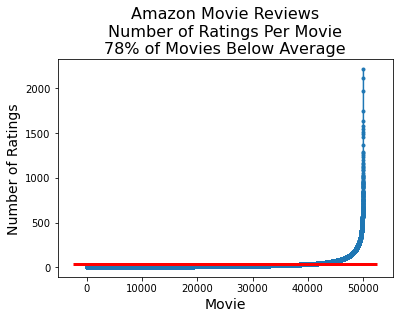
Likewise, although the average user writes 14 reviews, almost all users write even fewer reviews.
reviews_per_user = df.groupby('UserId').count()['Id'].values
frac_below_mean = np.sum(reviews_per_user < (n_reviews/n_users))/len(reviews_per_user)
plt.plot(sorted(reviews_per_user), '.-')
xmin, xmax, ymin, ymax = plt.axis()
plt.hlines(n_reviews/n_users, xmin, xmax, 'r', lw = 3)
plt.ylabel('Number of Ratings', fontsize = 14)
plt.xlabel('User', fontsize = 14)
plt.title(f'Amazon Movie Reviews\nNumber of Ratings Per User\n' +
f'{frac_below_mean:0.0%} of Users Below Average', fontsize = 16);
A typical objective function is root mean square error (RMSE)
where \( r_{ui} \) is the rating that user \(u\) gives to item \(i\), and \(S\) is the set of all ratings.
OK, now we know the problem and the data available. How can we address the problem?
The earliest method developed is called collaborative filtering.
Collaborative Filtering#
The central idea of collaborative filtering is that the set of known recommendations can be considered to be a bipartite graph.

The nodes of the bipartite graph are users and items.
Each edge corresponds to a known rating \(r_{ui}.\)
Then recommendations are formed by traversing or processing the bipartite graph.
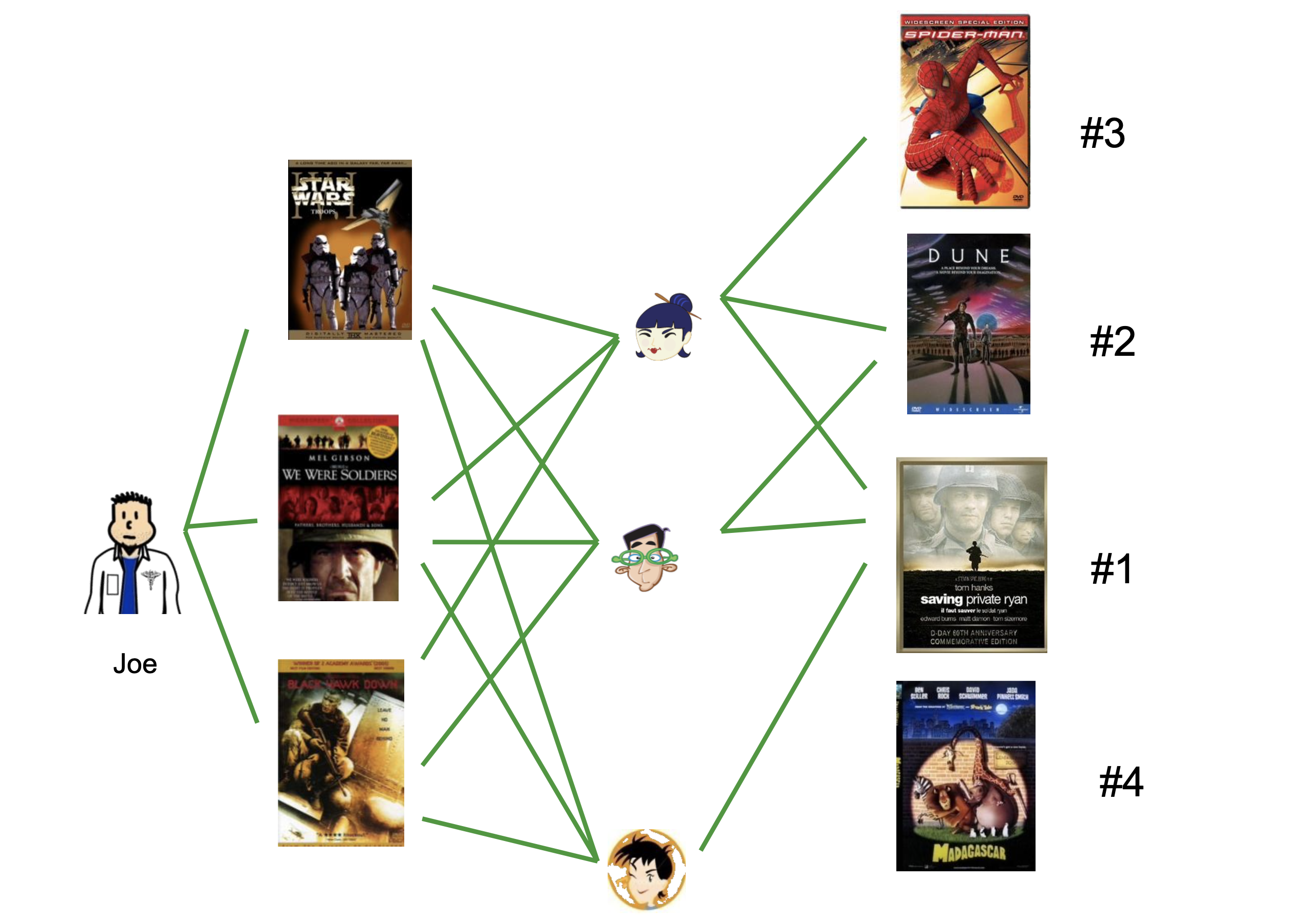
There are at least two ways this graph can be used.
To form a rating for item \((u, i)\):
Using user-user similarity:
look at users that have similar item preferences to user \(u\)
look at how those users rated item \(i\)
Good for many users, fewer items
Using item-item similarity:
look at other items that have been liked by similar users as item \(i\)
look at how user \(u\) rated those items
Good for many items, fewer users
Item-item CF#
Let’s look at the item-item CF approach in detail.
The questions are:
How do we judge “similarity” of items?
How do we form a predicted rating?
Here is another view of the ratings graph, this time as a matrix that includes missing entries:
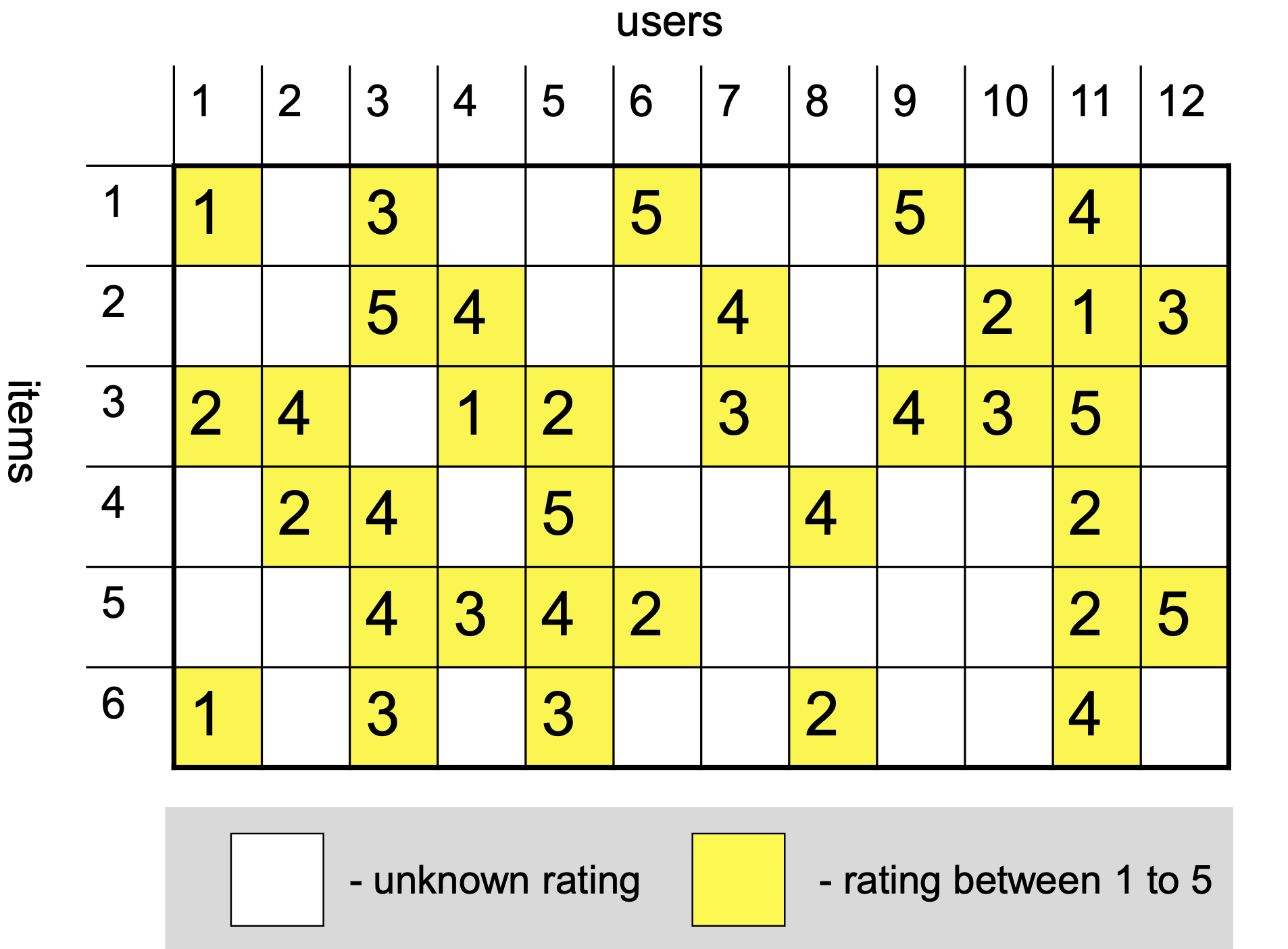
Let’s say we want to predict the value of this unknown rating:
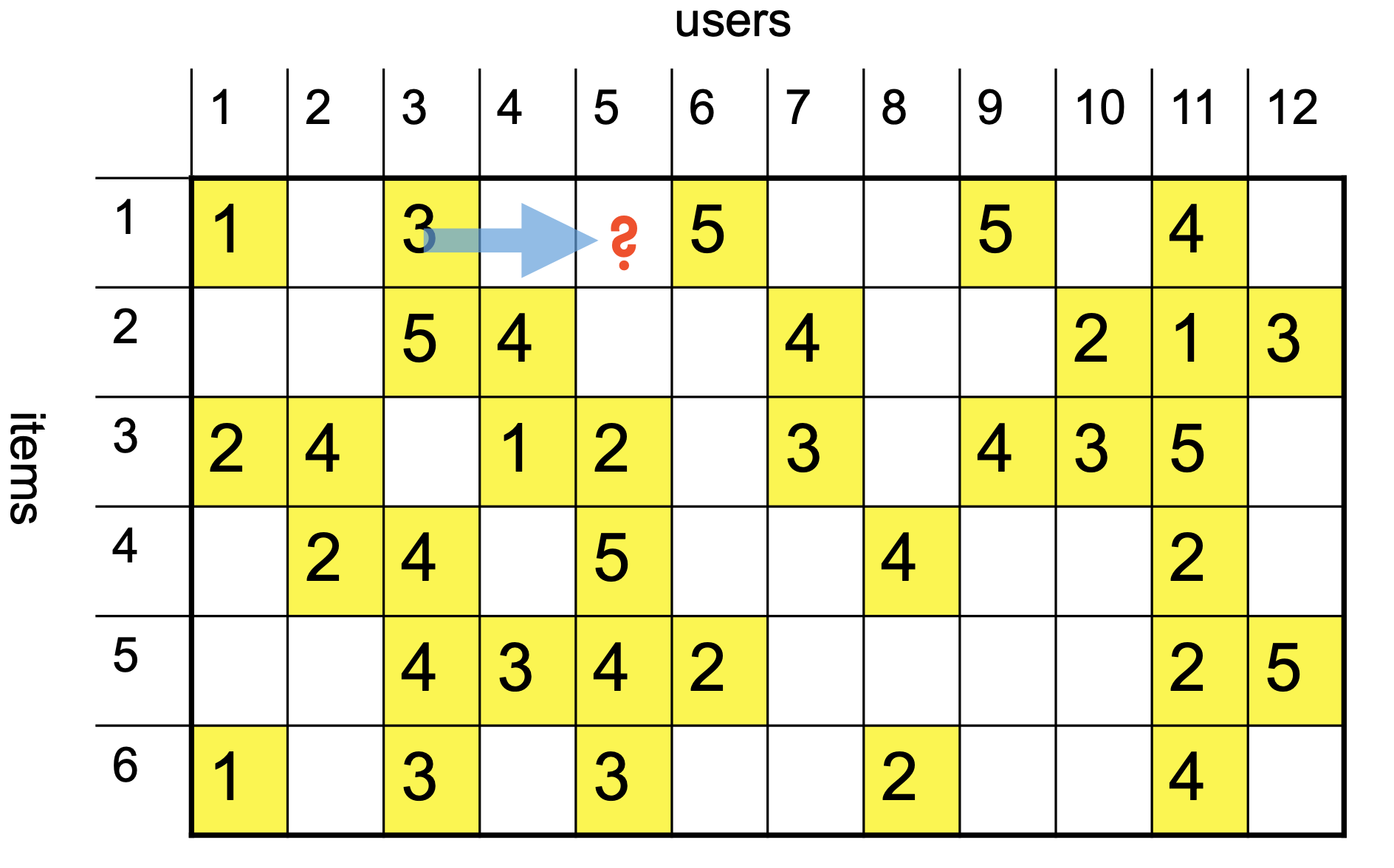
We’ll consider two other items, namely items 3 and 6 (for example).
Note that we are only interested in items that this user has rated.

We will discuss strategies for assessing similarity shortly.
How did we choose these two items?
We used \(k\)-nearest neighbors. Here \(k\) = 2.
For now, let’s just say we determine the similarities as:
These similarity scores tell us how much weight to put on the rating of the other items.
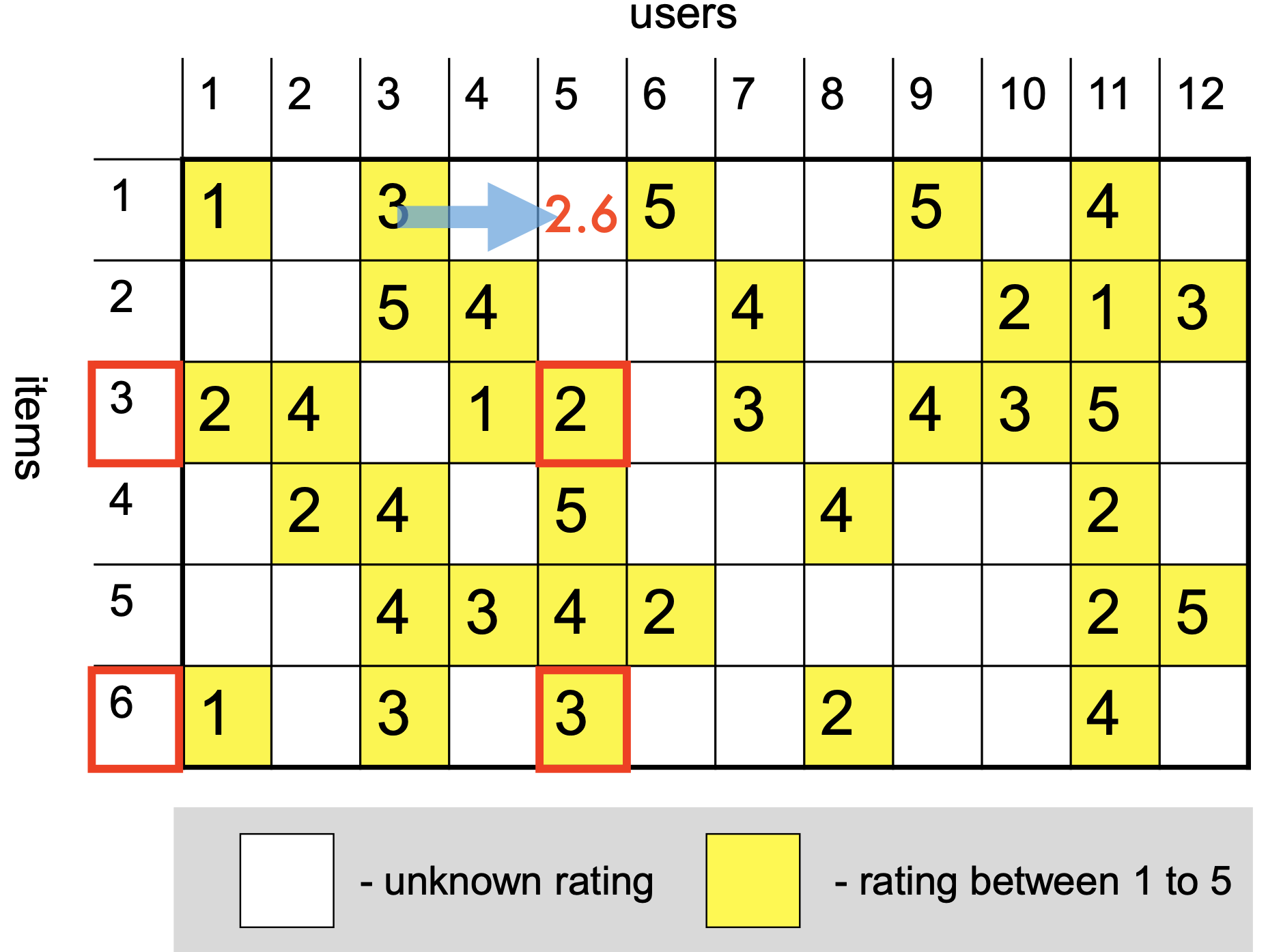
So we can form a prediction of \(\hat{r}_{15}\) as:
Similarity#
How should we assess similarity of items?
A reasonable approach is to consider items similar if their ratings are correlated.
So we can use the Pearson correlation coefficient \(r\).
However, note that two items will not have ratings in the same positions.

So we want to compute correlation only over the users who rated both the items.
In some cases we will need to work with binary \(r_{ui}\)s.
For example, purchase histories on an e-commerce site, or clicks on an ad.
In this case, an appropriate replacement for Pearson \(r\) is the Jaccard similarity coefficient.
(See the lecture on similarity measures.)
Improving CF#
One problem with the story so far arises due to bias.
Some items are significantly higher or lower rated
Some users rate substantially higher or lower in general
These properties interfere with similarity assessment.
Bias correction is crucial for CF recommender systems.
We need to include
Per-user offset
Per-item offset
Global offset
Hence we need to form a per-item bias of:
where \(\alpha_u\) is the per-user offset of user \(u\) and \(\beta_i\) is the per-item offset of item \(i\).
How can we estimate the \(\alpha\)s, the \(\beta\)s, and the \(\mu\)?
Let’s assume for a minute that we had a fully-dense matrix of ratings \(R\).
\(R\) has items on the rows and users on the columns.
Then what we want to estimate is
Here, \(\mathbf{1}\) represents appropriately sized vectors of ones, and \(1\) is a matrix of ones.
While this is not a simple ordinary least squares problem, there is a strategy for solving it.
Assume we hold \(\beta\mathbf{1}^T + \mu1\) constant.
Then the remaining problem is
which (for each column of \(R\)) is a standard least squares problem (which we solve via Ridge regression).
This sort of problem is called jointly convex.
The strategy for solving is:
Hold \(\alpha\) and \(\beta\) constant, solve for \(\mu\).
Hold \(\alpha\) and \(\mu\) constant, solve for \(\beta\).
Hold \(\beta\) and \(\mu\) constant, solve for \(\alpha\).
Each of the three steps will reduce the overall error. So we iterate over them until convergence.
The last issue is that the matrix \(R\) is not dense - in reality we only have a small subset of its entries.
We simply need to adapt the least-squares solution to only consider the entries in \(R\) that we know.
As a result, the actual calculation is:
Step 1:
Step 2:
Step 3:
Step 4: If not converged, go to Step 1.
Now that we have the biases learned, we can do a better job of estimating correlation:
where
\(b_{ui} = \mu + \alpha_u + \beta_i\), and
\(U(i,j)\) are the users who have rated both \(i\) and \(j\).
And using biases we can also do a better job of estimating ratings:
where
\(b_{ui} = \mu + \alpha_u + \beta_i\), and
\(n_k(i, u)\) are the \(k\) nearest neighbors to \(i\) that were rated by user \(u\).
Assessing CF#
This completes the high level view of CF.
Working with user-user similarities is analogous.
Strengths:
Essentially no training.
The reliance on \(k\)-nearest neighbors helps in this respect.
Easy to update with new users, items, and ratings
Can be explained to user:
“We recommend Minority Report because you liked Blade Runner and Total Recall.”
Weaknesses:
Accuracy can be a problem
Scalability can be a problem (think \(k\)-NN)
Matrix Factorization#
Note that standard CF forces us to consider similarity among items, or among users, but does not take into account both.
Can we use both kinds of similarity simultaneously?
We can’t use both the rows and columns of the ratings matrix \(R\) at the same time – the user and item vectors live in different vector spaces.
What we could try to do is find a single vector space in which we represent both users and items, along with a similarity function, such that:
users who have similar item ratings are similar in the vector space
items who have similar user ratings are similar in the vector space
when a given user highly rates a given item, that user and item are similar in the vector space.
Koren et al, IEEE Computer, 2009
We saw this idea previously, in an SVD lecture.
This new vector space is called a latent space,
and the user and item representations are called latent vectors.
Now, however, we are working with a matrix which is only partially observed.
That is, we only know some of the entries in the ratings matrix.
Nonetheless, we can imagine a situation like this:

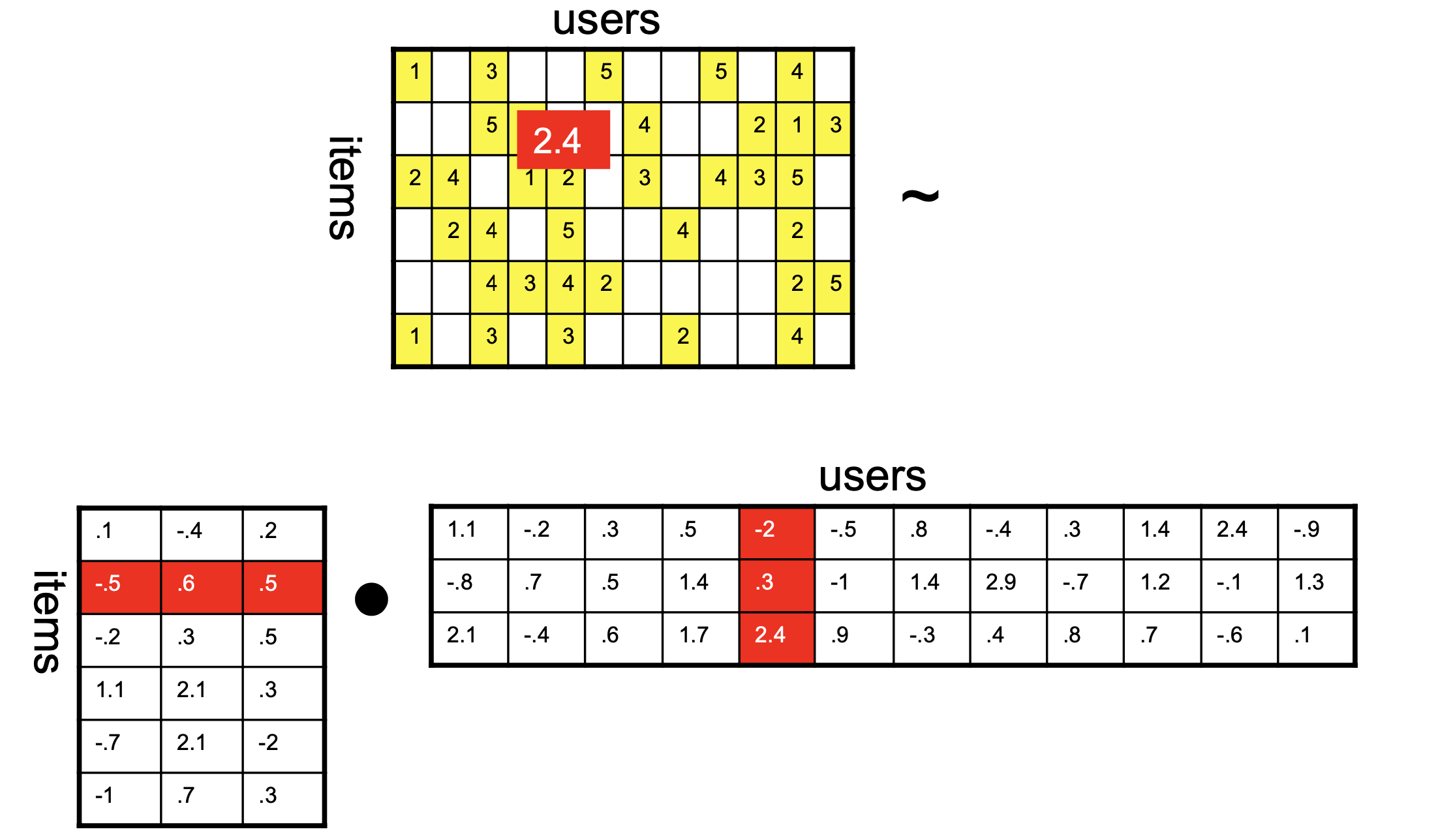
Now we want the product of the two matrices on the right to be as close as possible to the known values of the ratings matrix.
What this setup implies is that our similarity function is the inner product.
Which means that to predict an unknown rating, we take the inner product of latent vectors:
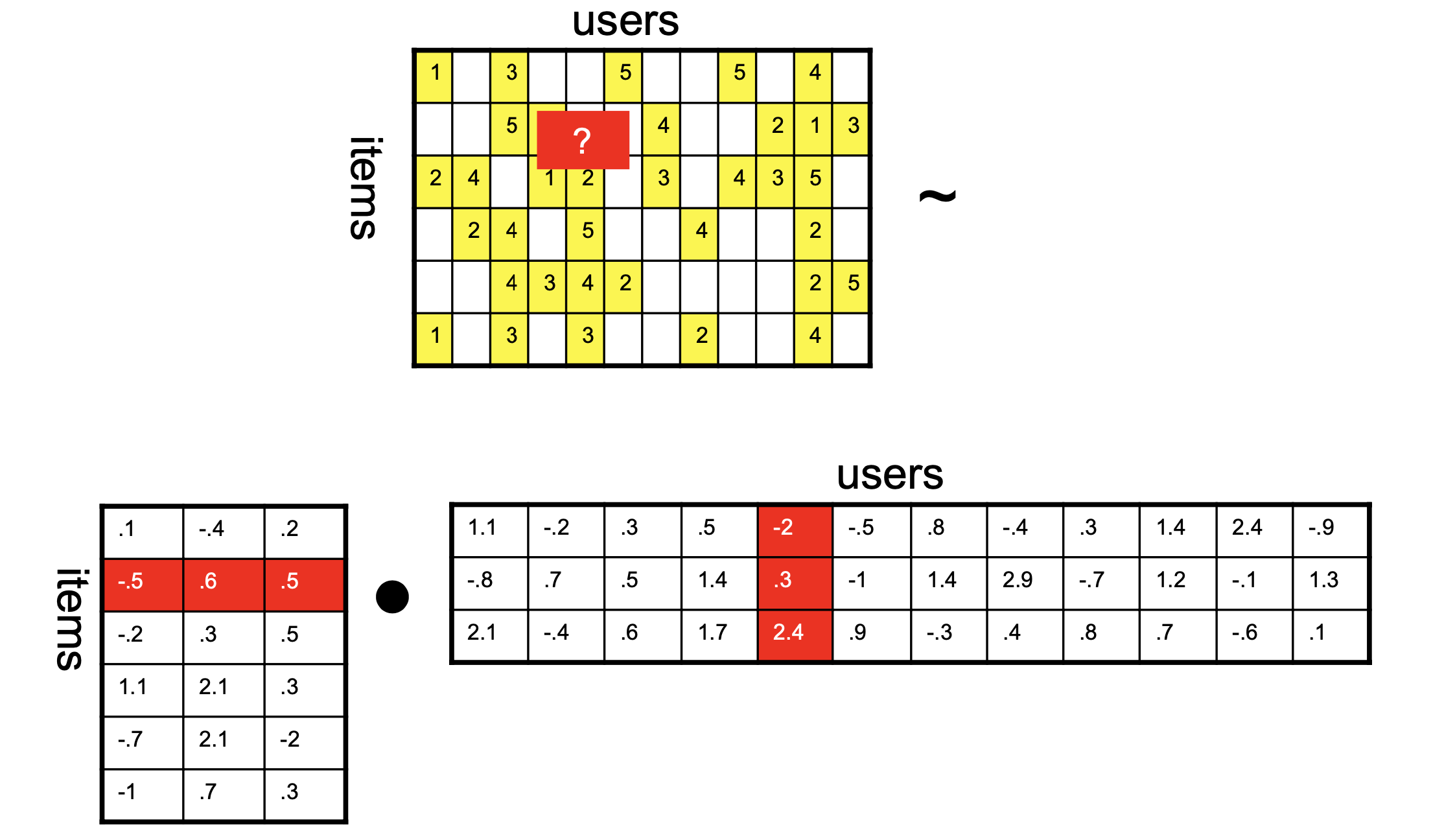
Now \((-2 \cdot -0.5)+(0.3 \cdot 0.6)+(2.5 \cdot 0.5) = 2.43\), so:
Solving Matrix Factorization#
Notice that in this case we’ve decided that the factorization should be rank 3, ie, low-rank.
So we want something like an SVD.
(Recall that SVD gives us the most-accurate-possible low-rank factorization of a matrix).
However, we can’t use the SVD algorithm directly, because we don’t know all the entries in \(R\).
(Indeed, the unseen entries in \(R\) as exactly what we want to predict.)
Here is what we want to solve:
where \(R\) is \(m\times n\), \(U\) is the \(m\times k\) items matrix and \(V\) is the \(n\times k\) users matrix.
The \((\cdot)_S\) notation means that we are only considering the matrix entries that correspond to known reviews (the set \(S\)).
Note that as usual, we add \(\ell_2\) penalization to avoid overfitting (Ridge regression).
Once again, this problem is jointly convex.
In particular, it we hold either \(U\) or \(V\) constant, then the result is a simple ridge regression.
So one commonly used algorithm for this problem is called alternating least squares:
Hold \(U\) constant, and solve for \(V\)
Hold \(V\) constant, and solve for \(U\)
If not converged, go to Step 1.
The only thing I’ve left out at this point is how to deal with the missing entries of \(R\).
It’s not hard, but the details aren’t that interesting, so I will give you code instead!
ALS in Practice#
The entire Amazon reviews dataset is too large to work with easily, and it is too sparse.
Hence, we will take the densest rows and columns of the matrix.
# The densest columns: products with more than 50 reviews
pids = df.groupby('ProductId').count()['Id']
hi_pids = pids[pids > 50].index
# reviews that are for these products
hi_pid_rec = [r in hi_pids for r in df['ProductId']]
# the densest rows: users with more than 50 reviews
uids = df.groupby('UserId').count()['Id']
hi_uids = uids[uids > 50].index
# reviews that are from these users
hi_uid_rec = [r in hi_uids for r in df['UserId']]
# reviews that are from those users and for those movies
goodrec = [a and b for a, b in zip(hi_uid_rec, hi_pid_rec)]
Now we create a matrix from these reviews.
Missing entries will be filled with NaNs.
dense_df = df.loc[goodrec]
good_df = dense_df.loc[~df['Score'].isnull()]
R = good_df.pivot_table(columns = 'ProductId', index = 'UserId', values = 'Score')
R
| ProductId | 0005019281 | 0005119367 | 0307142485 | 0307142493 | 0307514161 | 0310263662 | 0310274281 | 0718000315 | 0764001035 | 0764003828 | ... | B00IKM5OCO | B00IWULQQ2 | B00J4LMHMK | B00J5JSV1W | B00JA3RPAG | B00JAQJMJ0 | B00JBBJJ24 | B00JKPHUE0 | B00K2CHVJ4 | B00L4IDS4W |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UserId | |||||||||||||||||||||
| A02755422E9NI29TCQ5W3 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| A100JCBNALJFAW | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| A10175AMUHOQC4 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| A103KNDW8GN92L | NaN | NaN | NaN | NaN | NaN | 4.0 | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| A106016KSI0YQ | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| AZUBX0AYYNTFF | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AZXGPM8EKSHE9 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AZXHK8IO25FL6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AZXR5HB99P936 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AZZ4GD20C58ND | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
3677 rows × 7244 columns
import MF as MF
# I am pulling these hyperparameters out of the air;
# That's not the right way to do it!
RS = MF.als_MF(rank = 20, lambda_ = 1)
%time pred, error = RS.fit_model(R)
CPU times: user 7min 51s, sys: 2min 6s, total: 9min 58s
Wall time: 1min 2s
RMSE on visible entries (training data): 0.343
pred
| ProductId | 0005019281 | 0005119367 | 0307142485 | 0307142493 | 0307514161 | 0310263662 | 0310274281 | 0718000315 | 0764001035 | 0764003828 | ... | B00IKM5OCO | B00IWULQQ2 | B00J4LMHMK | B00J5JSV1W | B00JA3RPAG | B00JAQJMJ0 | B00JBBJJ24 | B00JKPHUE0 | B00K2CHVJ4 | B00L4IDS4W |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UserId | |||||||||||||||||||||
| A02755422E9NI29TCQ5W3 | 4.829528 | 5.291700 | 4.894401 | 4.639195 | 4.909813 | 3.935429 | 4.744772 | 4.110960 | 4.872587 | 4.564415 | ... | 3.436324 | 5.089657 | 4.628777 | 2.579329 | 4.176442 | 4.424858 | 4.063830 | 3.133098 | 2.964667 | 4.495810 |
| A100JCBNALJFAW | 4.114644 | 4.318371 | 4.652237 | 4.082670 | 4.329506 | 2.659661 | 3.912704 | 3.110404 | 2.813416 | 3.561825 | ... | 3.139748 | 4.244405 | 2.944293 | 3.139894 | 2.904268 | 3.795533 | 2.827684 | 2.370121 | 2.323547 | 2.641563 |
| A10175AMUHOQC4 | 4.485396 | 5.302857 | 4.672847 | 5.497835 | 4.057506 | 5.339142 | 4.434440 | 3.707566 | 3.611799 | 5.640831 | ... | 3.448205 | 4.893147 | 4.703348 | 2.634570 | 3.768816 | 4.210222 | 4.403217 | 4.545293 | 3.234381 | 4.679152 |
| A103KNDW8GN92L | 4.365361 | 4.943661 | 4.263153 | 4.604154 | 5.214505 | 3.635082 | 4.565919 | 3.754527 | 4.231372 | 4.400860 | ... | 4.468246 | 4.599308 | 4.518040 | 3.116851 | 3.713601 | 5.067549 | 2.831701 | 2.722861 | 3.709238 | 4.898436 |
| A106016KSI0YQ | 3.516412 | 3.936477 | 3.942878 | 3.910154 | 4.216858 | 2.794978 | 3.600015 | 3.672199 | 3.721686 | 5.267729 | ... | 3.748664 | 3.835250 | 4.083559 | 1.941428 | 3.413994 | 4.144104 | 4.046779 | 2.400719 | 1.878588 | 3.122137 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| AZUBX0AYYNTFF | 3.828343 | 4.093437 | 4.205352 | 4.279512 | 4.181050 | 3.918984 | 3.760408 | 3.089374 | 3.006370 | 3.851920 | ... | 2.750957 | 3.807990 | 3.043175 | 2.287013 | 2.250548 | 4.262020 | 3.630020 | 2.369120 | 1.719792 | 2.639736 |
| AZXGPM8EKSHE9 | 3.671199 | 3.967644 | 2.909250 | 3.879929 | 4.737901 | 2.466704 | 3.057772 | 2.337199 | 2.863227 | 2.793442 | ... | 2.324889 | 3.349504 | 3.125523 | 3.882825 | 2.102170 | 3.239544 | 2.202316 | 1.847395 | 2.838113 | 2.903009 |
| AZXHK8IO25FL6 | 3.298820 | 4.168160 | 4.784003 | 4.911388 | 3.734663 | 1.962288 | 3.680044 | 2.229222 | 2.602694 | 4.191144 | ... | 2.920003 | 3.361532 | 3.215035 | 2.144148 | 3.246263 | 4.403988 | 4.207952 | 1.360192 | 0.368289 | 3.441173 |
| AZXR5HB99P936 | 4.351917 | 4.723345 | 4.245682 | 4.972561 | 4.774367 | 4.244336 | 4.185600 | 3.293305 | 3.870670 | 3.925679 | ... | 3.182625 | 4.216027 | 3.250807 | 2.262442 | 3.286743 | 4.508260 | 4.501938 | 2.379096 | 2.238436 | 2.969018 |
| AZZ4GD20C58ND | 4.319594 | 4.623446 | 5.132355 | 5.033353 | 5.081330 | 4.247662 | 4.305182 | 3.667751 | 3.336328 | 3.594246 | ... | 3.278369 | 4.154962 | 4.097241 | 3.549720 | 3.170789 | 5.037781 | 3.385402 | 2.179712 | 2.662272 | 2.587184 |
3677 rows × 7244 columns
## todo: hold out test data, compute oos error
RN = ~R.isnull()
visible = np.where(RN)
import sklearn.model_selection as model_selection
X_train, X_test, Y_train, Y_test = model_selection.train_test_split(visible[0], visible[1], test_size = 0.1)
Just for comparison’s sake, let’s check the performance of \(k\)-NN on this dataset.
Again, this is only on the training data – so overly optimistic for sure.
And note that this is a subset of the full dataset – the subset that is “easiest” to predict due to density.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import mean_squared_error
X_train = good_df.drop(columns=['Id', 'ProductId', 'UserId', 'Text', 'Summary'])
y_train = good_df['Score']
# Using k-NN on features HelpfulnessNumerator, HelpfulnessDenominator, Score, Time
model = KNeighborsClassifier(n_neighbors=3).fit(X_train, y_train)
%time y_hat = model.predict(X_train)
CPU times: user 4.29 s, sys: 13.1 ms, total: 4.3 s
Wall time: 4.3 s
RMSE on visible entries (test set): 0.649
Assessing MF#
Matrix Factorization per se is a good idea. However, many of the improvements we’ve discussed for CF apply to MF as well.
To illustrate, we’ll look at some of the successive improvements used by the team that won the Netflix prize (“BellKor’s Pragmatic Chaos”).
When the prize was announced, the Netflix supplied solution achieved an RMSE of 0.951.
By the end of the competition (about 3 years), the winning team’s solution achieved RMSE of 0.856.
Let’s restate our MF objective in a way that will make things clearer:
1. Adding Biases
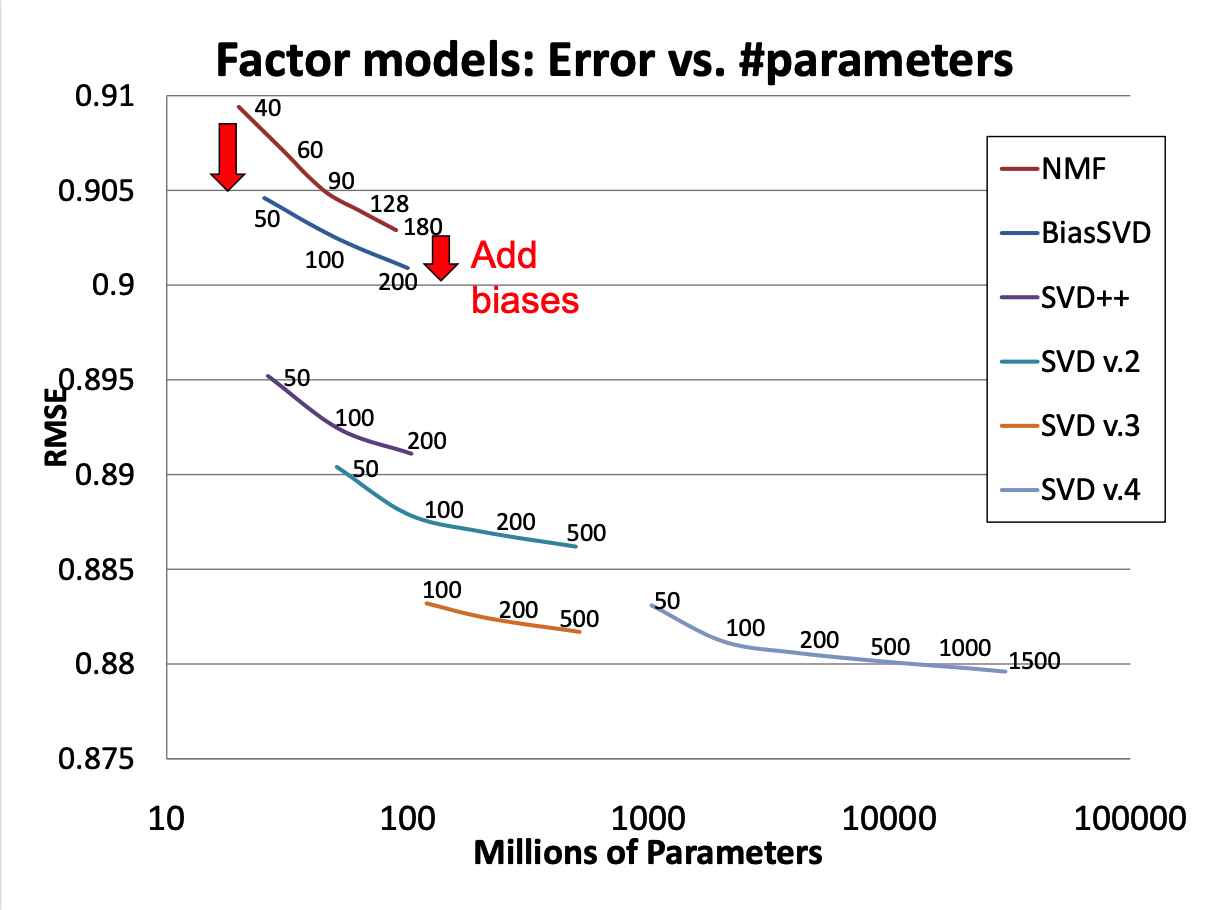
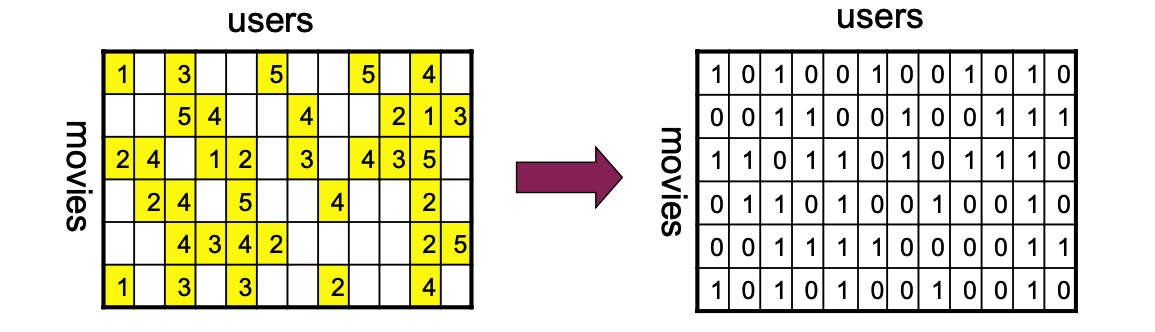
2. Who Rated What?
In reality, ratings are not provided at random.
Take note of which users rated the same movies (ala CF) and use this information.

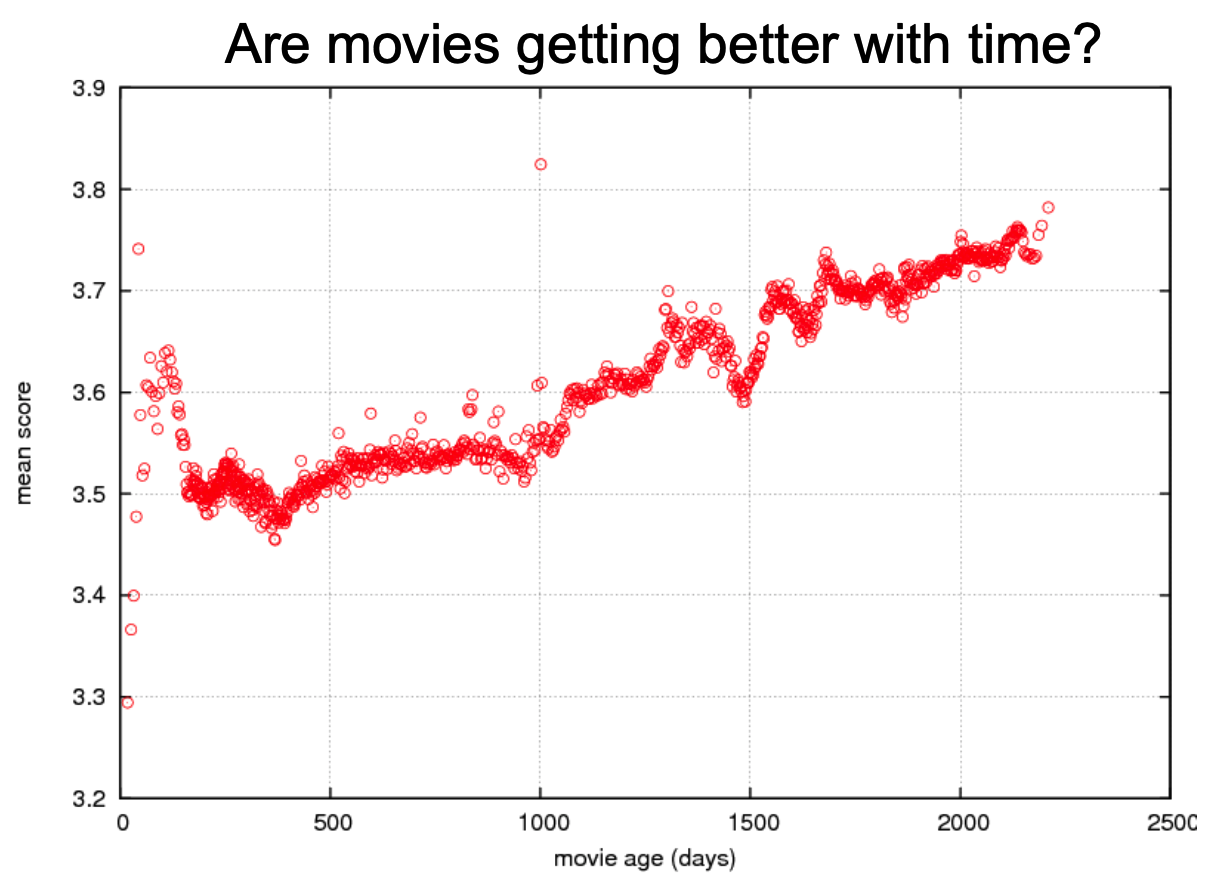
3. Ratings Change Over Time
Older movies tend to get higher ratings!

To estimate these billions of parameters, we cannot use alternating least squares or any linear algebraic method.
We need to use gradient descent (which we will cover in a future lecture).
Assessing Recommender Systems#
There are a number of concerns with the widespread use of recommender systems and personalization in society.
First, recommender systems are accused of creating filter bubbles.
A filter bubble is the tendency for recommender systems to limit the variety of information presented to the user.
The concern is that a user’s past expression of interests will guide the algorithm in continuing to provide “more of the same.”
This is believed to increase polarization in society, and to reinforce confirmation bias.
Second, recommender systems in modern usage are often tuned to maximize engagement.
In other words, the objective function of the system is not to present the user’s most favored content, but rather the content that will be most likely to keep the user on the site.
The incentive to maximize engagement arises on sites that are supported by advertising revenue.
More engagement time means more revenue for the site.
However, many studies have shown that sites that strive to maximize engagement do so in large part by guiding users toward extreme content:
content that is shocking,
or feeds conspiracy theories,
or presents extreme views on popular topics.
Given this tendency of modern recommender systems, for a third party to create “clickbait” content such as this, one of the easiest ways is to present false claims.
Methods for addressing these issues are being very actively studied at present.
Ways of addressing these issues can be:
via technology
via public policy
Note
You can read about some of the work done in my group on this topic:
How YouTube Leads Privacy-Seeking Users Away from Reliable Information, Larissa Spinelli and Mark Crovella, Proceedings of the Workshop on Fairness in User Modeling, Adaptation, and Personalization (FairUMAP), 2020.
Closed-Loop Opinion Formation, Larissa Spinelli and Mark Crovella Proceedings of the 9th International ACM Web Science Conference (WebSci), 2017.
Fighting Fire with Fire: Using Antidote Data to Improve Polarization and Fairness of Recommender Systems, Bashir Rastegarpanah, Krishna P. Gummadi and Mark Crovella Proceedings of WSDM, 2019.