\(k\)-means#

1854 saw a horrific cholera outbreak in Soho, London.
Common wisdom at the time was that disease spread by breathing “foul air” (miasma).
The London sewer system had not yet reached Soho. Most homes had cesspits under the floor.
John Snow, a local physician, extensively studied the patterns of illness across Soho due to cholera.

In the course of his studies, his attention was drawn to one neighborhood around Broad Street.
In 10 days, 500 people in the area died.
In uncovering the source of this outbreak, Snow prepared this map:
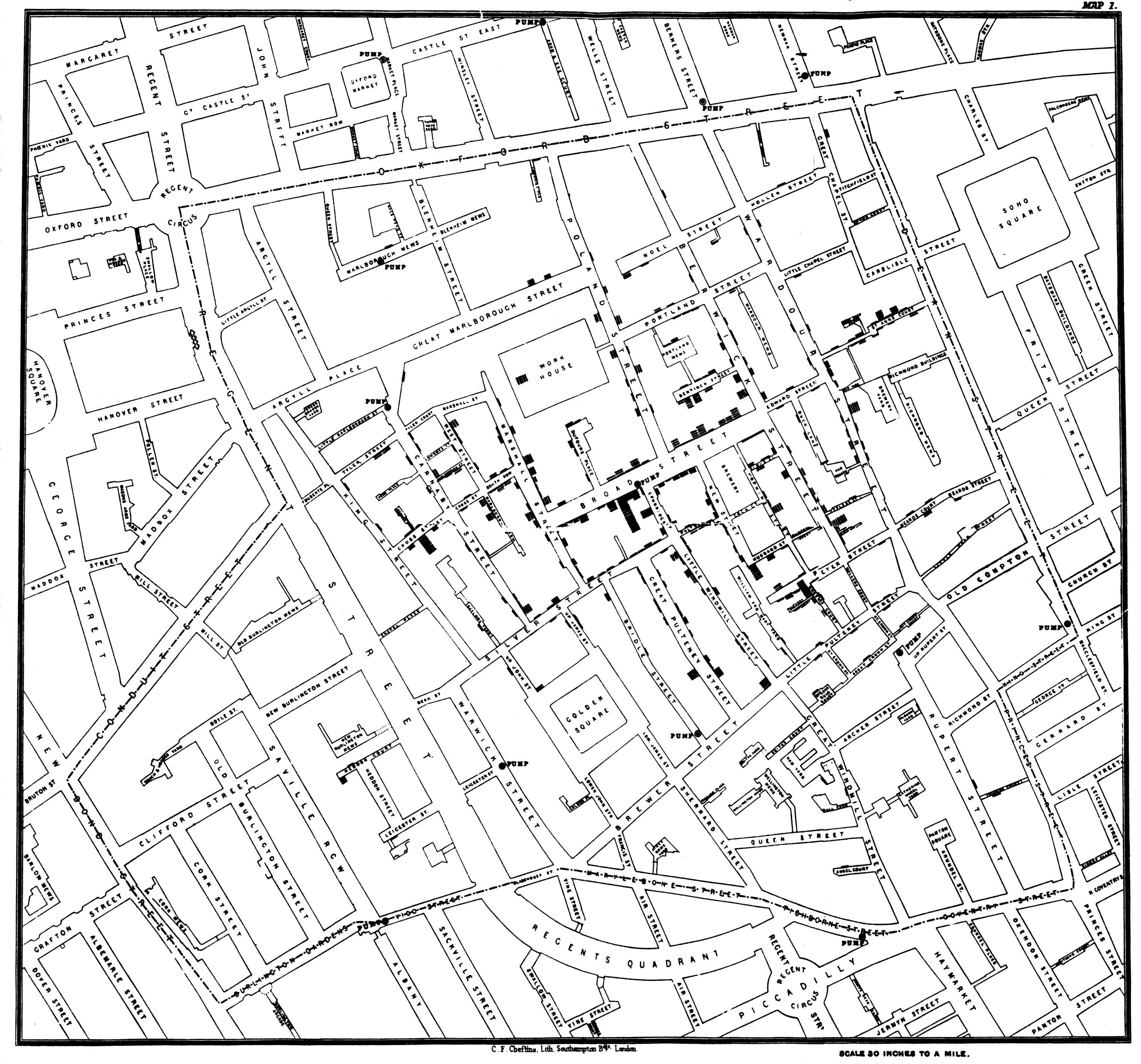
By John Snow - Published by C.F. Cheffins, Lith, Southhampton Buildings, London, England, 1854 in Snow, John. On the Mode of Communication of Cholera, 2nd Ed, John Churchill, New Burlington Street, London, England, 1855.
(This image was originally from en.wikipedia; description page is/was here. Image copied from http://matrix.msu.edu/~johnsnow/images/online_companion/chapter_images/fig12-5.jpg), Public Domain, https://commons.wikimedia.org/w/index.php?curid=2278605
{kind=link}
{kind=link}
CC BY-SA 2.0, https://commons.wikimedia.org/w/index.php?curid=357998
John Snow’s original data is available here: http://blog.rtwilson.com/john-snows-cholera-data-in-more-formats/
Clustering is Unsupervised Learning#
Clustering is a very important way of discovering structure in data.
It is so important because it is common for data to show clusters.
Locations where millionaires live
The number of hours people work each week
Demographics (“soccer moms”, “bored retirees”, “unemployed millenials”, etc)
We can often simplify or compress our data if we recognize the existence of clusters.
Further, we can often interpret clusters by assigning them labels.
However, note that these categories or “labels” are assigned after the fact.
And, we may not be able to interpret clusters or assign them labels in some cases.
That is, clustering represents the first example we will see of unsupervised learning.
Supervised methods: Data items have labels, and we want to learn a function that correctly assigns labels to new data items.
Unsupervised methods: Data items do not have labels, and we want to learn a function that extracts important patterns from the data.
Applications of Clustering:
Image Processing
Cluster images based on their visual content
Compress images based on color clusters
Web Mining
Cluster groups of users based on webpage access patterns
Cluster web pages based on their content
Bioinformatics
Cluster similar proteins together (by structure or function)
Cluster cell types (by gene activity)
And many more …
The Clustering Problem#
When we do clustering, what problem are we trying to solve?
We will answer this question informally at first.
(But soon we will look at formal criteria!)
Informally, a clustering is:
a grouping of data objects, such that the objects within a group are similar (or near) to one another and dissimilar (or far) from the objects in other groups.
(keep in mind that if we use a distance function as a dissimilarity measure, then “far” implies “different”)
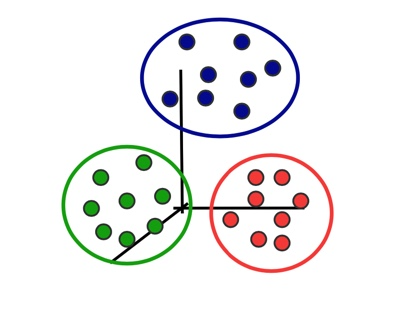
So we want our clustering algorithm to:
minimize intra-cluster distances
maximize inter-cluster distances
Here are the basic questions we need to ask about clustering:
What is the right kind of ”similarity” to use?
What is a ”good” partition of objects?
ie, how is the quality of a solution measured?
How to find a good partition?
are there efficient algorithms?
are there algorithms that are guaranteed to find good clusters?
Now note that even with our more-formal discussion, the criteria for deciding on a “best” clustering can still be ambiguous.

To accommodate the ambiguity here, one approach is to seek a hierarchical clustering:
That is, as set of nested clusters organized in a tree.
We’ll discuss hierarchical cluster in an upcoming lecture.
For today, we’ll focus on partitional clustering:
in a partitional clustering, the points are divided into a set of non-overlapping groups.
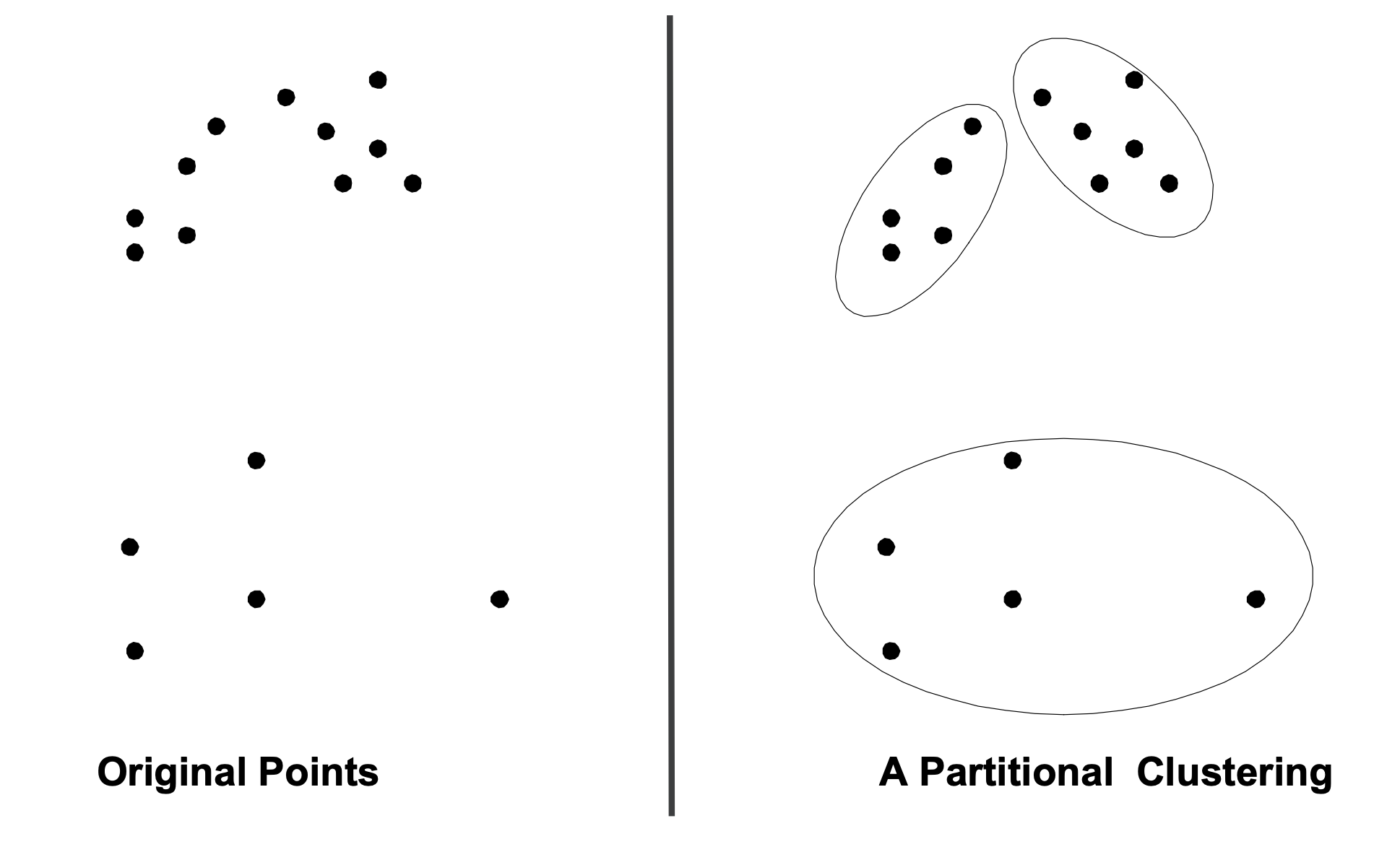
In a partitional clustering:
Each object belongs to one, and only one, cluster
The set of clusters covers all the objects
We are going to assume for now that the number of clusters is given in advance.
We will denote the number of clusters as \(k\).
The \(k\)-means Problem#
Now, we are ready to state our first formalization of the clustering problem.
We will assume that
data items are represented by points in \(\mathbb{R}^d\). (In other words, each data item has \(d\) features.)
\(n\) points are given
the number of clusters \(k\) is given
\(k\)-means Problem:
Find \(k\) points \(c_1, \dots, c_k\) (called centers, centroids, or means, so that the cost
is minimized.
Equivalently: we can think in terms of the partition itself.
Consider the set \(X = \{x_1, \dots, x_n\}\) where \(x_i \in \mathbb{R}^n\).
Find \(k\) points \(c_1, \dots, c_k\)
and partition \(X\) into subsets \(\{X_1, \dots, X_k\}\) by assigning each point \(x_i\) in \(X\) to its nearst cluster center,
so that the cost
is minimized.
We now have a formal definition of a clustering.
This is not the only definition possible, but it is an intuitive and simple one.
How hard is it to solve this problem?
\(k=1\) and \(k=n\) are easy special cases (why?)
But, this problem is NP-hard if the dimension of the data is at least 2
We don’t expect that there is any exact, efficient algorithm in general
Nonetheless, there is a simple algorithm that works quite well in practice!
The \(k\)-means Algorithm#
There is a “classic” algorithm for this problem.
It was voted among the top-10 algorithms in data mining!
It is such a good idea that it has been independently discovered multiple times.
It was first discovered by Lloyd in 1957, so it is often called Lloyd’s algorithm.
It is called the “\(k\)-means algorithm”
(not to be confused with the \(k\)-means problem!)

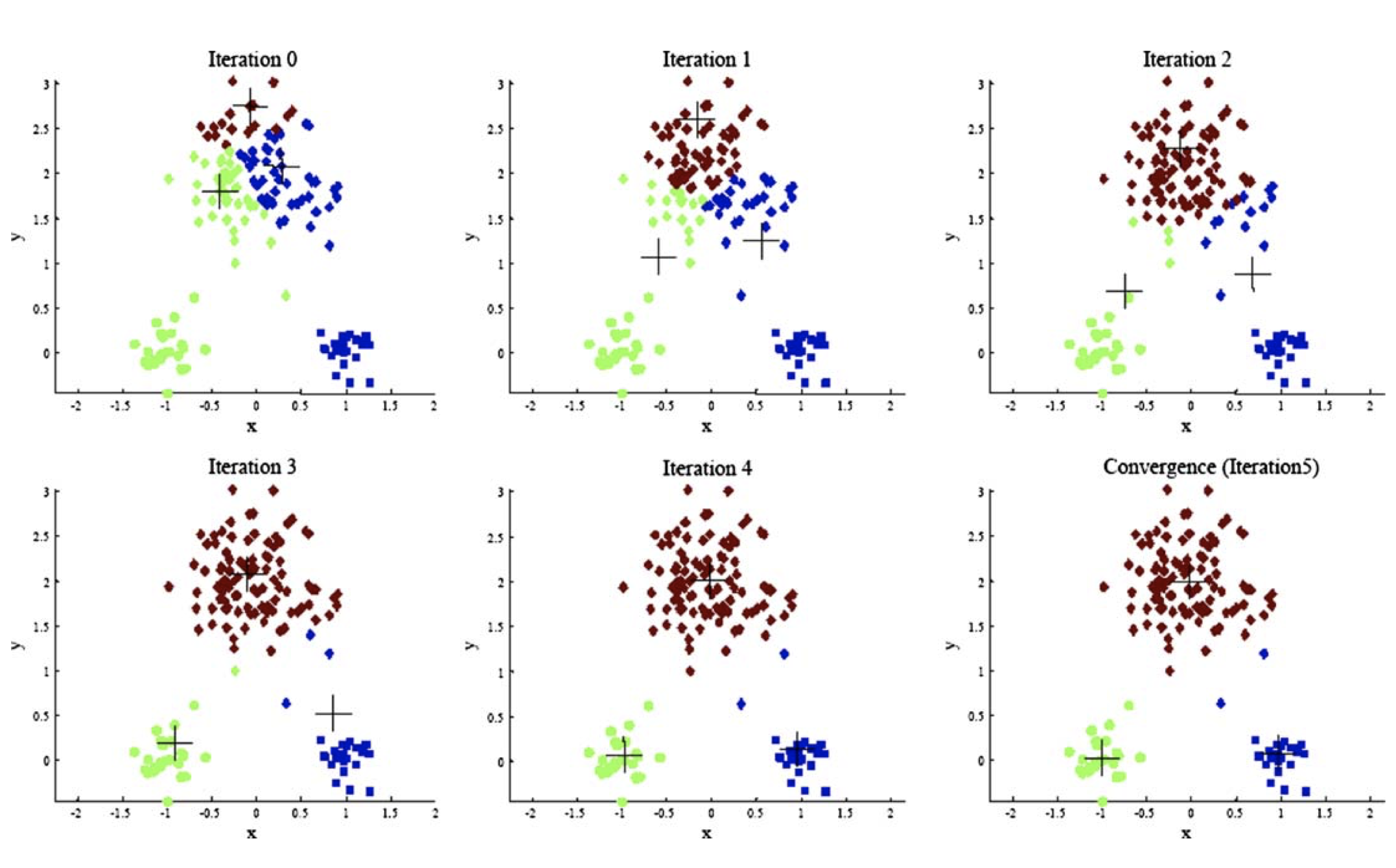
The \(k\)-means algorithm:
Pick \(k\) cluster centers \(\{c_1, \dots, c_k\}\). These can be chosen randomly, or by some other method.
For each \(j\), define the cluster \(X_j\) as the set of points in \(X\) that are closest to center \(c_k\).
(Nearer to \(c_k\) than to any other center.)For each \(j\), let \(c_j\) be the center of mass of cluster \(X_j\).
(In other words, \(c_j\) is the mean of the vectors in \(X_j\).)Repeat (ie, go to Step 2) until convergence.
Let’s see this in practice:
Limitations of \(k\)-means#
As you can see, \(k\)-means can work very well.
However, we don’t have any guarantees on the performance of \(k\)-means.
In particular, there are various settings in which \(k\)-means can fail to do a good job.
\(k\)-means tries to find spherical clusters.
Because each point is assigned to its closest center, the points in a cluster are implicitly assumed to be arranged in a sphere around the center.
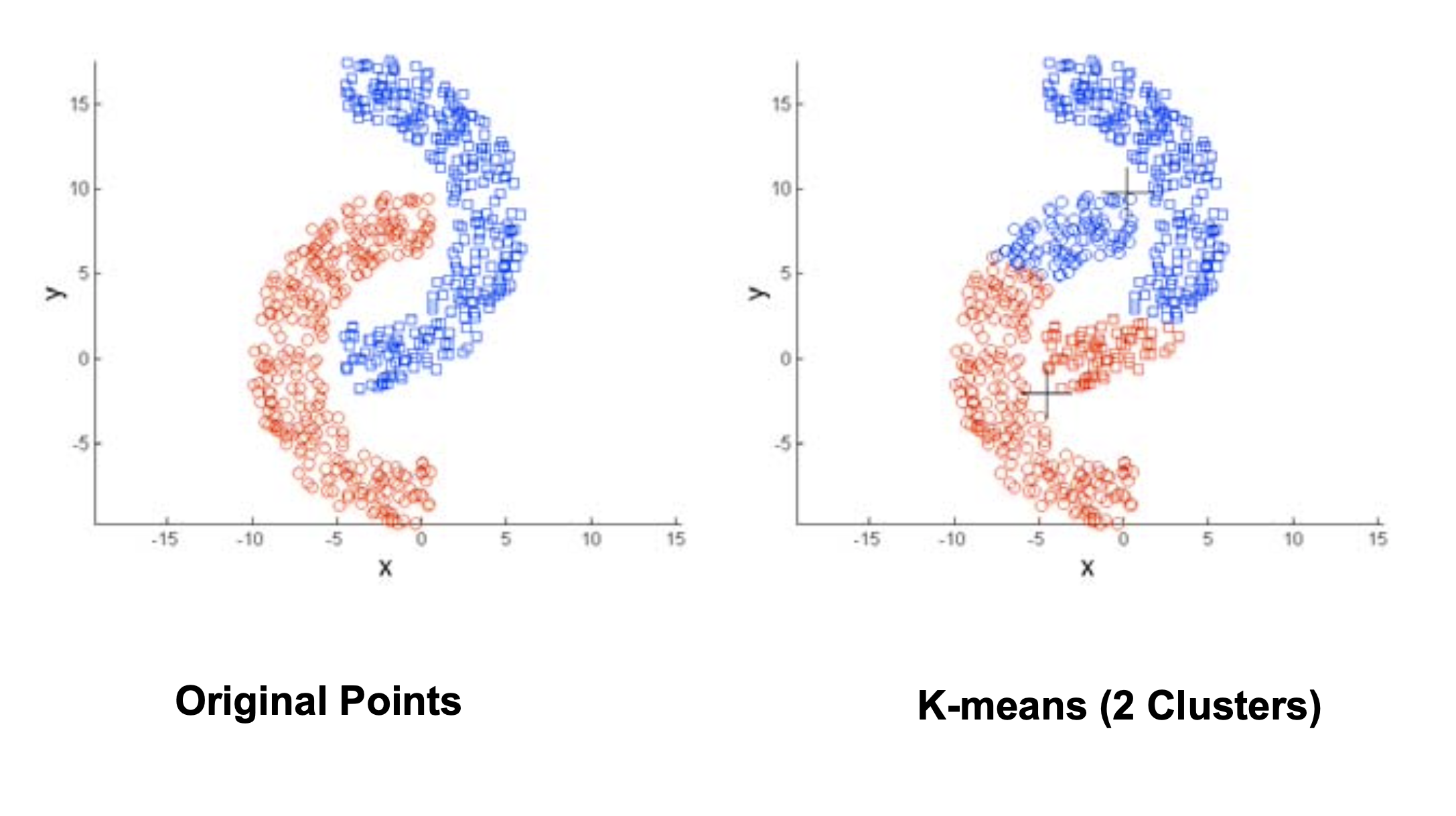
\(k\)-means tries to find equal-sized clusters.
For the same reason, the sizes of clusters are implicitly assumed to be approximately equal.
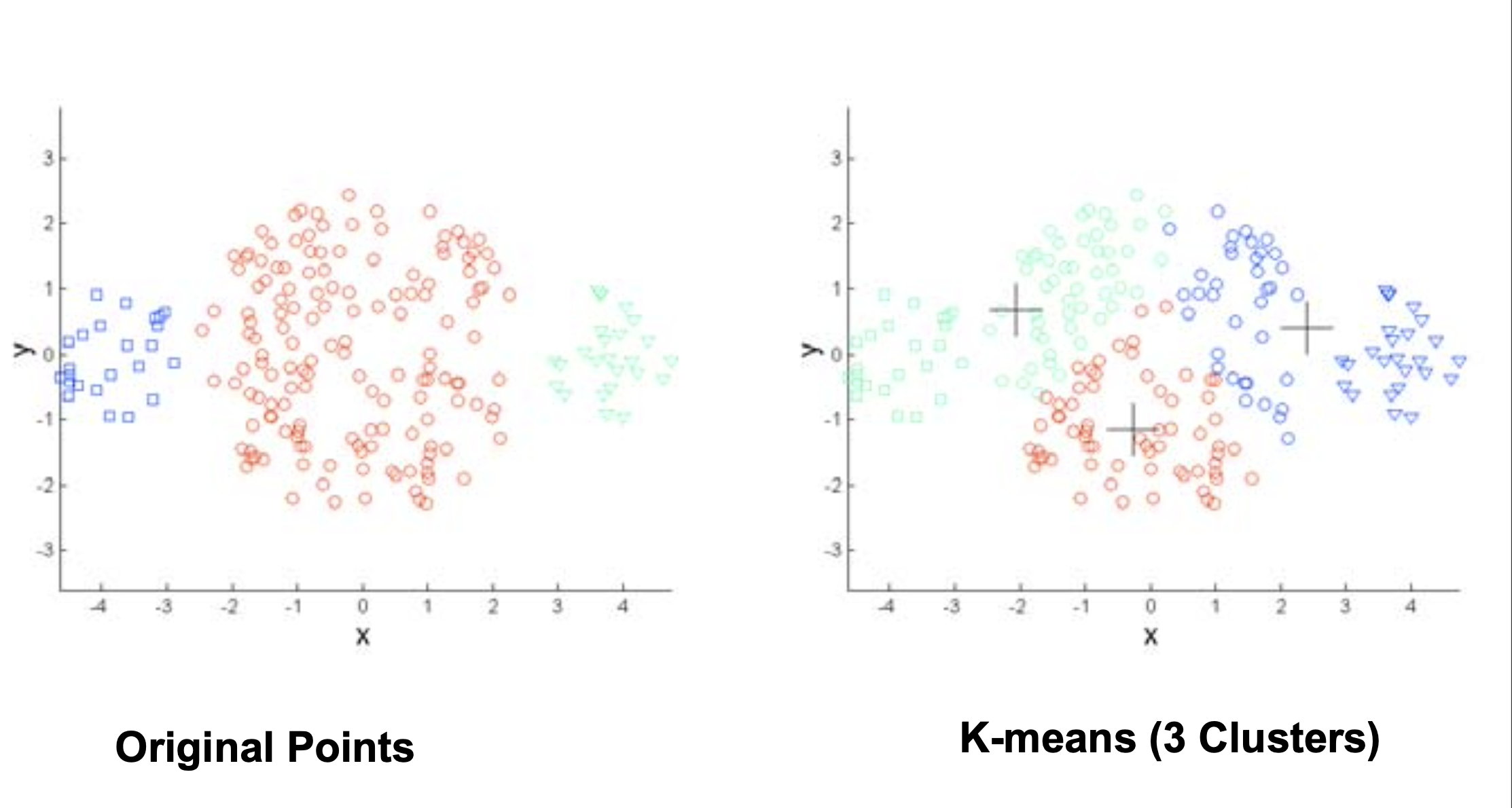
\(k\)-means is sensitive to the starting cluster centers.
If the initial guess (Step 1) is a bad one, \(k\)-means may get “stuck” in a bad solution.
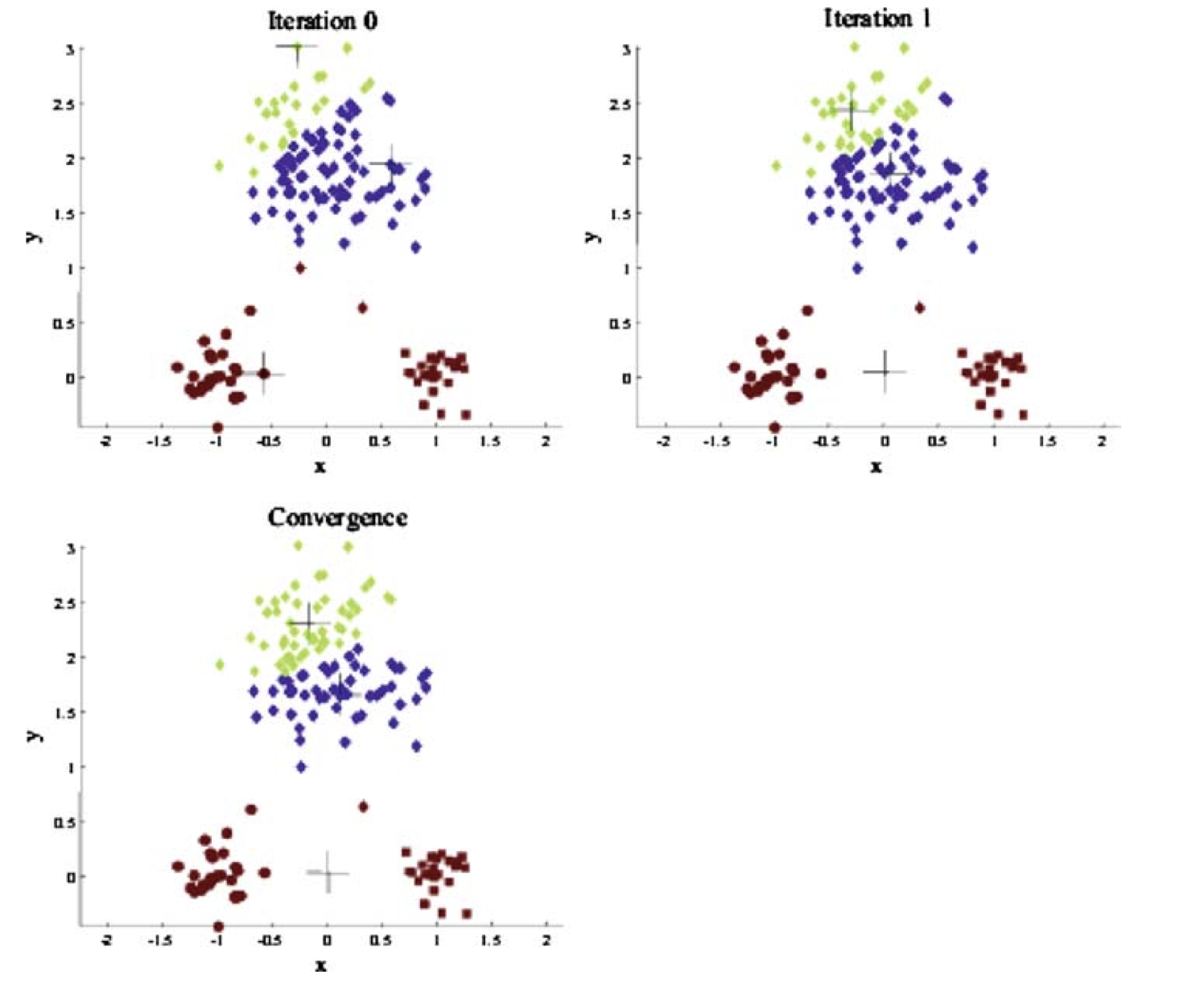
Choosing a Good Initialization#
How can we avoid the kind of bad initialization we just saw?
A good strategy is to pick points that are distant to each other.
This strategy is called “\(k\)-means++”.
It works very well in practice, and the scikit-learn implementation uses it by default.
(We will explore it in the next lecture.)
Choosing the right \(k\)#
Generally, we would say that, given some \(k\), the \(k\)-means algorithm “learns” the cluster centers – that is, the parameters of the model.
But we have not yet considered how to choose the right number of clusters.
That’s typically not something one knows in advance.
As an aside:
This parameter (\(k\)) is the first example we have seen of a hyperparameter.
A hyperparameter is a parameter that must be set before the model parameters can be learned.
Our basic strategy will be to
Iterate through different \(k\) and use some criterion to decide which \(k\) is most appropriate.
We will discuss this more in the next lecture.
Feature Scaling#
Finally, given the tendency of \(k\)-means to look for spherical clusters, we should consider the scales of the various features.
In fact, in general when constructing or selecting a distance metric, one needs to think carefully about the scale of the features being used.
For example, consider the case where we are clustering people based on their age, income, and gender.
We might use age in years, income in dollars, and assign gender to the values \(\{0, 1\}\).
Thus, the following records:
Joe Smith, age 27, income USD 75,000, male
Eve Jones, age 45, income USD 42,000, female
Would be encoded in feature space as:
What would happen if we used Euclidean distance as our dissimilarity metric in this feature space?
(This is what \(k\)-means uses.)
Clearly, the influence of income would dominate the other two features. For example, a difference of gender is about as significant as a difference of one dollar of yearly income.
We are unlikely to expose gender-based differences if we cluster using this representation.
The most common way to handle this is feature scaling.
The basic idea is to rescale each feature separately, so that its range of values is about the same as all other features.
For example, one may choose to:
shift each feature independently by subtracting the mean over all observed values
This means that each feature is now centered on zero
then rescale each feature so that the standard deviation overall observed values is 1.
This means that the feature will have about the same range of values as all the others.
For example, let’s work with Bortkiewicz’s famous horse-kick data:
# source: http://www.randomservices.org/random/data/HorseKicks.html
import pandas as pd
df = pd.read_table('data/HorseKicks.txt',index_col='Year',dtype='float')
counts = df.sum(axis=1)
counts
Year
1875.0 3.0
1876.0 5.0
1877.0 7.0
1878.0 9.0
1879.0 10.0
1880.0 18.0
1881.0 6.0
1882.0 14.0
1883.0 11.0
1884.0 9.0
1885.0 5.0
1886.0 11.0
1887.0 15.0
1888.0 6.0
1889.0 11.0
1890.0 17.0
1891.0 12.0
1892.0 15.0
1893.0 8.0
1894.0 4.0
dtype: float64
counts.hist(bins=25,xlabelsize=16);
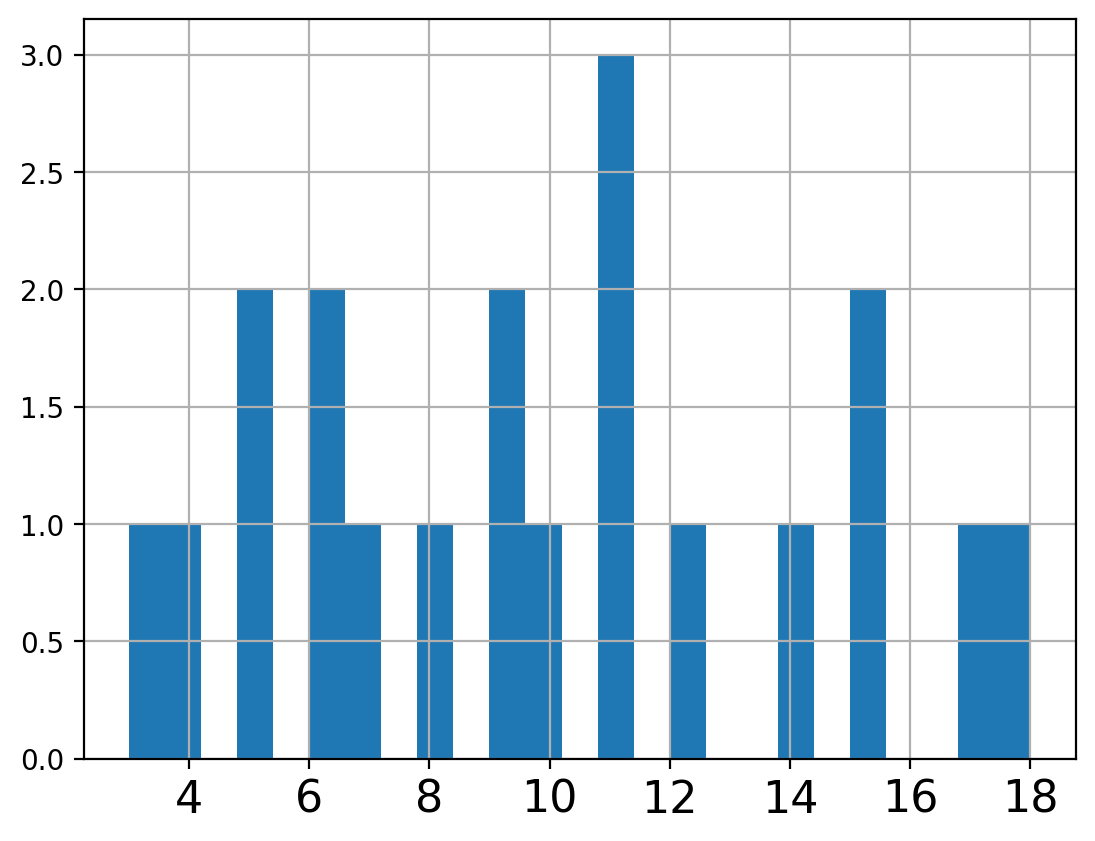
counts.mean()
9.8
To standardize to zero mean and unit standard deviation, we can use tools from the scikit-learn library.
(We will discuss scikit-learn more in upcoming lectures.)
from sklearn import preprocessing
counts_scaled = pd.DataFrame(preprocessing.scale(counts))
counts_scaled.hist(bins=25,xlabelsize=16);
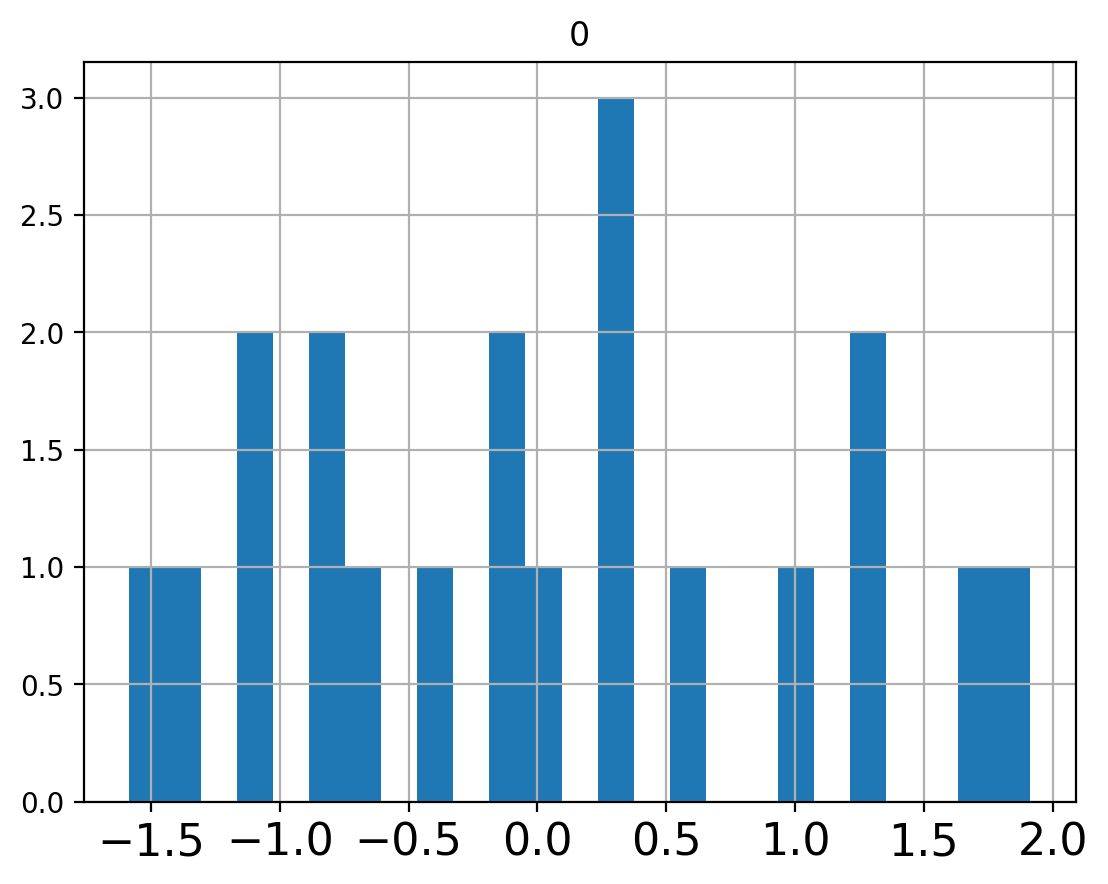
counts_scaled.mean().values
array([-1.33226763e-16])
Notice that values that used to be zero have now become negative.
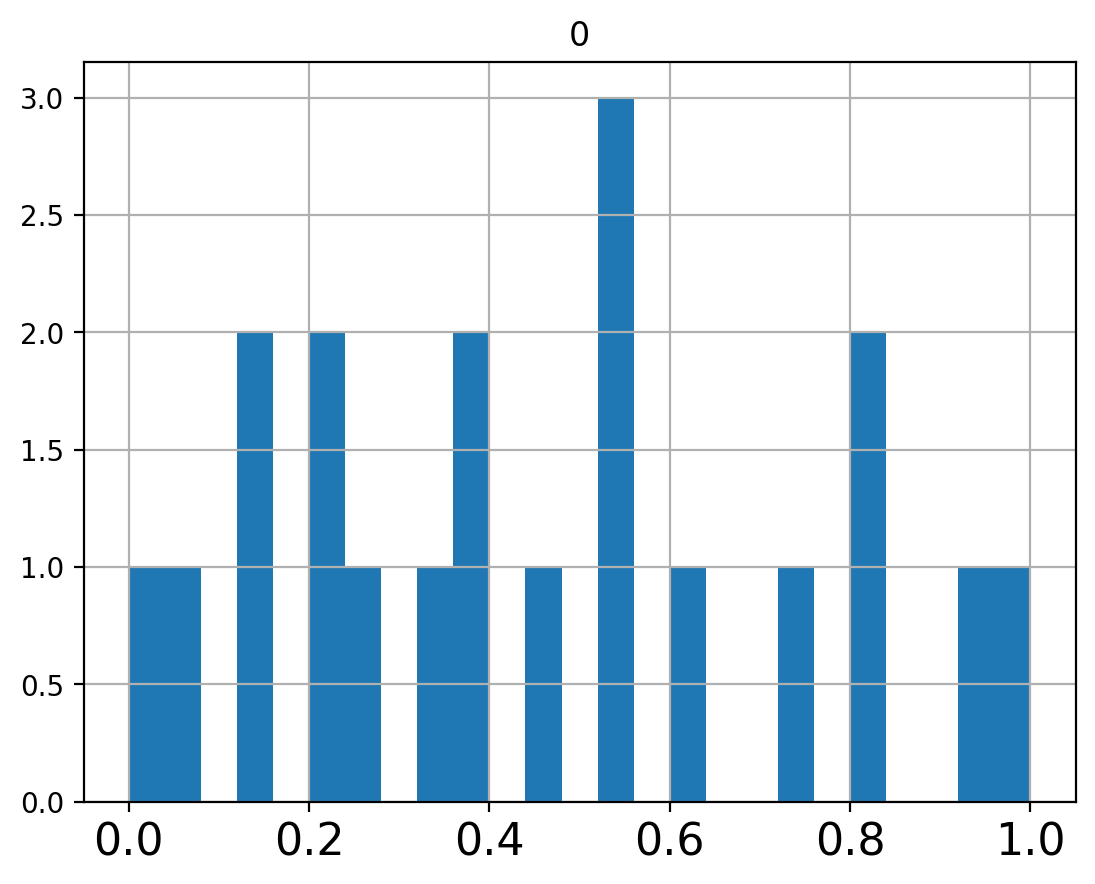
In some situations it may not be sensible to change zeros into something else. It may make more sense to map all values into a fixed range, for example \([0, 1]\).
min_max_scaler = preprocessing.MinMaxScaler()
counts_minmax = min_max_scaler.fit_transform(counts.values.reshape(-1,1))
counts_minmax = pd.DataFrame(counts_minmax)
counts_minmax.hist(bins=25,xlabelsize=16);
Example Application of k-means.
Here is a simple example of how \(k\)-means can be used for data compression.
Consider the following image. Each color in the image is represented by an integer. Typically we might use 24 bits for each integer (8 bits for R, G, and B).

Now cluster the pixels by their color value, and replace each pixel by its cluster center.
Because there are a smaller number of colors used, we can use fewer bits for each pixel.
Here, we use 4 bits (16 colors) for a compression ratio around 6\(\times\).

Here, we use 3 bits (8 colors) for a compression ratio around 8\(\times\).

Here, we use 2 bits (4 colors) for a compression ratio around 12\(\times\).

Finally, we use 1 bit (2 colors) for a compression ratio around 24\(\times\).
